K-Nearest Neighbor(KNN) Algorithm
Last Updated :
25 Jan, 2024
The K-Nearest Neighbors (KNN) algorithm is a supervised machine learning method employed to tackle classification and regression problems. Evelyn Fix and Joseph Hodges developed this algorithm in 1951, which was subsequently expanded by Thomas Cover. The article explores the fundamentals, workings, and implementation of the KNN algorithm.
What is the K-Nearest Neighbors Algorithm?
KNN is one of the most basic yet essential classification algorithms in machine learning. It belongs to the supervised learning domain and finds intense application in pattern recognition, data mining, and intrusion detection.
It is widely disposable in real-life scenarios since it is non-parametric, meaning it does not make any underlying assumptions about the distribution of data (as opposed to other algorithms such as GMM, which assume a Gaussian distribution of the given data). We are given some prior data (also called training data), which classifies coordinates into groups identified by an attribute.
As an example, consider the following table of data points containing two features:
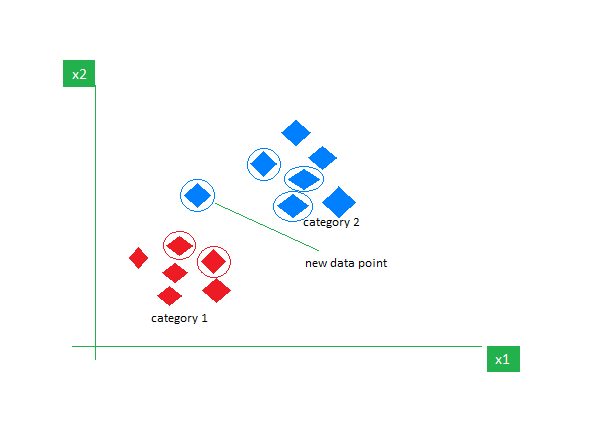
KNN Algorithm working visualization
Now, given another set of data points (also called testing data), allocate these points to a group by analyzing the training set. Note that the unclassified points are marked as ‘White’.
Intuition Behind KNN Algorithm
If we plot these points on a graph, we may be able to locate some clusters or groups. Now, given an unclassified point, we can assign it to a group by observing what group its nearest neighbors belong to. This means a point close to a cluster of points classified as ‘Red’ has a higher probability of getting classified as ‘Red’.
Intuitively, we can see that the first point (2.5, 7) should be classified as ‘Green’, and the second point (5.5, 4.5) should be classified as ‘Red’.
Why do we need a KNN algorithm?
(K-NN) algorithm is a versatile and widely used machine learning algorithm that is primarily used for its simplicity and ease of implementation. It does not require any assumptions about the underlying data distribution. It can also handle both numerical and categorical data, making it a flexible choice for various types of datasets in classification and regression tasks. It is a non-parametric method that makes predictions based on the similarity of data points in a given dataset. K-NN is less sensitive to outliers compared to other algorithms.
The K-NN algorithm works by finding the K nearest neighbors to a given data point based on a distance metric, such as Euclidean distance. The class or value of the data point is then determined by the majority vote or average of the K neighbors. This approach allows the algorithm to adapt to different patterns and make predictions based on the local structure of the data.
Distance Metrics Used in KNN Algorithm
As we know that the KNN algorithm helps us identify the nearest points or the groups for a query point. But to determine the closest groups or the nearest points for a query point we need some metric. For this purpose, we use below distance metrics:
Euclidean Distance
This is nothing but the cartesian distance between the two points which are in the plane/hyperplane. Euclidean distance can also be visualized as the length of the straight line that joins the two points which are into consideration. This metric helps us calculate the net displacement done between the two states of an object.
![\text{distance}(x, X_i) = \sqrt{\sum_{j=1}^{d} (x_j - X_{i_j})^2} ]](https://quicklatex.com/cache3/31/ql_cecb1b0a3631a3bbfe9714eb2732b231_l3.png "Rendered by QuickLaTeX.com")
Manhattan Distance
Manhattan Distance metric is generally used when we are interested in the total distance traveled by the object instead of the displacement. This metric is calculated by summing the absolute difference between the coordinates of the points in n-dimensions.

Minkowski Distance
We can say that the Euclidean, as well as the Manhattan distance, are special cases of the Minkowski distance.

From the formula above we can say that when p = 2 then it is the same as the formula for the Euclidean distance and when p = 1 then we obtain the formula for the Manhattan distance.
The above-discussed metrics are most common while dealing with a Machine Learning problem but there are other distance metrics as well like Hamming Distance which come in handy while dealing with problems that require overlapping comparisons between two vectors whose contents can be Boolean as well as string values.
How to choose the value of k for KNN Algorithm?
The value of k is very crucial in the KNN algorithm to define the number of neighbors in the algorithm. The value of k in the k-nearest neighbors (k-NN) algorithm should be chosen based on the input data. If the input data has more outliers or noise, a higher value of k would be better. It is recommended to choose an odd value for k to avoid ties in classification. Cross-validation methods can help in selecting the best k value for the given dataset.
Workings of KNN algorithm
Thе K-Nearest Neighbors (KNN) algorithm operates on the principle of similarity, where it predicts the label or value of a new data point by considering the labels or values of its K nearest neighbors in the training dataset.
.png)
Step-by-Step explanation of how KNN works is discussed below:
Step 1: Selecting the optimal value of K
- K represents the number of nearest neighbors that needs to be considered while making prediction.
Step 2: Calculating distance
- To measure the similarity between target and training data points, Euclidean distance is used. Distance is calculated between each of the data points in the dataset and target point.
Step 3: Finding Nearest Neighbors
- The k data points with the smallest distances to the target point are the nearest neighbors.
Step 4: Voting for Classification or Taking Average for Regression
- In the classification problem, the class labels of are determined by performing majority voting. The class with the most occurrences among the neighbors becomes the predicted class for the target data point.
- In the regression problem, the class label is calculated by taking average of the target values of K nearest neighbors. The calculated average value becomes the predicted output for the target data point.
Let X be the training dataset with n data points, where each data point is represented by a d-dimensional feature vector  and Y be the corresponding labels or values for each data point in X. Given a new data point x, the algorithm calculates the distance between x and each data point in X using a distance metric, such as Euclidean distance:
and Y be the corresponding labels or values for each data point in X. Given a new data point x, the algorithm calculates the distance between x and each data point in X using a distance metric, such as Euclidean distance:
The algorithm selects the K data points from X that have the shortest distances to x. For classification tasks, the algorithm assigns the label y that is most frequent among the K nearest neighbors to x. For regression tasks, the algorithm calculates the average or weighted average of the values y of the K nearest neighbors and assigns it as the predicted value for x.
Advantages of the KNN Algorithm
- Easy to implement as the complexity of the algorithm is not that high.
- Adapts Easily – As per the working of the KNN algorithm it stores all the data in memory storage and hence whenever a new example or data point is added then the algorithm adjusts itself as per that new example and has its contribution to the future predictions as well.
- Few Hyperparameters – The only parameters which are required in the training of a KNN algorithm are the value of k and the choice of the distance metric which we would like to choose from our evaluation metric.
Disadvantages of the KNN Algorithm
- Does not scale – As we have heard about this that the KNN algorithm is also considered a Lazy Algorithm. The main significance of this term is that this takes lots of computing power as well as data storage. This makes this algorithm both time-consuming and resource exhausting.
- Curse of Dimensionality – There is a term known as the peaking phenomenon according to this the KNN algorithm is affected by the curse of dimensionality which implies the algorithm faces a hard time classifying the data points properly when the dimensionality is too high.
- Prone to Overfitting – As the algorithm is affected due to the curse of dimensionality it is prone to the problem of overfitting as well. Hence generally feature selection as well as dimensionality reduction techniques are applied to deal with this problem.
Example Program:
Assume 0 and 1 as the two classifiers (groups).
C++
#include <bits/stdc++.h>
using namespace std;
struct Point
{
int val;
double x, y;
double distance;
};
bool comparison(Point a, Point b)
{
return (a.distance < b.distance);
}
int classifyAPoint(Point arr[], int n, int k, Point p)
{
for (int i = 0; i < n; i++)
arr[i].distance =
sqrt((arr[i].x - p.x) * (arr[i].x - p.x) +
(arr[i].y - p.y) * (arr[i].y - p.y));
sort(arr, arr+n, comparison);
int freq1 = 0;
int freq2 = 0;
for (int i = 0; i < k; i++)
{
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
return (freq1 > freq2 ? 0 : 1);
}
int main()
{
int n = 17;
Point arr[n];
arr[0].x = 1;
arr[0].y = 12;
arr[0].val = 0;
arr[1].x = 2;
arr[1].y = 5;
arr[1].val = 0;
arr[2].x = 5;
arr[2].y = 3;
arr[2].val = 1;
arr[3].x = 3;
arr[3].y = 2;
arr[3].val = 1;
arr[4].x = 3;
arr[4].y = 6;
arr[4].val = 0;
arr[5].x = 1.5;
arr[5].y = 9;
arr[5].val = 1;
arr[6].x = 7;
arr[6].y = 2;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 3.8;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 10;
arr[9].val = 0;
arr[10].x = 5.6;
arr[10].y = 4;
arr[10].val = 1;
arr[11].x = 4;
arr[11].y = 2;
arr[11].val = 1;
arr[12].x = 3.5;
arr[12].y = 8;
arr[12].val = 0;
arr[13].x = 2;
arr[13].y = 11;
arr[13].val = 0;
arr[14].x = 2;
arr[14].y = 5;
arr[14].val = 1;
arr[15].x = 2;
arr[15].y = 9;
arr[15].val = 0;
arr[16].x = 1;
arr[16].y = 7;
arr[16].val = 0;
Point p;
p.x = 2.5;
p.y = 7;
int k = 3;
printf ("The value classified to unknown point"
" is %d.\n", classifyAPoint(arr, n, k, p));
return 0;
}
|
Java
import java.io.*;
import java.util.*;
class GFG {
static class Point {
int val;
double x, y;
double distance;
}
static class comparison implements Comparator<Point> {
public int compare(Point a, Point b)
{
if (a.distance < b.distance)
return -1;
else if (a.distance > b.distance)
return 1;
return 0;
}
}
static int classifyAPoint(Point arr[], int n, int k,
Point p)
{
for (int i = 0; i < n; i++)
arr[i].distance = Math.sqrt(
(arr[i].x - p.x) * (arr[i].x - p.x)
+ (arr[i].y - p.y) * (arr[i].y - p.y));
Arrays.sort(arr, new comparison());
int freq1 = 0;
int freq2 = 0;
for (int i = 0; i < k; i++) {
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
return (freq1 > freq2 ? 0 : 1);
}
public static void main(String[] args)
{
int n = 17;
Point[] arr = new Point[n];
for (int i = 0; i < 17; i++) {
arr[i] = new Point();
}
arr[0].x = 1;
arr[0].y = 12;
arr[0].val = 0;
arr[1].x = 2;
arr[1].y = 5;
arr[1].val = 0;
arr[2].x = 5;
arr[2].y = 3;
arr[2].val = 1;
arr[3].x = 3;
arr[3].y = 2;
arr[3].val = 1;
arr[4].x = 3;
arr[4].y = 6;
arr[4].val = 0;
arr[5].x = 1.5;
arr[5].y = 9;
arr[5].val = 1;
arr[6].x = 7;
arr[6].y = 2;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 3.8;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 10;
arr[9].val = 0;
arr[10].x = 5.6;
arr[10].y = 4;
arr[10].val = 1;
arr[11].x = 4;
arr[11].y = 2;
arr[11].val = 1;
arr[12].x = 3.5;
arr[12].y = 8;
arr[12].val = 0;
arr[13].x = 2;
arr[13].y = 11;
arr[13].val = 0;
arr[14].x = 2;
arr[14].y = 5;
arr[14].val = 1;
arr[15].x = 2;
arr[15].y = 9;
arr[15].val = 0;
arr[16].x = 1;
arr[16].y = 7;
arr[16].val = 0;
Point p = new Point();
p.x = 2.5;
p.y = 7;
int k = 3;
System.out.println(
"The value classified to unknown point is "
+ classifyAPoint(arr, n, k, p));
}
}
|
Python3
import math
def classifyAPoint(points,p,k=3):
distance=[]
for group in points:
for feature in points[group]:
euclidean_distance = math.sqrt((feature[0]-p[0])**2 +(feature[1]-p[1])**2)
distance.append((euclidean_distance,group))
distance = sorted(distance)[:k]
freq1 = 0
freq2 = 0
for d in distance:
if d[1] == 0:
freq1 += 1
elif d[1] == 1:
freq2 += 1
return 0 if freq1>freq2 else 1
def main():
points = {0:[(1,12),(2,5),(3,6),(3,10),(3.5,8),(2,11),(2,9),(1,7)],
1:[(5,3),(3,2),(1.5,9),(7,2),(6,1),(3.8,1),(5.6,4),(4,2),(2,5)]}
p = (2.5,7)
k = 3
print("The value classified to unknown point is: {}".\
format(classifyAPoint(points,p,k)))
if __name__ == '__main__':
main()
|
C#
using System;
using System.Collections;
using System.Collections.Generic;
using System.Linq;
class Point {
public int val;
public double x, y;
public int distance;
}
class HelloWorld {
public static int classifyAPoint(List<Point> arr, int n, int k, Point p)
{
for (int i = 0; i < n; i++)
arr[i].distance = (int)Math.Sqrt((arr[i].x - p.x) * (arr[i].x - p.x) + (arr[i].y - p.y) * (arr[i].y - p.y));
arr.Sort(delegate(Point x, Point y) {
return x.distance.CompareTo(y.distance);
});
int freq1 = 0;
int freq2 = 0;
for (int i = 0; i < k; i++) {
if (arr[i].val == 0)
freq1++;
else if (arr[i].val == 1)
freq2++;
}
return (freq1 > freq2 ? 0 : 1);
}
static void Main() {
int n = 17;
List<Point> arr = new List<Point>();
for(int i = 0; i < n; i++){
arr.Add(new Point());
}
arr[0].x = 1;
arr[0].y = 12;
arr[0].val = 0;
arr[1].x = 2;
arr[1].y = 5;
arr[1].val = 0;
arr[2].x = 5;
arr[2].y = 3;
arr[2].val = 1;
arr[3].x = 3;
arr[3].y = 2;
arr[3].val = 1;
arr[4].x = 3;
arr[4].y = 6;
arr[4].val = 0;
arr[5].x = 1.5;
arr[5].y = 9;
arr[5].val = 1;
arr[6].x = 7;
arr[6].y = 2;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 3.8;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 10;
arr[9].val = 0;
arr[10].x = 5.6;
arr[10].y = 4;
arr[10].val = 1;
arr[11].x = 4;
arr[11].y = 2;
arr[11].val = 1;
arr[12].x = 3.5;
arr[12].y = 8;
arr[12].val = 0;
arr[13].x = 2;
arr[13].y = 11;
arr[13].val = 0;
arr[14].x = 2;
arr[14].y = 5;
arr[14].val = 1;
arr[15].x = 2;
arr[15].y = 9;
arr[15].val = 0;
arr[16].x = 1;
arr[16].y = 7;
arr[16].val = 0;
Point p = new Point();
p.x = 2.5;
p.y = 7;
int k = 3;
Console.WriteLine("The value classified to unknown point is " + classifyAPoint(arr, n, k, p));
}
}
|
Javascript
class Point {
constructor(val, x, y, distance) {
this.val = val;
this.x = x;
this.y = y;
this.distance = distance;
}
}
class Comparison {
compare(a, b) {
if (a.distance < b.distance) {
return -1;
} else if (a.distance > b.distance) {
return 1;
}
return 0;
}
}
function classifyAPoint(arr, n, k, p) {
for (let i = 0; i < n; i++) {
arr[i].distance = Math.sqrt((arr[i].x - p.x) * (arr[i].x - p.x) + (arr[i].y - p.y) * (arr[i].y - p.y));
}
arr.sort(new Comparison());
let freq1 = 0;
let freq2 = 0;
for (let i = 0; i < k; i++) {
if (arr[i].val === 0) {
freq1++;
} else if (arr[i].val === 1) {
freq2++;
}
}
return freq1 > freq2 ? 0 : 1;
}
const n = 17;
const arr = new Array(n);
for (let i = 0; i < 17; i++) {
arr[i] = new Point();
}
arr[0].x = 1;
arr[0].y = 12;
arr[0].val = 0;
arr[1].x = 2;
arr[1].y = 5;
arr[1].val = 0;
arr[2].x = 5;
arr[2].y = 3;
arr[2].val = 1;
arr[3].x = 3;
arr[3].y = 2;
arr[3].val = 1;
arr[4].x = 3;
arr[4].y = 6;
arr[4].val = 0;
arr[5].x = 1.5;
arr[5].y = 9;
arr[5].val = 1;
arr[6].x = 7;
arr[6].y = 2;
arr[6].val = 1;
arr[7].x = 6;
arr[7].y = 1;
arr[7].val = 1;
arr[8].x = 3.8;
arr[8].y = 3;
arr[8].val = 1;
arr[9].x = 3;
arr[9].y = 10;
arr[9].val = 0;
arr[10].x = 5.6;
arr[10].y = 4;
arr[10].val = 1;
arr[11].x = 4
arr[11].y = 2;
arr[11].val = 1;
arr[12].x = 3.5;
arr[12].y = 8;
arr[12].val = 0;
arr[13].x = 2;
arr[13].y = 11;
arr[13].val = 0;
arr[14].x = 2;
arr[14].y = 5;
arr[14].val = 1;
arr[15].x = 2;
arr[15].y = 9;
arr[15].val = 0;
arr[16].x = 1;
arr[16].y = 7;
arr[16].val = 0;
let p = {
x: 2.5,
y: 7,
val: -1,
};
let k = 3;
console.log(
"The value classified to unknown point is " +
classifyAPoint(arr, n, k, p)
);
function classifyAPoint(arr, n, k, p) {
for (let i = 0; i < n; i++) {
arr[i].distance = Math.sqrt(
(arr[i].x - p.x) * (arr[i].x - p.x) + (arr[i].y - p.y) * (arr[i].y - p.y)
);
}
arr.sort(function (a, b) {
if (a.distance < b.distance) return -1;
else if (a.distance > b.distance) return 1;
return 0;
});
let freq1 = 0;
let freq2 = 0;
for (let i = 0; i < k; i++) {
if (arr[i].val == 0) freq1++;
else if (arr[i].val == 1) freq2++;
}
return freq1 > freq2 ? 0 : 1;
}
|
Output:
The value classified as an unknown point is 0.
Time Complexity: O(N * logN)
Auxiliary Space: O(1)
Applications of the KNN Algorithm
- Data Preprocessing – While dealing with any Machine Learning problem we first perform the EDA part in which if we find that the data contains missing values then there are multiple imputation methods are available as well. One of such method is KNN Imputer which is quite effective ad generally used for sophisticated imputation methodologies.
- Pattern Recognition – KNN algorithms work very well if you have trained a KNN algorithm using the MNIST dataset and then performed the evaluation process then you must have come across the fact that the accuracy is too high.
- Recommendation Engines – The main task which is performed by a KNN algorithm is to assign a new query point to a pre-existed group that has been created using a huge corpus of datasets. This is exactly what is required in the recommender systems to assign each user to a particular group and then provide them recommendations based on that group’s preferences.
Also Check:
Frequently Asked Questions (FAQs)
Q. Why KNN is lazy learner?
KNN algorithm does not build a model during the training phase. The algorithm memories the entire training dataset and performs action on the dataset at the time of classification.
Q. Why KNN is nonparametric?
The KNN algorithm does not make assumptions about the data it is analyzing.
Q. What is the difference between KNN, and K means?
- KNN is a supervised machine learning model used for classification problems whereas K-means is an unsupervised machine learning model used for clustering.
- The “K” in KNN is the number of nearest neighbors whereas the “K” in K means is the number of clusters.
Share your thoughts in the comments
Please Login to comment...