How to Check if Time Series Data is Stationary with Python?
Last Updated :
13 Jan, 2022
Time series data are generally characterized by their temporal nature. This temporal nature adds a trend or seasonality to the data that makes it compatible for time series analysis and forecasting. Time-series data is said to be stationary if it doesn’t change with time or if they don’t have a temporal structure. So, it is highly necessary to check if the data is stationary. In time series forecasting, we cannot derive valuable insights from data if it is stationary.
Example plot of stationary data:
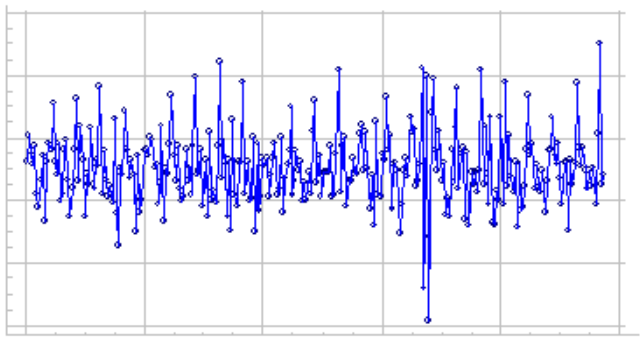
Types of stationarity:
When it comes to identifying if the data is stationary, it means identifying the fine-grained notions of stationarity in the data. The types of stationarity observed in time series data include
- Trend Stationary – A time series that does not show a trend.
- Seasonal Stationary – A time series that does not show seasonal changes.
- Strictly Stationary – The joint distribution of observations is invariant to time shift.
Stepwise Implementation
The following steps will let the user easily understand the method to check the given time series data is stationary.
Step 1: Plotting the time series data
Click here to download the practice dataset daily-female-births-IN.csv.
Python3
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("daily-total-female-births-IN.csv",
header=0, index_col=0)
plt.plot(data)
|
Output:
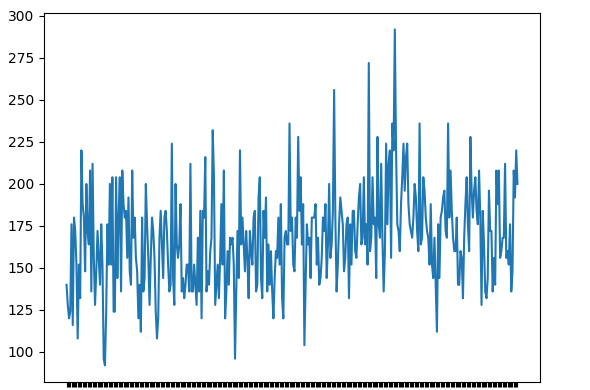
Step 2: Evaluating the descriptive statistics
This is usually done by splitting the data into two or more partitions and calculating the mean and variance for each group. If these first-order moments are consistent among these partitions, then we can assume that the data is stationary. Let’s use airlines passenger count data set between 1949 – 1960.
Click here to download the practice dataset AirPassengers.csv.
Python3
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("AirPassengers.csv",
header=0, index_col=0)
print(data.head(10))
plt.plot(data)
|
Output:
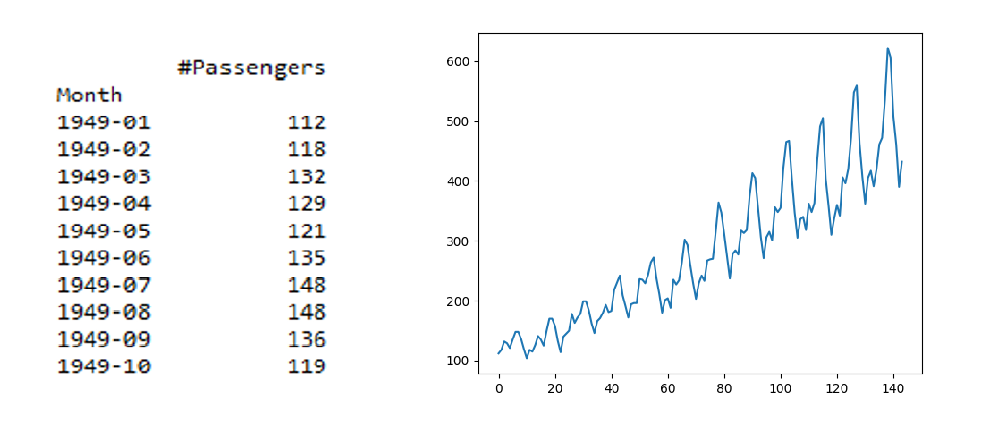
Now, let’s partition this data into different groups and calculate the mean and variance of different groups and check for consistency.
Python3
import pandas as pd
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
values = data.values
parts = int(len(values)/3)
part_1, part_2, part_3 = values[0:parts], values[parts:(
parts*2)], values[(parts*2):(parts*3)]
mean_1, mean_2, mean_3 = part_1.mean(), part_2.mean(), part_3.mean()
var_1, var_2, var_3 = part_1.var(), part_2.var(), part_3.var()
print('mean1=%f, mean2=%f, mean2=%f' % (mean_1, mean_2, mean_3))
print('variance1=%f, variance2=%f, variance2=%f' % (var_1, var_2, var_3))
|
Output:

The output clearly implies that the mean and variance of the three groups are considerably different from each other describing the data is non-stationary. Say for example if the means where mean_1 = 150, mean_2 = 160, mean_3 = 155 and variance_1 = 33, variance_2 = 35, variance_3 = 37, then we can conclude that the data is stationary. Sometimes this method can fail for some distributions, like log-norm distributions.
Let’s try the same example as above but take the log of the passengers’ count using NumPy’s log() function and check the results.
Python3
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
values = log(data.values)
print(values[0:15])
plt.plot(values)
|
Output:
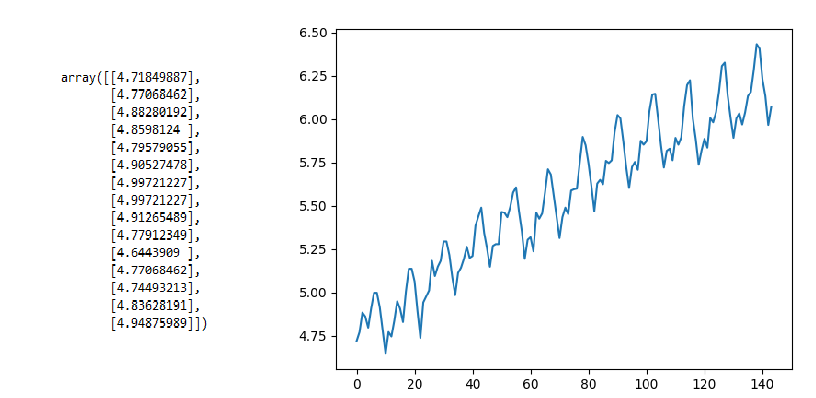
The output signifies there is some trend but not very steep as the previous case, now let’s compute the partition mean and variance.
Python3
parts = int(len(values)/3)
part_1, part_2, part_3 = values[0:parts], values[parts:(parts*2)], values[(parts*2):(parts*3)]
mean_1, mean_2, mean_3 = part_1.mean(), part_2.mean(), part_3.mean()
var_1, var_2, var_3 = part_1.var(), part_2.var(), part_3.var()
print('mean1=%f, mean2=%f, mean2=%f' % (mean_1, mean_2, mean_3))
print('variance1=%f, variance2=%f, variance2=%f' % (var_1, var_2, var_3))
|
Output:
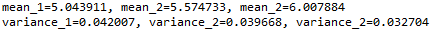
Ideally, we would have expected the mean and variance to be very different but they are the same, in such cases, this method can terribly fail. In order to avoid this, we have another statistical test which is discussed below.
Step 3: Augmented Dickey-Fuller test
This is a statistical test that is dedicatedly built to test whether univariate time series data is stationary or not. This test is based on a hypothesis and can tell us the degree of probability to which it can be accepted. It is often classified under one of the unit root tests, It determines how strongly, a univariate time series data follows a trend. Let’s define the null and alternate hypotheses,
- Ho (Null Hypothesis): The time series data is non-stationary
- H1 (alternate Hypothesis): The time series data is stationary
Assume alpha = 0.05, meaning (95% confidence). The test results are interpreted with a p-value if p > 0.05 fails to reject the null hypothesis, else if p <= 0.05 reject the null hypothesis. Now, let’s use the same air passengers dataset and test it using adfuller() statistical function provided by the stats model package, to check whether the data is stationary or not.
Python3
import pandas as pd
from statsmodels.tsa.stattools import adfuller
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
values = data.values
res = adfuller(values)
print('Augmneted Dickey_fuller Statistic: %f' % res[0])
print('p-value: %f' % res[1])
print('critical values at different levels:')
for k, v in res[4].items():
print('\t%s: %.3f' % (k, v))
|
Output:
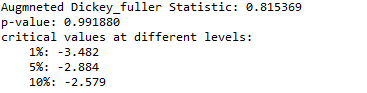
As per our hypothesis, the ADF statistic is much greater than the critical values at different levels, and also the p-value is also greater than 0.05 which signifies, we can fail to reject the null hypothesis at 90%, 95%, and 99% confidence, meaning the time series data is strongly non-stationary.
Now, let’s try running the ADF test to the log normed values and cross-check our results.
Python3
import pandas as pd
from statsmodels.tsa.stattools import adfuller
import numpy as np
data = pd.read_csv("AirPassengers.csv", header=0, index_col=0)
values = log(data.values)
res = adfuller(values)
print('Augmneted Dickey_fuller Statistic: %f' % res[0])
print('p-value: %f' % res[1])
print('critical values at different levels:')
for k, v in res[4].items():
print('\t%s: %.3f' % (k, v))
|
Output:

As you can see, the ADF test one more times shows that the ADF statistic is much greater than the critical values at different levels, and also the p-value is much greater than 0.05 which signifies, we can fail to reject the null hypothesis at 90%, 95%, and 99% confidence, meaning the time series data is strongly non-stationary.
Hence, the ADF unit root test stands out to be a robust test to check whether a time series data is stationary or not.
Share your thoughts in the comments
Please Login to comment...