As the number of features or dimensions in a dataset increases, the amount of data required to obtain a statistically significant result increases exponentially. This can lead to issues such as overfitting, increased computation time, and reduced accuracy of machine learning models this is known as the curse of dimensionality problems that arise while working with high-dimensional data.
As the number of dimensions increases, the number of possible combinations of features increases exponentially, which makes it computationally difficult to obtain a representative sample of the data and it becomes expensive to perform tasks such as clustering or classification because it becomes. Additionally, some machine learning algorithms can be sensitive to the number of dimensions, requiring more data to achieve the same level of accuracy as lower-dimensional data.
To address the curse of dimensionality, Feature engineering techniques are used which include feature selection and feature extraction. Dimensionality reduction is a type of feature extraction technique that aims to reduce the number of input features while retaining as much of the original information as possible.
In this article, we will discuss one of the most popular dimensionality reduction techniques i.e. Principal Component Analysis(PCA).
What is Principal Component Analysis(PCA)?
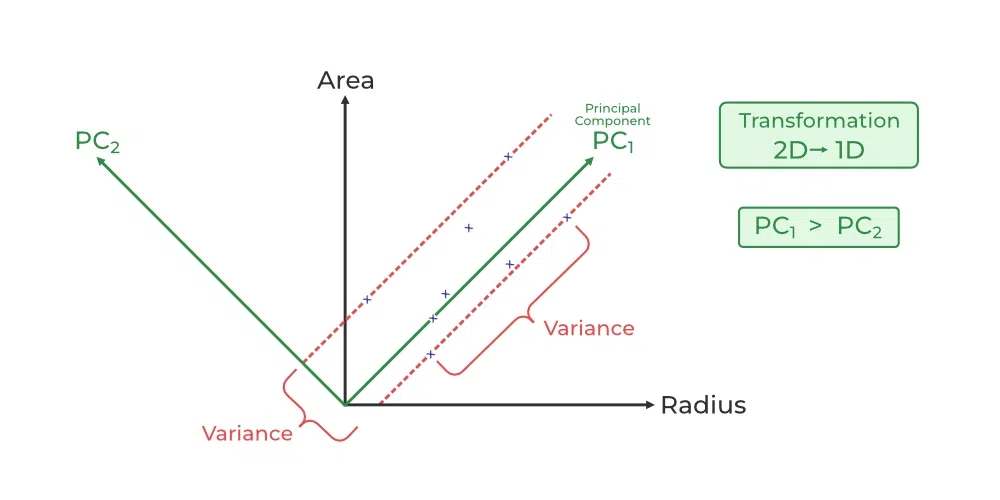
Principal Component Analysis(PCA) technique was introduced by the mathematician Karl Pearson in 1901. It works on the condition that while the data in a higher dimensional space is mapped to data in a lower dimension space, the variance of the data in the lower dimensional space should be maximum.
- Principal Component Analysis (PCA) is a statistical procedure that uses an orthogonal transformation that converts a set of correlated variables to a set of uncorrelated variables.PCA is the most widely used tool in exploratory data analysis and in machine learning for predictive models. Moreover,
- Principal Component Analysis (PCA) is an unsupervised learning algorithm technique used to examine the interrelations among a set of variables. It is also known as a general factor analysis where regression determines a line of best fit.
- The main goal of Principal Component Analysis (PCA) is to reduce the dimensionality of a dataset while preserving the most important patterns or relationships between the variables without any prior knowledge of the target variables.
Principal Component Analysis (PCA) is used to reduce the dimensionality of a data set by finding a new set of variables, smaller than the original set of variables, retaining most of the sample’s information, and useful for the regression and classification of data.
Principal Component Analysis
- Principal Component Analysis (PCA) is a technique for dimensionality reduction that identifies a set of orthogonal axes, called principal components, that capture the maximum variance in the data. The principal components are linear combinations of the original variables in the dataset and are ordered in decreasing order of importance. The total variance captured by all the principal components is equal to the total variance in the original dataset.
- The first principal component captures the most variation in the data, but the second principal component captures the maximum variance that is orthogonal to the first principal component, and so on.
- Principal Component Analysis can be used for a variety of purposes, including data visualization, feature selection, and data compression. In data visualization, PCA can be used to plot high-dimensional data in two or three dimensions, making it easier to interpret. In feature selection, PCA can be used to identify the most important variables in a dataset. In data compression, PCA can be used to reduce the size of a dataset without losing important information.
- In Principal Component Analysis, it is assumed that the information is carried in the variance of the features, that is, the higher the variation in a feature, the more information that features carries.
Overall, PCA is a powerful tool for data analysis and can help to simplify complex datasets, making them easier to understand and work with.
Step-By-Step Explanation of PCA (Principal Component Analysis)
Step 1: Standardization
First, we need to standardize our dataset to ensure that each variable has a mean of 0 and a standard deviation of 1.

Here,
Step2: Covariance Matrix Computation
Covariance measures the strength of joint variability between two or more variables, indicating how much they change in relation to each other. To find the covariance we can use the formula:

The value of covariance can be positive, negative, or zeros.
- Positive: As the x1 increases x2 also increases.
- Negative: As the x1 increases x2 also decreases.
- Zeros: No direct relation
Step 3: Compute Eigenvalues and Eigenvectors of Covariance Matrix to Identify Principal Components
Let A be a square nXn matrix and X be a non-zero vector for which

for some scalar values  . then
. then  is known as the eigenvalue of matrix A and X is known as the eigenvector of matrix A for the corresponding eigenvalue.
is known as the eigenvalue of matrix A and X is known as the eigenvector of matrix A for the corresponding eigenvalue.
It can also be written as :

where I am the identity matrix of the same shape as matrix A. And the above conditions will be true only if  will be non-invertible (i.e. singular matrix). That means,
will be non-invertible (i.e. singular matrix). That means,

From the above equation, we can find the eigenvalues \lambda, and therefore corresponding eigenvector can be found using the equation .
How Principal Component Analysis(PCA) works?
Hence, PCA employs a linear transformation that is based on preserving the most variance in the data using the least number of dimensions. It involves the following steps:
Python3
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer(as_frame=True)
df = cancer.frame
print('Original Dataframe shape :',df.shape)
X = df[cancer['feature_names']]
print('Inputs Dataframe shape :', X.shape)
|
Output:
Original Dataframe shape : (569, 31)
Inputs Dataframe shape : (569, 30)
Now we will apply the first most step which is to standardize the data and for that, we will have to first calculate the mean and standard deviation of each feature in the feature space.
Python3
X_mean = X.mean()
X_std = X.std()
Z = (X - X_mean) / X_std
|
The covariance matrix helps us visualize how strong the dependency of two features is with each other in the feature space.
Python3
c = Z.cov()
import matplotlib.pyplot as plt
import seaborn as sns
sns.heatmap(c)
plt.show()
|
Output:
-(1).webp)
Now we will compute the eigenvectors and eigenvalues for our feature space which serve a great purpose in identifying the principal components for our feature space.
Python3
eigenvalues, eigenvectors = np.linalg.eig(c)
print('Eigen values:\n', eigenvalues)
print('Eigen values Shape:', eigenvalues.shape)
print('Eigen Vector Shape:', eigenvectors.shape)
|
Output:
Eigen values:
[1.32816077e+01 5.69135461e+00 2.81794898e+00 1.98064047e+00
1.64873055e+00 1.20735661e+00 6.75220114e-01 4.76617140e-01
4.16894812e-01 3.50693457e-01 2.93915696e-01 2.61161370e-01
2.41357496e-01 1.57009724e-01 9.41349650e-02 7.98628010e-02
5.93990378e-02 5.26187835e-02 4.94775918e-02 1.33044823e-04
7.48803097e-04 1.58933787e-03 6.90046388e-03 8.17763986e-03
1.54812714e-02 1.80550070e-02 2.43408378e-02 2.74394025e-02
3.11594025e-02 2.99728939e-02]
Eigen values Shape: (30,)
Eigen Vector Shape: (30, 30)
Sort the eigenvalues in descending order and sort the corresponding eigenvectors accordingly.
Python3
idx = eigenvalues.argsort()[::-1]
eigenvalues = eigenvalues[idx]
eigenvectors = eigenvectors[:,idx]
|
Explained variance is the term that gives us an idea of the amount of the total variance which has been retained by selecting the principal components instead of the original feature space.
Python3
explained_var = np.cumsum(eigenvalues) / np.sum(eigenvalues)
explained_var
|
Output:
array([0.44272026, 0.63243208, 0.72636371, 0.79238506, 0.84734274,
0.88758796, 0.9100953 , 0.92598254, 0.93987903, 0.95156881,
0.961366 , 0.97007138, 0.97811663, 0.98335029, 0.98648812,
0.98915022, 0.99113018, 0.99288414, 0.9945334 , 0.99557204,
0.99657114, 0.99748579, 0.99829715, 0.99889898, 0.99941502,
0.99968761, 0.99991763, 0.99997061, 0.99999557, 1. ])
Determine the Number of Principal Components
Here we can either consider the number of principal components of any value of our choice or by limiting the explained variance. Here I am considering explained variance more than equal to 50%. Let’s check how many principal components come into this.
Python3
n_components = np.argmax(explained_var >= 0.50) + 1
n_components
|
Output:
2
Project the Data onto the Selected Principal Components
- Find the projection matrix, It is a matrix of eigenvectors corresponding to the largest eigenvalues of the covariance matrix of the data. it projects the high-dimensional dataset onto a lower-dimensional subspace
- The eigenvectors of the covariance matrix of the data are referred to as the principal axes of the data, and the projection of the data instances onto these principal axes are called the principal components.
Python3
u = eigenvectors[:,:n_components]
pca_component = pd.DataFrame(u,
index = cancer['feature_names'],
columns = ['PC1','PC2']
)
plt.figure(figsize =(5, 7))
sns.heatmap(pca_component)
plt.title('PCA Component')
plt.show()
|
Output:
.webp)
- Then, we project our dataset using the formula:

- Dimensionality reduction is then obtained by only retaining those axes (dimensions) that account for most of the variance, and discarding all others.

Finding Projection in PCA
Python3
Z_pca = Z @ pca_component
Z_pca.rename({'PC1': 'PCA1', 'PC2': 'PCA2'}, axis=1, inplace=True)
print(Z_pca)
|
Output:
PCA1 PCA2
0 9.184755 1.946870
1 2.385703 -3.764859
2 5.728855 -1.074229
3 7.116691 10.266556
4 3.931842 -1.946359
.. ... ...
564 6.433655 -3.573673
565 3.790048 -3.580897
566 1.255075 -1.900624
567 10.365673 1.670540
568 -5.470430 -0.670047
[569 rows x 2 columns]
The eigenvectors of the covariance matrix of the data are referred to as the principal axes of the data, and the projection of the data instances onto these principal axes are called the principal components. Dimensionality reduction is then obtained by only retaining those axes (dimensions) that account for most of the variance, and discarding all others.
PCA using Using Sklearn
There are different libraries in which the whole process of the principal component analysis has been automated by implementing it in a package as a function and we just have to pass the number of principal components which we would like to have. Sklearn is one such library that can be used for the PCA as shown below.
Python3
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(Z)
x_pca = pca.transform(Z)
df_pca1 = pd.DataFrame(x_pca,
columns=['PC{}'.
format(i+1)
for i in range(n_components)])
print(df_pca1)
|
Output:
PC1 PC2
0 9.184755 1.946870
1 2.385703 -3.764859
2 5.728855 -1.074229
3 7.116691 10.266556
4 3.931842 -1.946359
.. ... ...
564 6.433655 -3.573673
565 3.790048 -3.580897
566 1.255075 -1.900624
567 10.365673 1.670540
568 -5.470430 -0.670047
[569 rows x 2 columns]
We can match from the above Z_pca result from it is exactly the same values.
Python3
plt.figure(figsize=(8, 6))
plt.scatter(x_pca[:, 0], x_pca[:, 1],
c=cancer['target'],
cmap='plasma')
plt.xlabel('First Principal Component')
plt.ylabel('Second Principal Component')
plt.show()
|
Output:
-(1).webp)
Output:
array([[ 0.21890244, 0.10372458, 0.22753729, 0.22099499, 0.14258969,
0.23928535, 0.25840048, 0.26085376, 0.13816696, 0.06436335,
0.20597878, 0.01742803, 0.21132592, 0.20286964, 0.01453145,
0.17039345, 0.15358979, 0.1834174 , 0.04249842, 0.10256832,
0.22799663, 0.10446933, 0.23663968, 0.22487053, 0.12795256,
0.21009588, 0.22876753, 0.25088597, 0.12290456, 0.13178394],
[-0.23385713, -0.05970609, -0.21518136, -0.23107671, 0.18611302,
0.15189161, 0.06016536, -0.0347675 , 0.19034877, 0.36657547,
-0.10555215, 0.08997968, -0.08945723, -0.15229263, 0.20443045,
0.2327159 , 0.19720728, 0.13032156, 0.183848 , 0.28009203,
-0.21986638, -0.0454673 , -0.19987843, -0.21935186, 0.17230435,
0.14359317, 0.09796411, -0.00825724, 0.14188335, 0.27533947]])
Advantages of Principal Component Analysis
- Dimensionality Reduction: Principal Component Analysis is a popular technique used for dimensionality reduction, which is the process of reducing the number of variables in a dataset. By reducing the number of variables, PCA simplifies data analysis, improves performance, and makes it easier to visualize data.
- Feature Selection: Principal Component Analysis can be used for feature selection, which is the process of selecting the most important variables in a dataset. This is useful in machine learning, where the number of variables can be very large, and it is difficult to identify the most important variables.
- Data Visualization: Principal Component Analysis can be used for data visualization. By reducing the number of variables, PCA can plot high-dimensional data in two or three dimensions, making it easier to interpret.
- Multicollinearity: Principal Component Analysis can be used to deal with multicollinearity, which is a common problem in a regression analysis where two or more independent variables are highly correlated. PCA can help identify the underlying structure in the data and create new, uncorrelated variables that can be used in the regression model.
- Noise Reduction: Principal Component Analysis can be used to reduce the noise in data. By removing the principal components with low variance, which are assumed to represent noise, Principal Component Analysis can improve the signal-to-noise ratio and make it easier to identify the underlying structure in the data.
- Data Compression: Principal Component Analysis can be used for data compression. By representing the data using a smaller number of principal components, which capture most of the variation in the data, PCA can reduce the storage requirements and speed up processing.
- Outlier Detection: Principal Component Analysis can be used for outlier detection. Outliers are data points that are significantly different from the other data points in the dataset. Principal Component Analysis can identify these outliers by looking for data points that are far from the other points in the principal component space.
Disadvantages of Principal Component Analysis
- Interpretation of Principal Components: The principal components created by Principal Component Analysis are linear combinations of the original variables, and it is often difficult to interpret them in terms of the original variables. This can make it difficult to explain the results of PCA to others.
- Data Scaling: Principal Component Analysis is sensitive to the scale of the data. If the data is not properly scaled, then PCA may not work well. Therefore, it is important to scale the data before applying Principal Component Analysis.
- Information Loss: Principal Component Analysis can result in information loss. While Principal Component Analysis reduces the number of variables, it can also lead to loss of information. The degree of information loss depends on the number of principal components selected. Therefore, it is important to carefully select the number of principal components to retain.
- Non-linear Relationships: Principal Component Analysis assumes that the relationships between variables are linear. However, if there are non-linear relationships between variables, Principal Component Analysis may not work well.
- Computational Complexity: Computing Principal Component Analysis can be computationally expensive for large datasets. This is especially true if the number of variables in the dataset is large.
- Overfitting: Principal Component Analysis can sometimes result in overfitting, which is when the model fits the training data too well and performs poorly on new data. This can happen if too many principal components are used or if the model is trained on a small dataset.
Frequently Asked Questions (FAQs)
1. What is Principal Component Analysis (PCA)?
PCA is a dimensionality reduction technique used in statistics and machine learning to transform high-dimensional data into a lower-dimensional representation, preserving the most important information.
2. How does a PCA work?
Principal components are linear combinations of the original features that PCA finds and uses to capture the most variance in the data. In order of the amount of variance they explain, these orthogonal components are arranged.
3. When should PCA be applied?
Using PCA is advantageous when working with multicollinear or high-dimensional datasets. Feature extraction, noise reduction, and data preprocessing are prominent uses for it.
4. How are principal components interpreted?
New axes are represented in the feature space by each principal component. An indicator of a component’s significance in capturing data variability is its capacity to explain a larger variance.
5. What is the significance of principal components?
Principal components represent the directions in which the data varies the most. The first few components typically capture the majority of the data’s variance, allowing for a more concise representation.
Share your thoughts in the comments
Please Login to comment...