Scraping Reddit using Python
Last Updated :
07 Oct, 2021
In this article, we are going to see how to scrape Reddit using Python, here we will be using python’s PRAW (Python Reddit API Wrapper) module to scrape the data. Praw is an acronym Python Reddit API wrapper, it allows Reddit API through Python scripts.
Installation
To install PRAW, run the following commands on the command prompt:
pip install praw
Creating a Reddit App
Step 1: To extract data from Reddit, we need to create a Reddit app. You can create a new Reddit app(https://www.reddit.com/prefs/apps).
Reddit – Create an App
Step 2: Click on “are you a developer? create an app…”.
Step 3: A form like this will show up on your screen. Enter the name and description of your choice. In the redirect uri box, enter http://localhost:8080

App Form
Step 4: After entering the details, click on “create app”.
Developed Application
The Reddit app has been created. Now, we can use python and praw to scrape data from Reddit. Note down the client_id, secret, and user_agent values. These values will be used to connect to Reddit using python.
Creating a PRAW Instance
In order to connect to Reddit, we need to create a praw instance. There are 2 types of praw instances:
- Read-only Instance: Using read-only instances, we can only scrape publicly available information on Reddit. For example, retrieving the top 5 posts from a particular subreddit.
- Authorized Instance: Using an authorized instance, you can do everything you do with your Reddit account. Actions like upvote, post, comment, etc., can be performed.
Python3
reddit_read_only = praw.Reddit(client_id="",
client_secret="",
user_agent="")
reddit_authorized = praw.Reddit(client_id="",
client_secret="",
user_agent="",
username="",
password="")
|
Now that we have created an instance, we can use Reddit’s API to extract data. In this tutorial, we will be only using the read-only instance.
Scraping Reddit Subreddits
There are different ways of extracting data from a subreddit. The posts in a subreddit are sorted as hot, new, top, controversial, etc. You can use any sorting method of your choice.
Let’s extract some information from the redditdev subreddit.
Python3
import praw
import pandas as pd
reddit_read_only = praw.Reddit(client_id="",
client_secret="",
user_agent="")
subreddit = reddit_read_only.subreddit("redditdev")
print("Display Name:", subreddit.display_name)
print("Title:", subreddit.title)
print("Description:", subreddit.description)
|
Output:
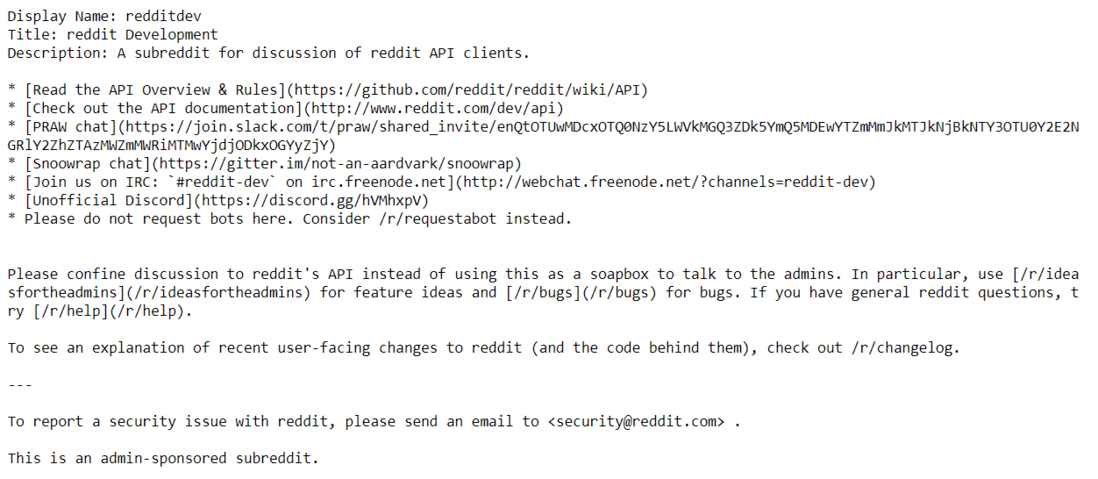
Name, Title, and Description
Now let’s extract 5 hot posts from the Python subreddit:
Python3
subreddit = reddit_read_only.subreddit("Python")
for post in subreddit.hot(limit=5):
print(post.title)
print()
|
Output:

Top 5 hot posts
We will now save the top posts of the python subreddit in a pandas data frame:
Python3
posts = subreddit.top("month")
posts_dict = {"Title": [], "Post Text": [],
"ID": [], "Score": [],
"Total Comments": [], "Post URL": []
}
for post in posts:
posts_dict["Title"].append(post.title)
posts_dict["Post Text"].append(post.selftext)
posts_dict["ID"].append(post.id)
posts_dict["Score"].append(post.score)
posts_dict["Total Comments"].append(post.num_comments)
posts_dict["Post URL"].append(post.url)
top_posts = pd.DataFrame(posts_dict)
top_posts
|
Output:

top posts of the python subreddit
Exporting Data to a CSV File:
Python3
import pandas as pd
top_posts.to_csv("Top Posts.csv", index=True)
|
Output:

CSV File of Top Posts
Scraping Reddit Posts:
To extract data from Reddit posts, we need the URL of the post. Once we have the URL, we need to create a submission object.
Python3
import praw
import pandas as pd
reddit_read_only = praw.Reddit(client_id="",
client_secret="",
user_agent="")
url = "https://www.reddit.com/r/IAmA/comments/m8n4vt/\
im_bill_gates_cochair_of_the_bill_and_melinda/"
submission = reddit_read_only.submission(url=url)
|
We will extract the best comments from the post we have selected. We will need the MoreComments object from the praw module. To extract the comments, we will use a for-loop on the submission object. All the comments will be added to the post_comments list. We will also add an if-statement in the for-loop to check whether any comment has the object type of more comments. If it does, it means that our post has more comments available. So we will add these comments to our list as well. Finally, we will convert the list into a pandas data frame.
Python3
from praw.models import MoreComments
post_comments = []
for comment in submission.comments:
if type(comment) == MoreComments:
continue
post_comments.append(comment.body)
comments_df = pd.DataFrame(post_comments, columns=['comment'])
comments_df
|
Output:

list into a pandas dataframe
Share your thoughts in the comments
Please Login to comment...