Drop rows from the dataframe based on certain condition applied on a column
Last Updated :
04 Dec, 2023
In this post, we are going to discuss several approaches on how to drop rows from the dataframe based on certain conditions applied to a column. Retain all those rows for which the applied condition on the given column evaluates to True.
We have already discussed earlier how to drop rows or columns based on their labels. However, in this post, we are going to discuss several approaches on how to drop rows from the data frame based on certain conditions applied to a column. Retain all those rows for which the applied condition on the given column evaluates to True.
Python Pandas Conditionally Delete Rows
Below are the ways by which we can drop rows from the dataframe based on certain conditions applied on a column, but before that we will create a datframe for reference:
- Create a datframe for reference:
- Using drop()
- Using query()
- Using loc[]
- Using isin()
- Using eval()
To download the CSV (“nba.csv” dataset) used in the code, click here.
Reference: How to drop rows or columns based on their labels
Creating a Dataframe to drop Rows
In this Dataframe, currently, we have 458 rows and 9 columns.
Python3
import pandas as pd
df = pd.read_csv('nba.csv')
print(df.head(15))
|
Output:
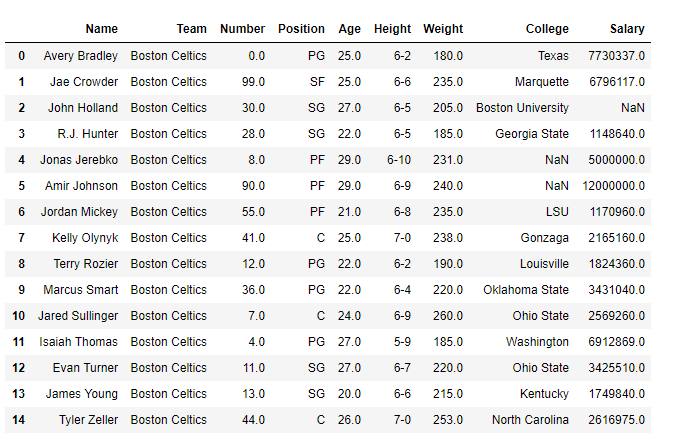
Delete Rows Based on Multiple Conditions on a Column
We will use vectorization to filter out such rows from the dataset which satisfy the applied condition. Let’s use the vectorization operation to filter out all those rows which satisfy the given condition.
Python3
filtered_df = df[df['Age'] >= 25]
print(filtered_df.head(15))
|
Output:
As we can see in the output, the returned Dataframe only contains those players whose age is greater than or equal to 25 years.
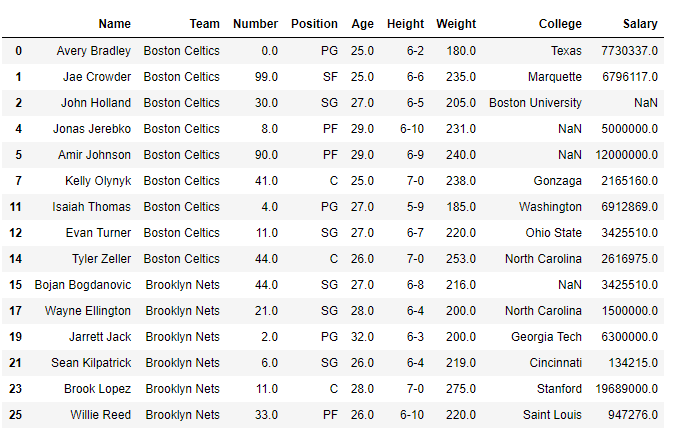
Delete Rows Based on Multiple Conditions on a Column Using drop()
Example 1: As we can see in the output, the returned Dataframe only contains those players whose age is not between 20 to 25 age using df.drop().
Python3
indexAge = df[ (df['Age'] >= 20) & (df['Age'] <= 25) ].index
df.drop(indexAge , inplace=True)
df.head(15)
|
Output
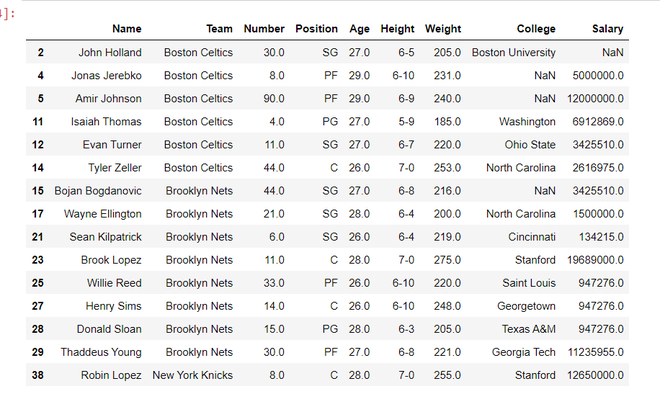
Example 2: Here, we drop all the rows whose names and Positions are associated with ‘John Holland‘ or ‘SG’ using df.drop().
Python3
indexAge = df[(df['Name'] == 'John Holland') | (df['Position'] == 'SG')].index
df.drop(indexAge, inplace=True)
df.head(15)
|
Output
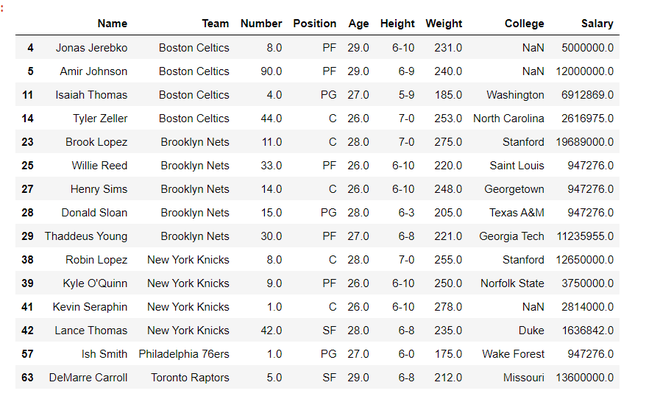
Delete Rows Based on Multiple Conditions on a Column Using query()
In this example, we are using query() function to delete rows based on multiple conditions on a column. Below code creates a DataFrame and filters it to keep only individuals aged 30 or younger using the `query` function. The resulting DataFrame is printed.
Python3
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'Dave'],
'age': [25, 30, 35, 40],
'gender': ['F', 'M', 'M', 'M']}
df = pd.DataFrame(data)
df_new = df.query('age <= 30')
print(df_new)
|
Output
name age gender
0 Alice 25 F
1 Bob 30 M
Delete Rows Based on Multiple Conditions on a Column Using loc
In this example, we are using loc function to delete rows based on multiple conditions on a column. Below code generates a DataFrame and filters it to retain rows where the ‘age’ is 30 or less, displaying the modified DataFrame.
Python3
import pandas as pd
data = {'name': ['Alice', 'Bob', 'Charlie', 'Dave'],
'age': [25, 30, 35, 40],
'gender': ['F', 'M', 'M', 'M']}
df = pd.DataFrame(data)
df_new = df.loc[df['age'] <= 30]
print(df_new)
|
Output
It uses the isin() method to create a boolean mask based on the specified condition and then uses that mask to filter out the rows.
name age gender
0 Alice 25 F
1 Bob 30 M
Delete Rows Based on Multiple Conditions on a Column Using isin()
In this example , we are using isin() method to create a boolean mask based on the specified condition and then uses that mask to filter out the rows. Below code generates a DataFrame with ‘Name,’ ‘Age,’ and ‘Score,’ filters out rows where ‘Score’ is less than 80, and displays the modified DataFrame.
Python3
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'Age': [25, 30, 35, 40, 45],
'Score': [85, 92, 78, 65, 89]}
df = pd.DataFrame(data)
condition = (df['Score'] < 80)
df = df[~condition]
print("DataFrame after deleting rows based on condition:")
print(df)
|
Output :
DataFrame after deleting rows based on condition:
Name Age Score
0 Alice 25 85
1 Bob 30 92
4 Eva 45 89
Delete Rows Based on Multiple Conditions on a Column Using eval()
In this example , we are using the eval() method to evaluate a boolean condition and filter the DataFrame accordingly. The Below code creates a DataFrame, sets a condition where ‘Score’ < 80, and removes corresponding rows, displaying the updated DataFrame.
Python3
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eva'],
'Age': [25, 30, 35, 40, 45],
'Score': [85, 92, 78, 65, 89]}
df = pd.DataFrame(data)
df = df.eval('Score >= 80')
print("DataFrame after deleting rows based on condition:")
print(df)
|
Output :
DataFrame after deleting rows based on condition:
0 True
1 True
2 False
3 False
4 True
dtype: bool
Share your thoughts in the comments
Please Login to comment...