ML | Extra Tree Classifier for Feature Selection
Last Updated :
18 May, 2023
Prerequisites: Decision Tree Classifier Extremely Randomized Trees Classifier(Extra Trees Classifier) is a type of ensemble learning technique which aggregates the results of multiple de-correlated decision trees collected in a “forest” to output it’s classification result. In concept, it is very similar to a Random Forest Classifier and only differs from it in the manner of construction of the decision trees in the forest. Each Decision Tree in the Extra Trees Forest is constructed from the original training sample. Then, at each test node, Each tree is provided with a random sample of k features from the feature-set from which each decision tree must select the best feature to split the data based on some mathematical criteria (typically the Gini Index). This random sample of features leads to the creation of multiple de-correlated decision trees. To perform feature selection using the above forest structure, during the construction of the forest, for each feature, the normalized total reduction in the mathematical criteria used in the decision of feature of split (Gini Index if the Gini Index is used in the construction of the forest) is computed. This value is called the Gini Importance of the feature. To perform feature selection, each feature is ordered in descending order according to the Gini Importance of each feature and the user selects the top k features according to his/her choice. Consider the following data:- 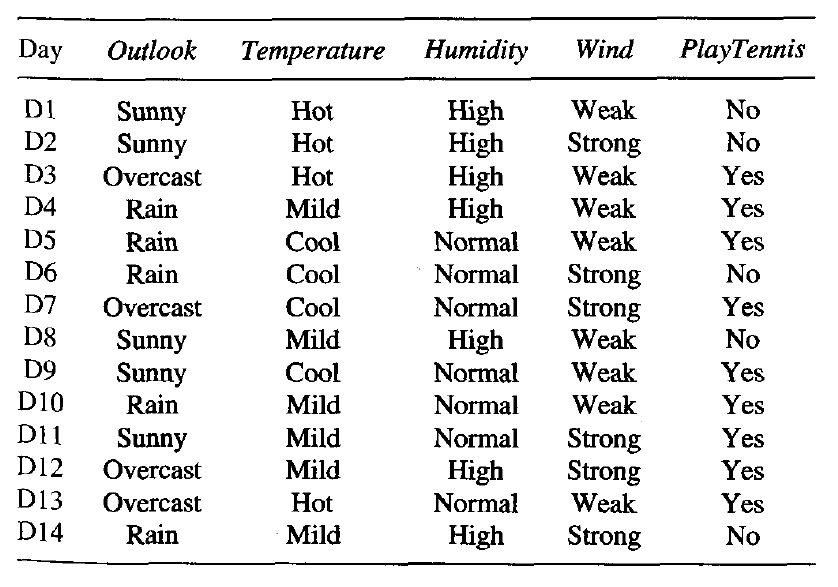 Let us build a hypothetical Extra Trees Forest for the above data with five decision trees and the value of k which decides the number of features in a random sample of features be two. Here the decision criteria used will be Information Gain. First, we calculate the entropy of the data. Note the formula for calculating the entropy is:-
Let us build a hypothetical Extra Trees Forest for the above data with five decision trees and the value of k which decides the number of features in a random sample of features be two. Here the decision criteria used will be Information Gain. First, we calculate the entropy of the data. Note the formula for calculating the entropy is:- where c is the number of unique class labels and
where c is the number of unique class labels and  is the proportion of rows with output label is i. Therefore for the given data, the entropy is:-
is the proportion of rows with output label is i. Therefore for the given data, the entropy is:-  [Tex]\Rightarrow Entropy(S) = 0.940 [/Tex]Let the decision trees be constructed such that:-
[Tex]\Rightarrow Entropy(S) = 0.940 [/Tex]Let the decision trees be constructed such that:-
- 1st Decision Tree gets data with the features Outlook and Temperature: Note that the formula for Information Gain is:-
 Thus,
Thus,
 [Tex]\Rightarrow Gain(S, Outlook) = 0.246[/Tex]
[Tex]\Rightarrow Gain(S, Outlook) = 0.246[/Tex]

- 2nd Decision Tree gets data with the features Temperature and Wind: Using the above-given formulas:-
[Tex]Gain(S, Wind) = 0.048[/Tex]
- strong>3rd Decision Tree gets data with the features Outlook and Humidity:
 [Tex]Gain(S, Humidity) = 0.151[/Tex]
[Tex]Gain(S, Humidity) = 0.151[/Tex]
- 4th Decision Tree gets data with the features Temperature and Humidity:
[Tex]Gain(S, Humidity) = 0.151[/Tex]
- 5th Decision Tree gets data with the features Wind and Humidity:
 [Tex]Gain(S, Humidity) = 0.151[/Tex]
[Tex]Gain(S, Humidity) = 0.151[/Tex]
- Computing total Info Gain for each feature:-
Total Info Gain for Outlook = 0.246+0.246 = 0.492
Total Info Gain for Temperature = 0.029+0.029+0.029 = 0.087
Total Info Gain for Humidity = 0.151+0.151+0.151 = 0.453
Total Info Gain for Wind = 0.048+0.048 = 0.096
Thus the most important variable to determine the output label according to the above constructed Extra Trees Forest is the feature “Outlook”. The below given code will demonstrate how to do feature selection by using Extra Trees Classifiers. Step 1: Importing the required libraries
Python3
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import ExtraTreesClassifier
|
Step 2: Loading and Cleaning the Data
Python3
cd C:\Users\Dev\Desktop\Kaggle
df = pd.read_csv('data.csv')
y = df['Play Tennis']
X = df.drop('Play Tennis', axis = 1)
X.head()
|
 Step 3: Building the Extra Trees Forest and computing the individual feature importances
Step 3: Building the Extra Trees Forest and computing the individual feature importances
Python3
extra_tree_forest = ExtraTreesClassifier(n_estimators = 5,
criterion ='entropy', max_features = 2)
extra_tree_forest.fit(X, y)
feature_importance = extra_tree_forest.feature_importances_
feature_importance_normalized = np.std([tree.feature_importances_ for tree in
extra_tree_forest.estimators_],
axis = 0)
|
Step 4: Visualizing and Comparing the results
Python3
plt.bar(X.columns, feature_importance_normalized)
plt.xlabel('Feature Labels')
plt.ylabel('Feature Importances')
plt.title('Comparison of different Feature Importances')
plt.show()
|
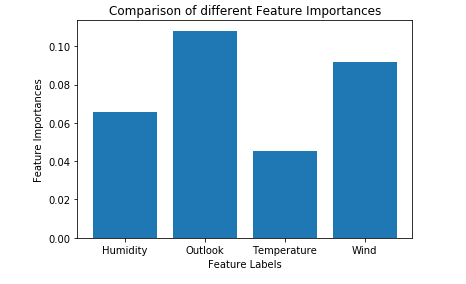 Thus the above-given output validates our theory about feature selection using Extra Trees Classifier. The importance of features might have different values because of the random nature of feature samples.
Thus the above-given output validates our theory about feature selection using Extra Trees Classifier. The importance of features might have different values because of the random nature of feature samples.
The Extra Trees Classifier for feature selection offers several advantages:
- Robust to noise and irrelevant features: Extra Trees Classifier utilizes multiple decision trees and selects features based on their importance scores, making it less sensitive to noise and irrelevant features. It can effectively handle datasets with a large number of features and noisy data.
- Computational efficiency: Extra Trees Classifier constructs decision trees in parallel, which can significantly speed up the training process compared to other feature selection techniques. It is particularly useful for high-dimensional datasets where efficiency is crucial.
- Bias reduction: The random selection of subsets and random splitting points in Extra Trees Classifier helps to reduce the bias that can arise from using a single decision tree. By considering multiple decision trees, it provides a more comprehensive evaluation of feature importance.
- Feature ranking: Extra Trees Classifier assigns importance scores to each feature, allowing you to rank them based on their relative importance. This ranking can provide insights into the relevance and contribution of each feature to the target variable.
- Handling multicollinearity: The Extra Trees Classifier can handle correlated features effectively. By randomly selecting subsets of features and utilizing random splits, it reduces the impact of multicollinearity, unlike methods that rely on explicit feature correlations.
- Feature selection flexibility: The feature selection process in Extra Trees Classifier is based on feature importances, allowing you to adapt the threshold for feature inclusion according to your specific needs. You can choose to include only the most important features or a larger subset, depending on the desired balance between feature reduction and model performance.
- Generalization and interpretability: By selecting a subset of relevant features, Extra Trees Classifier can improve model generalization by reducing overfitting. Additionally, the selected features can provide interpretable insights into the factors that drive predictions and influence the target variable.
These advantages make the Extra Trees Classifier a valuable tool for feature selection, especially when dealing with high-dimensional datasets, noisy data, and situations where computational efficiency is essential.
Share your thoughts in the comments
Please Login to comment...