ML | Understanding Data Processing
Last Updated :
06 May, 2023
Data Processing is the task of converting data from a given form to a much more usable and desired form i.e. making it more meaningful and informative. Using Machine Learning algorithms, mathematical modeling, and statistical knowledge, this entire process can be automated. The output of this complete process can be in any desired form like graphs, videos, charts, tables, images, and many more, depending on the task we are performing and the requirements of the machine. This might seem to be simple but when it comes to massive organizations like Twitter, Facebook, Administrative bodies like Parliament, UNESCO, and health sector organizations, this entire process needs to be performed in a very structured manner. So, the steps to perform are as follows:
Data processing is a crucial step in the machine learning (ML) pipeline, as it prepares the data for use in building and training ML models. The goal of data processing is to clean, transform, and prepare the data in a format that is suitable for modeling.
The main steps involved in data processing typically include:
1.Data collection: This is the process of gathering data from various sources, such as sensors, databases, or other systems. The data may be structured or unstructured, and may come in various formats such as text, images, or audio.
2.Data preprocessing: This step involves cleaning, filtering, and transforming the data to make it suitable for further analysis. This may include removing missing values, scaling or normalizing the data, or converting it to a different format.
3.Data analysis: In this step, the data is analyzed using various techniques such as statistical analysis, machine learning algorithms, or data visualization. The goal of this step is to derive insights or knowledge from the data.
4.Data interpretation: This step involves interpreting the results of the data analysis and drawing conclusions based on the insights gained. It may also involve presenting the findings in a clear and concise manner, such as through reports, dashboards, or other visualizations.
5.Data storage and management: Once the data has been processed and analyzed, it must be stored and managed in a way that is secure and easily accessible. This may involve storing the data in a database, cloud storage, or other systems, and implementing backup and recovery strategies to protect against data loss.
6.Data visualization and reporting: Finally, the results of the data analysis are presented to stakeholders in a format that is easily understandable and actionable. This may involve creating visualizations, reports, or dashboards that highlight key findings and trends in the data.
There are many tools and libraries available for data processing in ML, including pandas for Python, and the Data Transformation and Cleansing tool in RapidMiner. The choice of tools will depend on the specific requirements of the project, including the size and complexity of the data and the desired outcome.
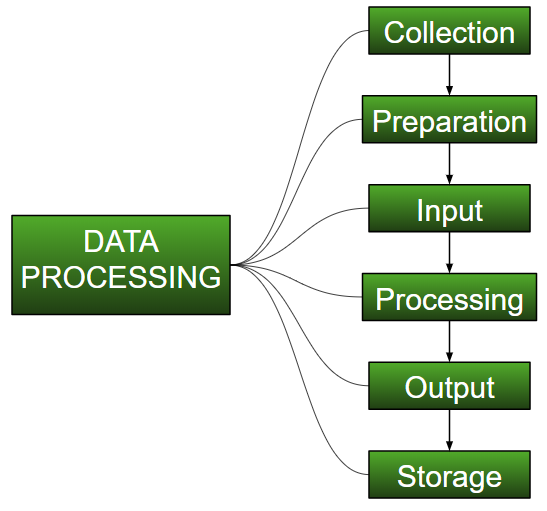
- Collection :
The most crucial step when starting with ML is to have data of good quality and accuracy. Data can be collected from any authenticated source like data.gov.in, Kaggle or UCI dataset repository. For example, while preparing for a competitive exam, students study from the best study material that they can access so that they learn the best to obtain the best results. In the same way, high-quality and accurate data will make the learning process of the model easier and better and at the time of testing, the model would yield state-of-the-art results.
A huge amount of capital, time and resources are consumed in collecting data. Organizations or researchers have to decide what kind of data they need to execute their tasks or research.
Example: Working on the Facial Expression Recognizer, needs numerous images having a variety of human expressions. Good data ensures that the results of the model are valid and can be trusted upon.
- Preparation :
The collected data can be in a raw form which can’t be directly fed to the machine. So, this is a process of collecting datasets from different sources, analyzing these datasets and then constructing a new dataset for further processing and exploration. This preparation can be performed either manually or from the automatic approach. Data can also be prepared in numeric forms also which would fasten the model’s learning.
Example: An image can be converted to a matrix of N X N dimensions, the value of each cell will indicate the image pixel.
- Input :
Now the prepared data can be in the form that may not be machine-readable, so to convert this data to the readable form, some conversion algorithms are needed. For this task to be executed, high computation and accuracy is needed. Example: Data can be collected through the sources like MNIST Digit data(images), Twitter comments, audio files, video clips.
- Processing :
This is the stage where algorithms and ML techniques are required to perform the instructions provided over a large volume of data with accuracy and optimal computation.
- Output :
In this stage, results are procured by the machine in a meaningful manner which can be inferred easily by the user. Output can be in the form of reports, graphs, videos, etc
- Storage :
This is the final step in which the obtained output and the data model data and all the useful information are saved for future use.
Advantages of data processing in Machine Learning:
- Improved model performance: Data processing helps improve the performance of the ML model by cleaning and transforming the data into a format that is suitable for modeling.
- Better representation of the data: Data processing allows the data to be transformed into a format that better represents the underlying relationships and patterns in the data, making it easier for the ML model to learn from the data.
- Increased accuracy: Data processing helps ensure that the data is accurate, consistent, and free of errors, which can help improve the accuracy of the ML model.
Disadvantages of data processing in Machine Learning:
- Time-consuming: Data processing can be a time-consuming task, especially for large and complex datasets.
- Error-prone: Data processing can be error-prone, as it involves transforming and cleaning the data, which can result in the loss of important information or the introduction of new errors.
- Limited understanding of the data: Data processing can lead to a limited understanding of the data, as the transformed data may not be representative of the underlying relationships and patterns in the data.
Reference books:
- “Data Science from Scratch: First Principles with Python” by Joel Grus.
- “Data Preparation for Data Mining” by Dorian Pyle.
- “Data Wrangling with Python” by Jacqueline Kazil and Katharine Jarmul.
Share your thoughts in the comments
Please Login to comment...