How to Detect Outliers in Machine Learning
Last Updated :
21 Dec, 2023
In machine learning, an outlier is a data point that stands out a lot from the other data points in a set. The article explores the fundamentals of outlier and how it can be handled to solve machine learning problems.
What is an outlier?
An outlier is a data point that significantly deviates from the rest of the data. It can be either much higher or much lower than the other data points, and its presence can have a significant impact on the results of machine learning algorithms. They can be caused by measurement or execution errors. The analysis of outlier data is referred to as outlier analysis or outlier mining.
Types of Outliers
There are two main types of outliers:
- Global outliers: Global outliers are isolated data points that are far away from the main body of the data. They are often easy to identify and remove.
- Contextual outliers: Contextual outliers are data points that are unusual in a specific context but may not be outliers in a different context. They are often more difficult to identify and may require additional information or domain knowledge to determine their significance.
Algorithm
- Calculate the mean of each cluster
- Initialize the Threshold value
- Calculate the distance of the test data from each cluster mean
- Find the nearest cluster to the test data
- If (Distance > Threshold) then, Outlier
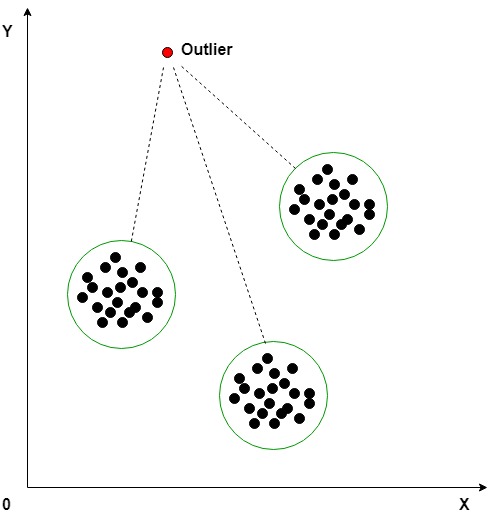
Outlier Detection Methods in Machine Learning
Outlier detection plays a crucial role in ensuring the quality and accuracy of machine learning models. By identifying and removing or handling outliers effectively, we can prevent them from biasing the model, reducing its performance, and hindering its interpretability. Here’s an overview of various outlier detection methods:
1. Statistical Methods:
- Z-Score: This method calculates the standard deviation of the data points and identifies outliers as those with Z-scores exceeding a certain threshold (typically 3 or -3).
- Interquartile Range (IQR): IQR identifies outliers as data points falling outside the range defined by Q1-k*(Q3-Q1) and Q3+k*(Q3-Q1), where Q1 and Q3 are the first and third quartiles, and k is a factor (typically 1.5).
2. Distance-Based Methods:
- K-Nearest Neighbors (KNN): KNN identifies outliers as data points whose K nearest neighbors are far away from them.
- Local Outlier Factor (LOF): This method calculates the local density of data points and identifies outliers as those with significantly lower density compared to their neighbors.
3. Clustering-Based Methods:
- Density-Based Spatial Clustering of Applications with Noise (DBSCAN): In DBSCAN, clusters data points based on their density and identifies outliers as points not belonging to any cluster.
- Hierarchical clustering: Hierarchical clustering involves building a hierarchy of clusters by iteratively merging or splitting clusters based on their similarity. Outliers can be identified as clusters containing only a single data point or clusters significantly smaller than others.
4. Other Methods:
- Isolation Forest: Isolation forest randomly isolates data points by splitting features and identifies outliers as those isolated quickly and easily.
- One-class Support Vector Machines (OCSVM): One-Class SVM learns a boundary around the normal data and identifies outliers as points falling outside the boundary.
Techniques for Handling Outliers in Machine Learning
Outliers, data points that significantly deviate from the majority, can have detrimental effects on machine learning models. To address this, several techniques can be employed to handle outliers effectively:
1. Removal:
- This involves identifying and removing outliers from the dataset before training the model. Common methods include:
- Thresholding: Outliers are identified as data points exceeding a certain threshold (e.g., Z-score > 3).
- Distance-based methods: Outliers are identified based on their distance from their nearest neighbors.
- Clustering: Outliers are identified as points not belonging to any cluster or belonging to very small clusters.
2. Transformation:
- This involves transforming the data to reduce the influence of outliers. Common methods include:
- Scaling: Standardizing or normalizing the data to have a mean of zero and a standard deviation of one.
- Winsorization: Replacing outlier values with the nearest non-outlier value.
- Log transformation: Applying a logarithmic transformation to compress the data and reduce the impact of extreme values.
3. Robust Estimation:
- This involves using algorithms that are less sensitive to outliers. Some examples include:
- Robust regression: Algorithms like L1-regularized regression or Huber regression are less influenced by outliers than least squares regression.
- M-estimators: These algorithms estimate the model parameters based on a robust objective function that down weights the influence of outliers.
- Outlier-insensitive clustering algorithms: Algorithms like DBSCAN are less susceptible to the presence of outliers than K-means clustering.
4. Modeling Outliers:
- This involves explicitly modeling the outliers as a separate group. This can be done by:
- Adding a separate feature: Create a new feature indicating whether a data point is an outlier or not.
- Using a mixture model: Train a model that assumes the data comes from a mixture of multiple distributions, where one distribution represents the outliers.
Importance of outlier detection in machine learning
Outlier detection is important in machine learning for several reasons:
- Biased models: Outliers can bias a machine learning model towards the outlier values, leading to poor performance on the rest of the data. This can be particularly problematic for algorithms that are sensitive to outliers, such as linear regression.
- Reduced accuracy: Outliers can introduce noise into the data, making it difficult for a machine learning model to learn the true underlying patterns. This can lead to reduced accuracy and performance.
- Increased variance: Outliers can increase the variance of a machine learning model, making it more sensitive to small changes in the data. This can make it difficult to train a stable and reliable model.
- Reduced interpretability: Outliers can make it difficult to understand what a machine learning model has learned from the data. This can make it difficult to trust the model’s predictions and can hamper efforts to improve its performance.
Conclusion
Outlier detection and handling are crucial aspects of building reliable and robust machine learning models. Understanding the impact of outliers, choosing the appropriate technique for your specific data and task, and leveraging domain knowledge and data visualization can ensure that your models perform well on unseen data and provide accurate and trustworthy predictions.
Frequently Asked Question (FAQs)
1. What are outliers in machine learning?
Outliers are data points that significantly deviate from the majority of the data. They can be caused by errors, anomalies, or simply rare events.
2. Why are outliers problematic for machine learning models?
Outliers can negatively impact the performance of machine learning models in several ways:
- Overfitting: Models can focus on fitting the outliers rather than the underlying patterns in the majority of the data.
- Reduced accuracy: Outliers can pull the model’s predictions towards themselves, leading to inaccurate predictions for other data points.
- Unstable models: The presence of outliers can make the model’s predictions sensitive to small changes in the data.
3. How can outliers be detected?
There are several methods for detecting outliers, including:
- Distance-based measures: These measures, like Z-score and interquartile range (IQR), calculate the distance of a data point from the center of the data distribution.
- Visualization techniques: Techniques like boxplots and scatter plots can visually identify data points that lie far away from the majority of the data.
- Clustering algorithms: Clustering algorithms can automatically group similar data points, isolating outliers as separate clusters.
4. How can we handle outliers?
There are several approaches to handling outliers in machine learning:
- Removing outliers: This is a simple approach but can lead to information loss.
- Clipping: Outliers are capped to a certain value instead of being removed completely.
- Transformation: Data can be transformed to reduce the impact of outliers, such as using log transformations for skewed data.
- Robust models: Certain models are less sensitive to outliers, such as decision trees and support vector machines.
5. When should we remove outliers?
Removing outliers can be beneficial when they are likely due to errors or anomalies. However, it should be avoided when outliers represent genuine, albeit rare, occurrences within the data.
Share your thoughts in the comments
Please Login to comment...