Series and Indexes are equipped with a set of string processing methods that make it easy to operate on each element of the array. Perhaps most importantly, these methods exclude missing/NA values automatically. These are accessed via the str attribute and generally, have names matching the equivalent (scalar) built-in string methods.

Lowercasing and Uppercasing a Data
In order to lowercase a data, we use str.lower() this function converts all uppercase characters to lowercase. If no uppercase characters exist, it returns the original string. In order to uppercase a data, we use str.upper() this function converts all lowercase characters to uppercase. If no lowercase characters exist, it returns the original string.
Code #1:
# Import pandas package
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Delhi', 'Kanpur', 'Allahabad', 'Kannauj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# converting and overwriting values in column
df["Name"]= df["Name"].str.lower()
print(df)
Output :
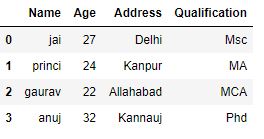
As shown in the output image of the data frame, all values in the name column have been converted into lower case.
In this example, we are using nba.csv file.
Code #2:
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv")
# converting and overwriting values in column
data["Team"]= data["Team"].str.upper()
# display
data
Output :
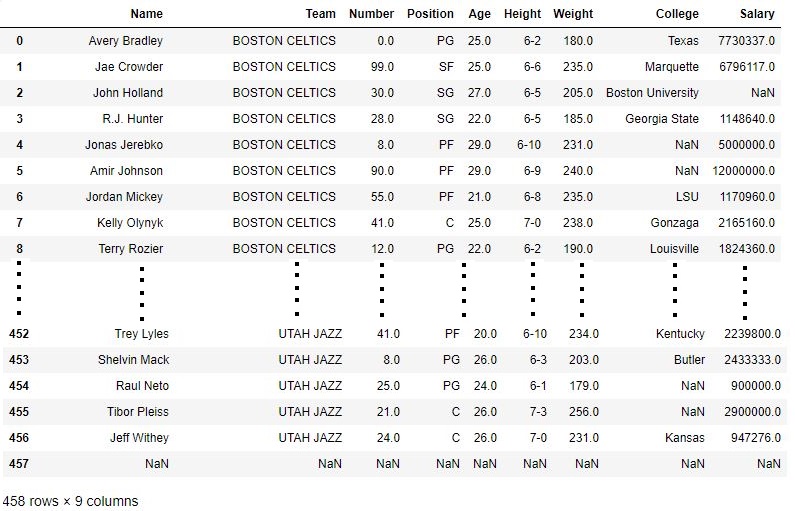
As shown in the output image of data frame, all values in the Team column have been converted into upper case.
Splitting and Replacing a Data
In order to split a data, we use str.split() this function returns a list of strings after breaking the given string by the specified separator but it can only be applied to an individual string. Pandas str.split() method can be applied to a whole series. .str has to be prefixed every time before calling this method to differentiate it from the Python’s default function otherwise, it will throw an error. In order to replace a data, we use str.replace() this function works like Python .replace() method only, but it works on Series too. Before calling .replace() on a Pandas series, .str has to be prefixed in order to differentiate it from the Python’s default replace method.
Code #1
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Knnuaj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# dropping null value columns to avoid errors
df.dropna(inplace = True)
# new data frame with split value columns
df["Address"]= df["Address"].str.split("a", n = 1, expand = True)
# df display
print(df)
Output :
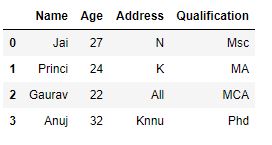
As shown in the output image, the Address column was separated at the first occurrence of “a” and not on the later occurrence since the n parameter was set to 1 (Max 1 separation in a string).
Code #2:
# importing pandas module
import pandas as pd
# reading csv file from url
data = pd.read_csv("nba.csv")
# overwriting column with replaced value of age
data["Age"]= data["Age"].replace(25.0, "Twenty five")
# creating a filter for age column
# where age = "Twenty five"
filter = data["Age"]=="Twenty five"
# printing only filtered columns
data.where(filter).dropna()
Output :
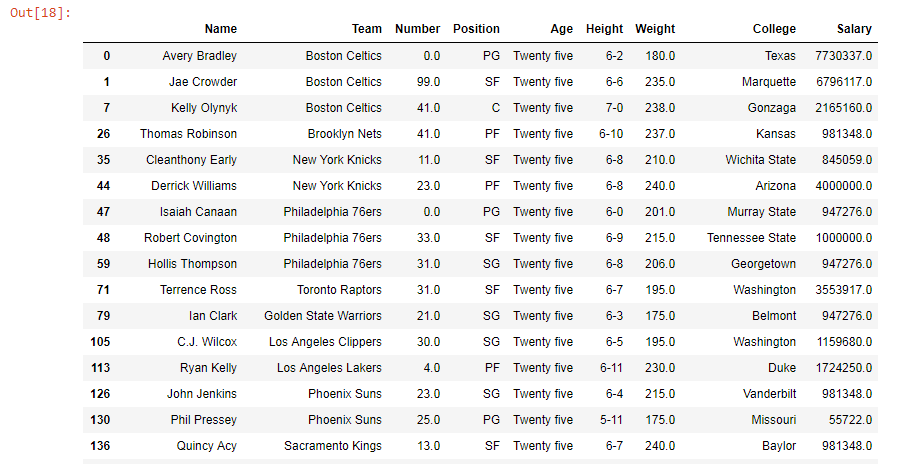
As shown in the output image, all the values in Age column having age=25.0 have been replaced by “Twenty five”.
Concatenation of Data
In order to concatenate a Series or Index, we use str.cat() this function is used to concatenate strings to the passed caller series of string. Distinct values from a different series can be passed but the length of both the series has to be same. .str has to be prefixed to differentiate it from the Python’s default method.
Code #1:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Nagpur', 'Kanpur', 'Allahabad', 'Kannuaj'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# making copy of address column
new = df["Address"].copy()
# concatenating address with name column
# overwriting name column
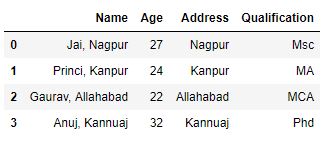
df["Name"]= df["Name"].str.cat(new, sep =", ")
# display
print(df)
Output :
As shown in the output image, every string in the Address column having same index as string in Name column have been concatenated with separator “, “.
Code #2:
# importing pandas module
import pandas as pd
# importing csv from link
data = pd.read_csv("nba.csv")
# making copy of team column
new = data["Team"].copy()
# concatenating team with name column
# overwriting name column
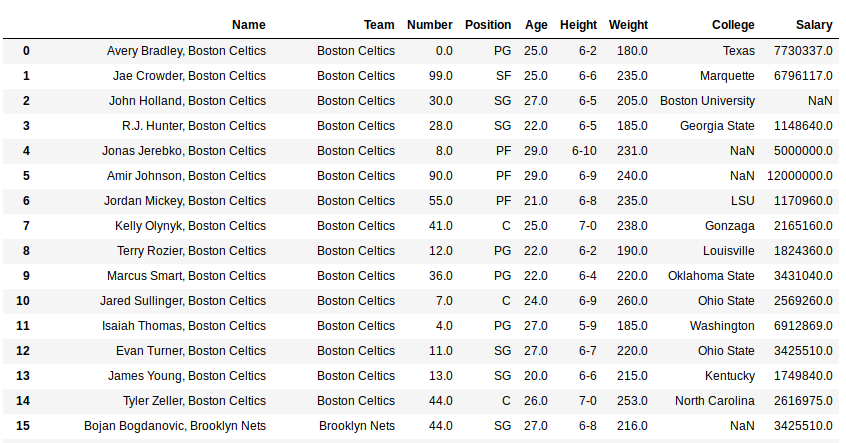
data["Name"]= data["Name"].str.cat(new, sep =", ")
# display
data
Output:
As shown in the output image, every string in the Team column having same index as string in Name column have been concatenated with separator “, “.
Removing Whitespaces of Data
In order to remove a whitespaces, we use str.strip(), str.rstrip(), str.lstrip() these function used to handle white spaces(including New line) in any text data. As it can be seen in the name, str.lstrip() is used to remove spaces from the left side of string, str.rstrip() to remove spaces from right side of the string and str.strip() removes spaces from both sides. Since these are pandas function with same name as Python’s default functions, .str has to be prefixed to tell the compiler that a Pandas function is being called.
Code #1:
# importing pandas module
import pandas as pd
# Define a dictionary containing employee data
data = {'Name':['Jai', 'Princi', 'Gaurav', 'Anuj'],
'Age':[27, 24, 22, 32],
'Address':['Nagpur junction', 'Kanpur junction',
'Nagpur junction', 'Kannuaj junction'],
'Qualification':['Msc', 'MA', 'MCA', 'Phd']}
# Convert the dictionary into DataFrame
df = pd.DataFrame(data)
# replacing address name and adding spaces in start and end
new = df["Address"].replace("Nagpur junction", " Nagpur junction ").copy()
# checking with custom string
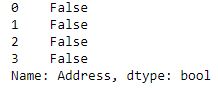
print(new.str.strip()==" Nagpur junction")
print(new.str.strip()=="Nagpur junction ")
print(new.str.strip()==" Nagpur junction ")
Output :
As shown in the output image, the comparison is returning False for all 3 conditions, which means the spaces were successfully removed from both sides and the string is no longer having spaces.
Code #2:
# importing pandas module
import pandas as pd
# making data frame
data = pd.read_csv("nba.csv")
# replacing team name and adding spaces in start and end
new = data["Team"].replace("Boston Celtics", " Boston Celtics ").copy()
# checking with custom removed space string
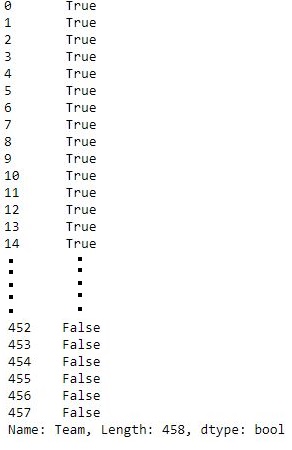
new.str.lstrip()=="Boston Celtics "
Output :
As shown in the output image, the comparison is true after removing the left side spaces
Extracting a Data
In order to extract a data, we use str.extract() this function accepts a regular expression with at least one capture group. Extracting a regular expression with more than one group returns a DataFrame with one column per group. Elements that do not match return a row filled with NaN.
Code #1:
# importing pandas module
import pandas as pd
# creating a series
s = pd.Series(['a1', 'b2', 'c3'])
# Extracting a data
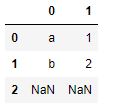
n= s.str.extract(r'([ab])(\d)')
print(n)
Output :
As shown in the output image, that two groups will return a DataFrame with two columns. Non-matches will be NaN.
Code #2:
# importing pandas module
import pandas as pd
# creating a series
s = pd.Series(['a1', 'b2', 'c3'])
# Extracting a data
n = s.str.extract(r'(?P<Geeks>[ab])(?P<For>\d)')
print(n)
Output :
As shown in the output image, that named groups will become column names in the result.

Pandas str methods:
| Function |
Description |
| str.lower() |
Method to convert a string’s characters to lowercase |
| str.upper() |
Method to convert a string’s characters to uppercase |
| str.find() |
Method is used to search a substring in each string present in a series |
| str.rfind() |
Method is used to search a substring in each string present in a series from the Right side |
| str.findall() |
Method is also used to find substrings or separators in each string in a series |
| str.isalpha() |
Method is used to check if all characters in each string in series are alphabetic(a-z/A-Z) |
| str.isdecimal() |
Method is used to check whether all characters in a string are decimal |
| str.title() |
Method to capitalize the first letter of every word in a string |
| str.len() |
Method returns a count of the number of characters in a string |
| str.replace() |
Method replaces a substring within a string with another value that the user provides |
| str.contains() |
Method tests if pattern or regex is contained within a string of a Series or Index |
| str.extract() |
Extract groups from the first match of regular expression pattern. |
| str.startswith() |
Method tests if the start of each string element matches a pattern |
| str.endswith() |
Method tests if the end of each string element matches a pattern |
| str.isdigit() |
Method is used to check if all characters in each string in series are digits |
| str.lstrip() |
Method removes whitespace from the left side (beginning) of a string |
| str.rstrip() |
Method removes whitespace from the right side (end) of a string |
| str.strip() |
Method to remove leading and trailing whitespace from string |
| str.split() |
Method splits a string value, based on an occurrence of a user-specified value |
| str.join() |
Method is used to join all elements in list present in a series with passed delimiter |
| str.cat() |
Method is used to concatenate strings to the passed caller series of string. |
| str.repeat() |
Method is used to repeat string values in the same position of passed series itself |
| str.get() |
Method is used to get element at the passed position |
| str.partition() |
Method splits the string only at the first occurrence unlike str.split() |
| str.rpartition() |
Method splits string only once and that too reversely. It works in a similar way like str.partition() and str.split() |
| str.pad() |
Method to add padding (whitespaces or other characters) to every string element in a series |
| str.swapcase() |
Method to swap case of each string in a series |
Share your thoughts in the comments
Please Login to comment...