Python | Pandas Series.str.find()
Last Updated :
18 Jan, 2023
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas str.find() method is used to search a substring in each string present in a series. If the string is found, it returns the lowest index of its occurrence. If string is not found, it will return -1.
Start and end points can also be passed to search a specific part of string for the passed character or substring.
Syntax: Series.str.find(sub, start=0, end=None)
Parameters:
sub: String or character to be searched in the text value in series
start: int value, start point of searching. Default is 0 which means from the beginning of string
end: int value, end point where the search needs to be stopped. Default is None.
Return type: Series with index position of substring occurrence
To download the CSV used in code, click here.
In the following examples, the data frame used contains data of some NBA players. The image of data frame before any operations is attached below.
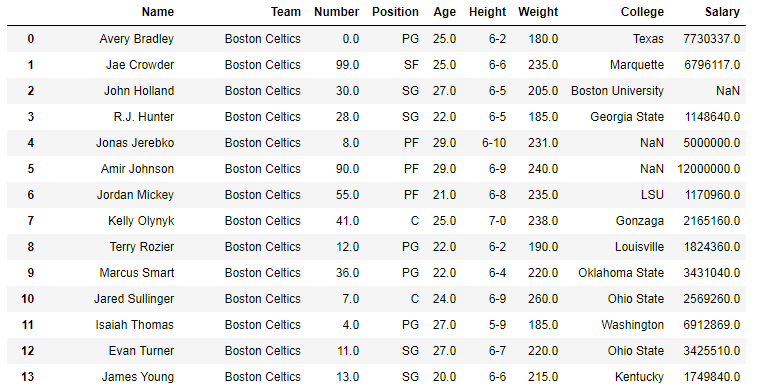
Example #1: Finding single character
In this example, a single character ‘a’ is searched in each string of Name column using str.find() method. Start and end parameters are kept default. The returned series is stored in a new column so that the indexes can be compared by looking directly. Before applying this method, null rows are dropped using .dropna() to avoid errors.
Python3
import pandas as pd
data.dropna(inplace = True)
sub ='a'
data["Indexes"]= data["Name"].str.find(sub)
data
|
Output:
As shown in the output image, the occurrence of index in the Indexes column is equal to the position first occurrence of character in the string. If the substring doesn’t exist in the text, -1 is returned. It can also be seen by looking at the first row itself that ‘A’ wasn’t considered which proves this method is case sensitive.

Example #2: Searching substring (More than one character)
In this example, ‘er’ substring will be searched in the Name column of data frame. The start parameter is kept 2 to start search from 3rd(index position 2) element.
Python3
import pandas as pd
data.dropna(inplace = True)
sub ='er'
start = 2
data["Indexes"]= data["Name"].str.find(sub, start)
data
|
Output:
As shown in the output image, the last index of occurrence of substring is returned. But it can be seen, in case of Terry Rozier(Row 9 in data frame), instead of first occurrence of ‘er’, 10 was returned. This is because the start parameter was kept 2 and the first ‘er’ occurs before that.

Share your thoughts in the comments
Please Login to comment...