Very Long Instruction Word (VLIW) Architecture
Last Updated :
20 Apr, 2023
The limitations of the Superscalar processor are prominent as the difficulty of scheduling instruction becomes complex. The intrinsic parallelism in the instruction stream, complexity, cost, and the branch instruction issue get resolved by a higher instruction set architecture called the Very Long Instruction Word (VLIW) or VLIW Machines. VLIW uses Instruction Level Parallelism, i.e. it has programs to control the parallel execution of the instructions.
In other architectures, the performance of the processor is improved by using either of the following methods: pipelining (break the instruction into subparts), superscalar processor (independently execute the instructions in different parts of the processor), out-of-order-execution (execute orders differently to the program) but each of these methods add to the complexity of the hardware very much. VLIW Architecture deals with it by depending on the compiler. The programs decide the parallel flow of the instructions and to resolve conflicts. This increases compiler complexity but decreases hardware complexity by a lot.
Features :
- The processors in this architecture have multiple functional units, fetch from the Instruction cache that have the Very Long Instruction Word.
- Multiple independent operations are grouped together in a single VLIW Instruction. They are initialized in the same clock cycle.
- Each operation is assigned an independent functional unit.
- All the functional units share a common register file.
- Instruction words are typically of the length 64-1024 bits depending on the number of execution unit and the code length required to control each unit.
- Instruction scheduling and parallel dispatch of the word is done statically by the compiler.
- The compiler checks for dependencies before scheduling parallel execution of the instructions.
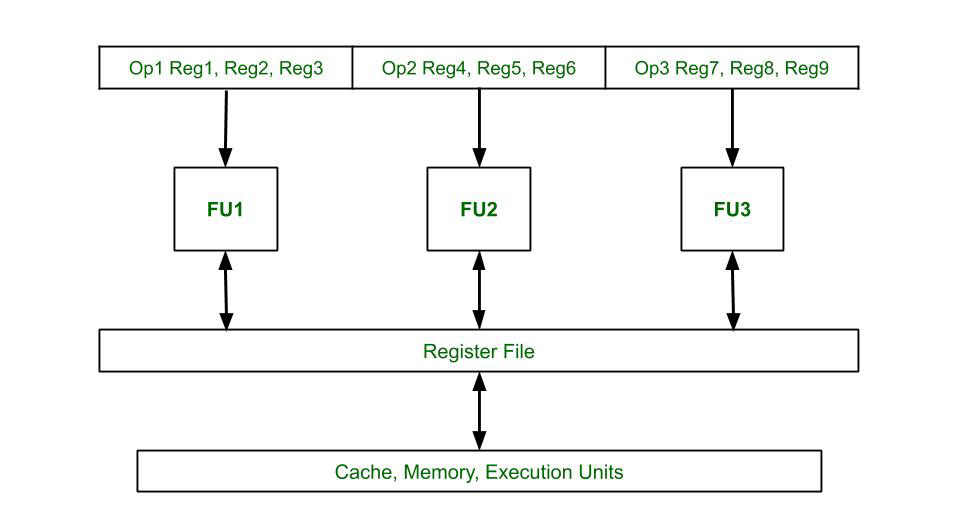
Block Diagram of VLIW Architecture

Time Space Diagram of VLIW Processor where 4 instructions are executed in parallel in a single instruction word
Table: Comparison of VLIW Architecture with Other Architectures
| Architecture |
Advantages |
Disadvantages |
| VLIW |
- Reduces hardware complexity.
- Reduces power consumption.
- Simplifies decoding and instruction issues.
- Increases potential clock rate.
- Functional units are positioned corresponding to the instruction pocket by compiler.
|
- Complex compilers are required.
- Increased program code size.
- Larger memory bandwidth and register-file bandwidth.
- Unscheduled events, for example, a cache miss could lead to a stall that will stall the entire processor.
- In case of un-filled opcodes in a VLIW, there is waste of memory space and instruction bandwidth.
|
| Pipelining |
- Increases instruction throughput.
- Enhances performance by overlapping instruction execution.
- Reduces hardware complexity.
|
- Dependency checking between instructions is required.
- Pipeline hazards and stalls can occur.
|
| Superscalar |
- Improves performance by executing multiple instructions per clock cycle.
- Reduces hardware complexity.
- Enhances instruction throughput.
|
- Dependency checking between instructions is required.
- Out-of-order execution leads to more complexity.
|
| Out-of-order-execution |
- Improves performance by overlapping instruction execution.
- Enhances instruction throughput.
- Reduces hardware complexity.
|
- Complexity increases due to out-of-order execution.
- Dependency checking between instructions is required.
- Register renaming is required to resolve name dependencies.
- Dynamic scheduling is required.
|
Some common applications of VLIW architecture include:
Digital signal processing (DSP): VLIW processors are well-suited for DSP applications because of their ability to perform multiple operations in parallel. DSP applications require high computational power and often involve multiple parallel data streams, which VLIW processors can handle efficiently.
Multimedia processing: VLIW processors are also used for multimedia applications such as video and audio processing, where high throughput and parallelism are required.
Scientific computing: VLIW processors can be used for scientific computing applications, where high-performance computing is required to solve complex numerical problems.
Embedded systems: VLIW processors are used in many embedded systems, such as automotive control systems, medical devices, and industrial automation equipment. These systems require high-performance processors that can execute multiple instructions in parallel while consuming minimal power.
Advantages :
- Reduces hardware complexity.
- Reduces power consumption because of reduction of hardware complexity.
- Since compiler takes care of data dependency check, decoding, instruction issues, it becomes a lot simpler.
- Increases potential clock rate.
- Functional units are positioned corresponding to the instruction pocket by compiler.
Disadvantages :
- Complex compilers are required which are hard to design.
- Increased program code size.
- Larger memory bandwidth and register-file bandwidth.
- Unscheduled events, for example a cache miss could lead to a stall which will stall the entire processor.
- In case of un-filled opcodes in a VLIW, there is waste of memory space and instruction bandwidth.
Share your thoughts in the comments
Please Login to comment...