Computer Organization | Different Instruction Cycles
Last Updated :
19 Apr, 2023
Introduction :
Prerequisite – Execution, Stages and Throughput
Registers Involved In Each Instruction Cycle:
- Memory address registers(MAR) : It is connected to the address lines of the system bus. It specifies the address in memory for a read or write operation.
- Memory Buffer Register(MBR) : It is connected to the data lines of the system bus. It contains the value to be stored in memory or the last value read from the memory.
- Program Counter(PC) : Holds the address of the next instruction to be fetched.
- Instruction Register(IR) : Holds the last instruction fetched.
In computer organization, an instruction cycle, also known as a fetch-decode-execute cycle, is the basic operation performed by a central processing unit (CPU) to execute an instruction. The instruction cycle consists of several steps, each of which performs a specific function in the execution of the instruction. The major steps in the instruction cycle are:
- Fetch: In the fetch cycle, the CPU retrieves the instruction from memory. The instruction is typically stored at the address specified by the program counter (PC). The PC is then incremented to point to the next instruction in memory.
- Decode: In the decode cycle, the CPU interprets the instruction and determines what operation needs to be performed. This involves identifying the opcode and any operands that are needed to execute the instruction.
- Execute: In the execute cycle, the CPU performs the operation specified by the instruction. This may involve reading or writing data from or to memory, performing arithmetic or logic operations on data, or manipulating the control flow of the program.
- There are also some additional steps that may be performed during the instruction cycle, depending on the CPU architecture and instruction set:
- Fetch operands: In some CPUs, the operands needed for an instruction are fetched during a separate cycle before the execute cycle. This is called the fetch operands cycle.
- Store results: In some CPUs, the results of an instruction are stored during a separate cycle after the execute cycle. This is called the store results cycle.
- Interrupt handling: In some CPUs, interrupt handling may occur during any cycle of the instruction cycle. An interrupt is a signal that the CPU receives from an external device or software that requires immediate attention. When an interrupt occurs, the CPU suspends the current instruction and executes an interrupt handler to service the interrupt.
These cycles are the basic building blocks of the CPU’s operation and are performed for every instruction executed by the CPU. By optimizing these cycles, CPU designers can improve the performance and efficiency of the CPU, allowing it to execute instructions faster and more efficiently.
The Instruction Cycle –
Each phase of Instruction Cycle can be decomposed into a sequence of elementary micro-operations. In the above examples, there is one sequence each for the Fetch, Indirect, Execute and Interrupt Cycles.

The Indirect Cycle is always followed by the Execute Cycle. The Interrupt Cycle is always followed by the Fetch Cycle. For both fetch and execute cycles, the next cycle depends on the state of the system.

We assumed a new 2-bit register called Instruction Cycle Code (ICC). The ICC designates the state of processor in terms of which portion of the cycle it is in:-
00 : Fetch Cycle
01 : Indirect Cycle
10 : Execute Cycle
11 : Interrupt Cycle
At the end of the each cycles, the ICC is set appropriately. The above flowchart of Instruction Cycle describes the complete sequence of micro-operations, depending only on the instruction sequence and the interrupt pattern(this is a simplified example). The operation of the processor is described as the performance of a sequence of micro-operation.
Different Instruction Cycles:
- The Fetch Cycle –
At the beginning of the fetch cycle, the address of the next instruction to be executed is in the Program Counter(PC).

- Step 1: The address in the program counter is moved to the memory address register(MAR), as this is the only register which is connected to address lines of the system bus.

- Step 2: The address in MAR is placed on the address bus, now the control unit issues a READ command on the control bus, and the result appears on the data bus and is then copied into the memory buffer register(MBR). Program counter is incremented by one, to get ready for the next instruction. (These two action can be performed simultaneously to save time)
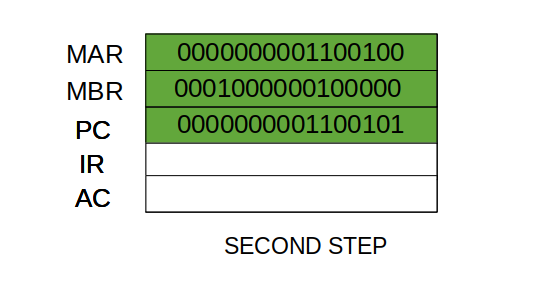
- Step 3: The content of the MBR is moved to the instruction register(IR).

- Thus, a simple Fetch Cycle consist of three steps and four micro-operation. Symbolically, we can write these sequence of events as follows:-
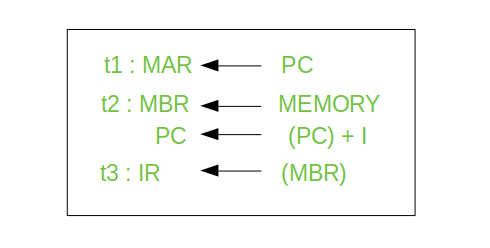
- Here ‘I’ is the instruction length. The notations (t1, t2, t3) represents successive time units. We assume that a clock is available for timing purposes and it emits regularly spaced clock pulses. Each clock pulse defines a time unit. Thus, all time units are of equal duration. Each micro-operation can be performed within the time of a single time unit.
First time unit: Move the contents of the PC to MAR.
Second time unit: Move contents of memory location specified by MAR to MBR. Increment content of PC by I.
Third time unit: Move contents of MBR to IR.
Note: Second and third micro-operations both take place during the second time unit.
- The Indirect Cycles –
Once an instruction is fetched, the next step is to fetch source operands. Source Operand is being fetched by indirect addressing( it can be fetched by any addressing mode, here its done by indirect addressing). Register-based operands need not be fetched. Once the opcode is executed, a similar process may be needed to store the result in main memory. Following micro-operations takes place:-

- Step 1: The address field of the instruction is transferred to the MAR. This is used to fetch the address of the operand.
Step 2: The address field of the IR is updated from the MBR.(So that it now contains a direct addressing rather than indirect addressing)
Step 3: The IR is now in the state, as if indirect addressing has not been occurred.
Note: Now IR is ready for the execute cycle, but it skips that cycle for a moment to consider the Interrupt Cycle .
- The Execute Cycle
The other three cycles(Fetch, Indirect and Interrupt) are simple and predictable. Each of them requires simple, small and fixed sequence of micro-operation. In each case same micro-operation are repeated each time around.
Execute Cycle is different from them. Like, for a machine with N different opcodes there are N different sequence of micro-operations that can occur.
Lets take an hypothetical example :-
consider an add instruction:

- Here, this instruction adds the content of location X to register R. Corresponding micro-operation will be:-


- Here, the content of location X is incremented by 1. If the result is 0, the next instruction will be skipped. Corresponding sequence of micro-operation will be :-

- Here, the PC is incremented if (MBR) = 0. This test (is MBR equal to zero or not) and action (PC is incremented by 1) can be implemented as one micro-operation.
Note : This test and action micro-operation can be performed during the same time unit during which the updated value MBR is stored back to memory.
- The Interrupt Cycle:
At the completion of the Execute Cycle, a test is made to determine whether any enabled interrupt has occurred or not. If an enabled interrupt has occurred then Interrupt Cycle occurs. The nature of this cycle varies greatly from one machine to another.
Lets take a sequence of micro-operation:-

- Step 1: Contents of the PC is transferred to the MBR, so that they can be saved for return.
Step 2: MAR is loaded with the address at which the contents of the PC are to be saved.
PC is loaded with the address of the start of the interrupt-processing routine.
Step 3: MBR, containing the old value of PC, is stored in memory.
Note: In step 2, two actions are implemented as one micro-operation. However, most processor provide multiple types of interrupts, it may take one or more micro-operation to obtain the save_address and the routine_address before they are transferred to the MAR and PC respectively.
Uses of Different Instruction Cycles :
Here are some uses of different instruction cycles:
- Fetch cycle: This cycle retrieves the instruction from memory and loads it into the processor’s instruction register. The fetch cycle is essential for the processor to know what instruction it needs to execute.
- Decode cycle: This cycle decodes the instruction to determine what operation it represents and what operands it requires. The decode cycle is important for the processor to understand what it needs to do with the instruction and what data it needs to retrieve or manipulate.
- Execute cycle: This cycle performs the actual operation specified by the instruction, using the operands specified in the instruction or in other registers. The execute cycle is where the processor performs the actual computation or manipulation of data.
- Store cycle: This cycle stores the result of the operation in memory or in a register. The store cycle is essential for the processor to save the result of the computation or manipulation for future use.
The advantages and disadvantages of the instruction cycle depend on various factors, such as the specific CPU architecture and the instruction set used. However, here are some general advantages and disadvantages of the instruction cycle:
Advantages:
- Standardization: The instruction cycle provides a standard way for CPUs to execute instructions, which allows software developers to write programs that can run on multiple CPU architectures. This standardization also makes it easier for hardware designers to build CPUs that can execute a wide range of instructions.
- Efficiency: By breaking down the instruction execution into multiple steps, the CPU can execute instructions more efficiently. For example, while the CPU is performing the execute cycle for one instruction, it can simultaneously fetch the next instruction.
- Pipelining: The instruction cycle can be pipelined, which means that multiple instructions can be in different stages of execution at the same time. This improves the overall performance of the CPU, as it can process multiple instructions simultaneously.
Disadvantages:
- Overhead: The instruction cycle adds overhead to the execution of instructions, as each instruction must go through multiple stages before it can be executed. This overhead can reduce the overall performance of the CPU.
- Complexity: The instruction cycle can be complex to implement, especially if the CPU architecture and instruction set are complex. This complexity can make it difficult to design, implement, and debug the CPU.
- Limited parallelism: While pipelining can improve the performance of the CPU, it also has limitations. For example, some instructions may depend on the results of previous instructions, which limits the amount of parallelism that can be achieved. This can reduce the effectiveness of pipelining and limit the overall performance of the CPU.
Issues of Different Instruction Cycles :
Here are some common issues associated with different instruction cycles:
- Pipeline hazards: Pipelining is a technique used to overlap the execution of multiple instructions by breaking them into smaller stages. However, pipeline hazards occur when one instruction depends on the completion of a previous instruction, leading to delays and reduced performance.
- Branch prediction errors: Branch prediction is a technique used to anticipate which direction a program will take when encountering a conditional branch instruction. However, if the prediction is incorrect, it can result in wasted cycles and decreased performance.
- Instruction cache misses: Instruction cache is a fast memory used to store frequently used instructions. Instruction cache misses occur when an instruction is not found in the cache and needs to be retrieved from slower memory, resulting in delays and decreased performance.
- Instruction-level parallelism limitations: Instruction-level parallelism is the ability of a processor to execute multiple instructions simultaneously. However, this technique has limitations as not all instructions can be executed in parallel, leading to reduced performance in some cases.
- Resource contention: Resource contention occurs when multiple instructions require the use of the same resource, such as a register or a memory location. This can lead to delays and reduced performance if the processor is unable to resolve the contention efficiently.
Share your thoughts in the comments
Please Login to comment...