k-nearest neighbor algorithm in Python
Last Updated :
11 Jan, 2023
Supervised Learning :
It is the learning where the value or result that we want to predict is within the training data (labeled data) and the value which is in data that we want to study is known as Target or Dependent Variable or Response Variable.
All the other columns in the dataset are known as the Feature or Predictor Variable or Independent Variable.
Supervised Learning is classified into two categories:
- Classification: Here our target variable consists of the categories.
- Regression: Here our target variable is continuous and we usually try to find out the line of the curve.
As we have understood that to carry out supervised learning we need labeled data. How we can get labeled data? There are various ways to get labeled data:
- Historical labeled Data
- Experiment to get data: We can perform experiments to generate labeled data like A/B Testing.
- Crowd-sourcing
Now it’s time to understand algorithms that can be used to solve supervised machine learning problem. In this post, we will be using popular scikit-learn package.
Note: There are few other packages as well like TensorFlow, Keras etc to perform supervised learning.
k-nearest neighbor algorithm:
This algorithm is used to solve the classification model problems. K-nearest neighbor or K-NN algorithm basically creates an imaginary boundary to classify the data. When new data points come in, the algorithm will try to predict that to the nearest of the boundary line.
Therefore, larger k value means smother curves of separation resulting in less complex models. Whereas, smaller k value tends to overfit the data and resulting in complex models.
Note: It’s very important to have the right k-value when analyzing the dataset to avoid overfitting and underfitting of the dataset.
Using the k-nearest neighbor algorithm we fit the historical data (or train the model) and predict the future.
Example of the k-nearest neighbor algorithm
Python3
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
irisData = load_iris()
X = irisData.data
y = irisData.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(X_train, y_train)
print(knn.predict(X_test))
|
In the example shown above following steps are performed:
- The k-nearest neighbor algorithm is imported from the scikit-learn package.
- Create feature and target variables.
- Split data into training and test data.
- Generate a k-NN model using neighbors value.
- Train or fit the data into the model.
- Predict the future.
We have seen how we can use K-NN algorithm to solve the supervised machine learning problem. But how to measure the accuracy of the model?
Consider an example shown below where we predicted the performance of the above model:
Python3
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
irisData = load_iris()
X = irisData.data
y = irisData.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state=42)
knn = KNeighborsClassifier(n_neighbors=7)
knn.fit(X_train, y_train)
print(knn.score(X_test, y_test))
|
Model Accuracy:
So far so good. But how to decide the right k-value for the dataset? Obviously, we need to be familiar to data to get the range of expected k-value, but to get the exact k-value we need to test the model for each and every expected k-value. Refer to the example shown below.
Python3
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
irisData = load_iris()
X = irisData.data
y = irisData.target
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size = 0.2, random_state=42)
neighbors = np.arange(1, 9)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
train_accuracy[i] = knn.score(X_train, y_train)
test_accuracy[i] = knn.score(X_test, y_test)
plt.plot(neighbors, test_accuracy, label = 'Testing dataset Accuracy')
plt.plot(neighbors, train_accuracy, label = 'Training dataset Accuracy')
plt.legend()
plt.xlabel('n_neighbors')
plt.ylabel('Accuracy')
plt.show()
|
Output:
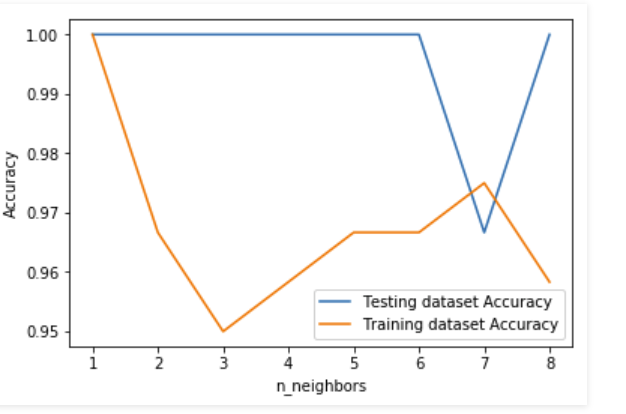
Here in the example shown above, we are creating a plot to see the k-value for which we have high accuracy.
Note: This is a technique which is not used industry-wide to choose the correct value of n_neighbors. Instead, we do hyperparameter tuning to choose the value that gives the best performance. We will be covering this in future posts.
Summary –
In this post, we have understood what supervised learning is and what are its categories. After having a basic understanding of Supervised learning we explored the k-nearest neighbor algorithm which is used to solve supervised machine learning problems. We also explored measuring the accuracy of the model.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...