Speech Recognition in Python using Google Speech API
Last Updated :
28 Nov, 2022
Speech Recognition is an important feature in several applications used such as home automation, artificial intelligence, etc. This article aims to provide an introduction to how to make use of the SpeechRecognition library of Python. This is useful as it can be used on microcontrollers such as Raspberry Pi with the help of an external microphone.
Required Installations
The following must be installed:
Python Speech Recognition module:
sudo pip install SpeechRecognition
PyAudio: Use the following command for Linux users
sudo apt-get install python-pyaudio python3-pyaudio
If the versions in the repositories are too old, install pyaudio using the following command
sudo apt-get install portaudio19-dev python-all-dev python3-all-dev &&
sudo pip install pyaudio
Use pip3 instead of pip for python3. Windows users can install pyaudio by executing the following command in a terminal
pip install pyaudio
Speech Input Using a Microphone and Translation of Speech to Text
- Configure Microphone (For external microphones): It is advisable to specify the microphone during the program to avoid any glitches. Type lsusb in the terminal for LInux and you can use the PowerShell’s Get-PnpDevice -PresentOnly | Where-Object { $_.InstanceId -match ‘^USB’ } command to list the connected USB devices. A list of connected devices will show up. The microphone name would look like this
USB Device 0x46d:0x825: Audio (hw:1, 0)
- Make a note of this as it will be used in the program.
- Set Chunk Size: This basically involved specifying how many bytes of data we want to read at once. Typically, this value is specified in powers of 2 such as 1024 or 2048
- Set Sampling Rate: Sampling rate defines how often values are recorded for processing
- Set Device ID to the selected microphone: In this step, we specify the device ID of the microphone that we wish to use in order to avoid ambiguity in case there are multiple microphones. This also helps debug, in the sense that, while running the program, we will know whether the specified microphone is being recognized. During the program, we specify a parameter device_id. The program will say that device_id could not be found if the microphone is not recognized.
- Allow Adjusting for Ambient Noise: Since the surrounding noise varies, we must allow the program a second or two to adjust the energy threshold of recording so it is adjusted according to the external noise level.
- Speech to text translation: This is done with the help of Google Speech Recognition. This requires an active internet connection to work. However, there are certain offline Recognition systems such as PocketSphinx, that have a very rigorous installation process that requires several dependencies. Google Speech Recognition is one of the easiest to use.
Troubleshooting
The following problems are commonly encountered
Muted Microphone: This leads to input not being received. To check for this, you can use alsamixer. It can be installed using
sudo apt-get install libasound2 alsa-utils alsa-oss
Type amixer. The output will look somewhat like this
Simple mixer control 'Master', 0
Capabilities: pvolume pswitch pswitch-joined
Playback channels: Front Left - Front Right
Limits: Playback 0 - 65536
Mono:
Front Left: Playback 41855 [64%] [on]
Front Right: Playback 65536 [100%] [on]
Simple mixer control 'Capture', 0
Capabilities: cvolume cswitch cswitch-joined
Capture channels: Front Left - Front Right
Limits: Capture 0 - 65536
Front Left: Capture 0 [0%] [off] #switched off
Front Right: Capture 0 [0%] [off]
As you can see, the capture device is currently switched off. To switch it on, type alsamixer As you can see in the first picture, it is displaying our playback devices. Press F4 to toggle to Capture devices.
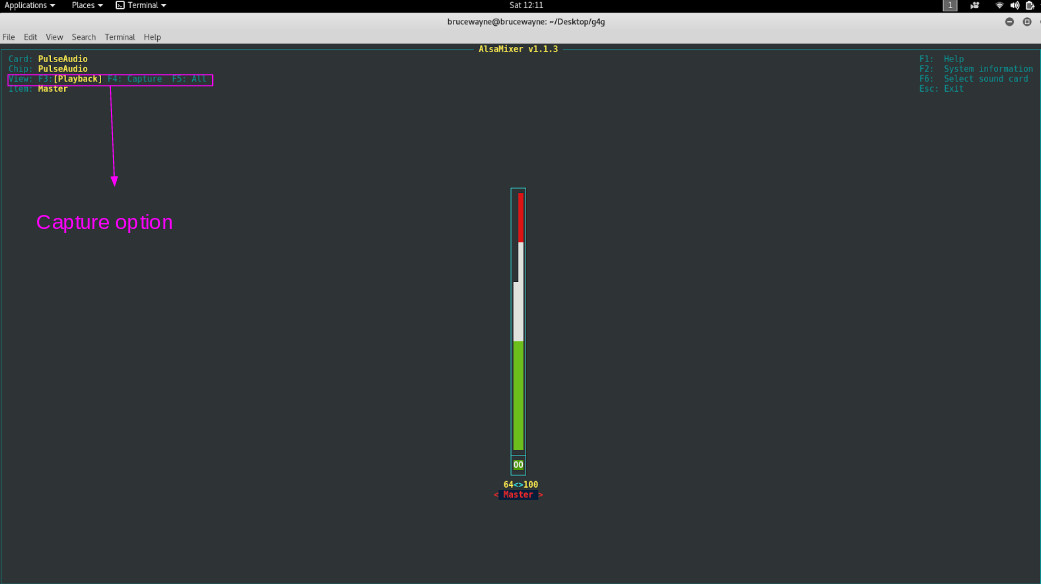
In the second picture, the highlighted portion shows that the capture device is muted. To unmute it, press the space bar . As you can see in the last picture, the highlighted part confirms that the capture device is not muted.
As you can see in the last picture, the highlighted part confirms that the capture device is not muted. 
Current microphone not selected as a capture device: In this case, the microphone can be set by typing alsamixer and selecting sound cards. Here, you can select the default microphone device. As shown in the picture, the highlighted portion is where you have to select the sound card.  The second picture shows the screen selection for the sound card.
The second picture shows the screen selection for the sound card.
No Internet Connection: The speech-to-text conversion requires an active internet connection.
Share your thoughts in the comments
Please Login to comment...