Virtusa Corporation is a Massachusetts-based IT services company that partners with businesses to help them solve complex problems and navigate the present and future environment. Virtusa provides domain expertise and technical skills to transform any business at a very large scale with good speed. Their unique Engineering First approach blends deep industry expertise and empowered, agile teams, to create holistic solutions that seamlessly move the business forward. They help clients to engage with new technology paradigms and creatively build solutions that drive them to be the best in their industries.

Aspiring for a challenging role at Virtusa? Acing the interview is your key to unlock a world of exciting opportunities. But with fierce competition, knowing what to expect is half the battle. That’s where this comprehensive guide comes in, packed with a treasure full of Virtusa Interview Questions. We dive deep into DSA, DBMS, OS, CN revealing the most frequently asked questions across each of them. From coding questions to core concepts, we dissect Virtusa Interview Questions that assess your technical strength and career aspirations. So, buckle up and get ready to decode the secrets to a stellar Virtusa interview! This insider’s perspective, armed with Virtusa Interview Questions you won’t find anywhere else, will empower you to confidently navigate the process and land your dream job at Virtusa. Remember, knowledge is power, and with this collection of Virtusa Interview Questions, you’ll be unstoppable!
To know more about the Virtusa Recruitment Process please go through this attached link
This ultimate guide gives you 35+ interview questions that have been carefully selected for each subject and are frequently asked in Virtusa’s technical interviews. Master these topics, from basic concepts to practical problems, to sharpen your abilities, ace your interview with confidence, and open the door to your Virtusa success story.
Q1. What is Encapsulation?
Encapsulation in Java is a fundamental concept in object-oriented programming (OOP) that refers to the bundling of data and methods that operate on that data within a single unit, which is called a class in Java.
Q2. What is Abstraction?
In Java, Data Abstraction is the property by virtue of which only the essential details are displayed to the user.
Q3. What is a virtual function?
A virtual function (also known as virtual methods) is a member function that is declared within a base class and is re-defined (overridden) by a derived class.The set
Q4. What are void pointers?
A void pointer is a pointer that has no associated data type with it. A void pointer can hold an address of any type and can be typecasted to any type.
Q5. What is a copy constructor?
A copy constructor is a member function that initializes an object using another object of the same class. In simple terms, a constructor that creates an object by initializing it with an object of the same class, which has been created previously is known as a copy constructor.
Q6. What are access specifiers? What is their significance in OOPs?
Access specifiers are special keywords used to specify or control the accessibility of entities like classes, methods, and so on. Private, Public, and Protected are examples of access specifiers or access modifiers.
These access specifiers largely achieve the key components of OOPs, encapsulation, and data hiding.
Q7. What are the different types of Polymorphism?
Polymorphism can be classified into two types based on the time when the call to the object or function is resolved. They are as follows:
- Compile Time Polymorphism : Compile time polymorphism, also known as static polymorphism or early binding is the type of polymorphism where the binding of the call to its code is done at the compile time. Method overloading or operator overloading are examples of compile-time polymorphism.
- Runtime Polymorphism: Method overriding is one of the ways in which Java supports Runtime Polymorphism. Dynamic method dispatch is the mechanism by which a call to an overridden method is resolved at run time, rather than compile time.
 types of Polymorphism
types of Polymorphism
Q8. What is database normalization?
It is a process of analyzing the given relation schemas based on their functional dependencies and primary keys to achieve the following desirable properties:
1. Minimizing Redundancy
2. Minimizing the Insertion, Deletion, And Update Anomalies Relation schemas that do not meet the properties are decomposed into smaller relation schemas that could meet desirable properties.
Q9. What is a transaction? What are ACID properties?
A Database Transaction is a set of database operations that must be treated as a whole, which means either all operations are executed or none of them. An example can be a bank transaction from one account to another account. Either both debit and credit operations must be executed or none of them. ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably.
Q10. What is Data Warehousing?
A Data Warehouse is separate from DBMS, it stores a huge amount of data, which is typically collected from multiple heterogeneous sources like files, DBMS, etc. The goal is to produce statistical results that may help in decision-making. For example, a college might want to see quick different results, like how the placement of CS students has improved over the last 10 years, in terms of salaries, counts, etc.
Q11. Types of Keys in Relational Model (Candidate, Super, Primary, Alternate and Foreign)
Keys are one of the basic requirements of a relational database model. It is widely used to identify the tuples(rows) uniquely in the table.
Different Types of Database Keys
- Candidate Key: The minimal set of attributes that can uniquely identify a tuple is known as a candidate key. For Example, STUD_NO in STUDENT relation.
- Primary Key: There can be more than one candidate key in relation out of which one can be chosen as the primary key. For Example, STUD_NO, as well as STUD_PHONE, are candidate keys for relation STUDENT but STUD_NO can be chosen as the primary key (only one out of many candidate keys).
- Super Key: The set of attributes that can uniquely identify a tuple is known as Super Key. For Example, STUD_NO, (STUD_NO, STUD_NAME), etc. A super key is a group of single or multiple keys that identifies rows in a table. It supports NULL values.
- Alternate Key: The candidate key other than the primary key is called an alternate key.
- Foreign Key: If an attribute can only take the values that are present as values of some other attribute, it will be a foreign key to the attribute to which it refers.
- Composite Key: Sometimes, a table might not have a single column/attribute that uniquely identifies all the records of a table. To uniquely identify rows of a table, a combination of two or more columns/attributes can be used.
Q12. Difference Between Clustered and Non-Clustered Index
| A clustered index is faster. |
A non-clustered index is slower. |
| The clustered index requires less memory for operations. |
A non-Clustered index requires more memory for operations. |
| In a clustered index, the clustered index is the main data. |
In the Non-Clustered index, the index is the copy of data. |
| A table can have only one clustered index. |
A table can have multiple non-clustered indexes. |
Q13. What is a View?
Views in SQL are a kind of virtual table. A view also has rows and columns as they are in a real table in the database. We can create a view by selecting fields from one or more tables present in the database. A View can either have all the rows of a table or specific rows based on certain conditions.
Q14. What is thread in OS?
A thread is a single sequence stream within a process. Threads are also called lightweight processes as they possess some of the properties of processes. Each thread belongs to exactly one process. In an operating system that supports multithreading, the process can consist of many threads
Q15. Difference Between Paging and Segmentation
| In paging, the program is divided into fixed or mounted-size pages. |
In segmentation, the program is divided into variable-size sections. |
| The paging operating system is accountable. |
For segmentation compiler is accountable. |
| Page size is determined by hardware. |
Here, the section size is given by the user. |
| It is faster in comparison to segmentation. |
Segmentation is slow. |
| Paging could result in internal fragmentation. |
Segmentation could result in external fragmentation. |
Q16. What is caching?
It is the process of storing and accessing data from memory(i.e. cache memory). The main feature of caching is to reduce the time to access specific data. Caching aims at storing data that can be helpful in the future.
Q17. Types of Network Topology
Types of Network Topology
The arrangement of a network that comprises nodes and connecting lines via sender and receiver is referred to as Network Topology. The various network topologies are:
- Point to Point Topology
- Mesh Topology
- Star Topology
- Bus Topology
- Ring Topology
- Tree Topology
- Hybrid Topology
Q18. What is a VPN?
VPN stands for the virtual private network. A virtual private network (VPN) is a technology that creates a safe and encrypted connection over a less secure network, such as the Internet. A Virtual Private Network is a way to extend a private network using a public network such as the Internet.
Q19. What is IP Spoofing?
IP Spoofing is essentially a technique used by hackers to gain unauthorized access to Computers. Concepts of IP Spoofing were initially discussed in academic circles as early as 1980. IP Spoofing types of attacks had been known to Security experts on the theoretical level.
Q20. Queries to check if string B exists as substring in string A
A simple approach will be to compare the strings character by character for every query which will take O(length(B)) time to answer each query.
Q21. Decode a string recursively encoded as count followed by substring
The idea is to use two stacks, one for integers and another for characters.
Now, traverse the string,
- Whenever we encounter any number, push it into the integer stack, and in case of any alphabet (a to z) or open bracket (‘[‘), push it onto the character stack.
- Whenever any close bracket (‘]’) is encountered pop the character from the character stack until an open bracket (‘[‘) is not found in the character stack. Also, pop the top element from the integer stack, say n. Now make a string repeating the popped character n number of times. Now, push all characters of the string in the stack.
Q22. Tree Traversal
Algorithm Inorder(tree)
- Traverse the left subtree, i.e., call Inorder(left->subtree)
- Visit the root.
- Traverse the right subtree, i.e., call Inorder(right->subtree)
Algorithm Preorder(tree)
- Visit the root.
- Traverse the left subtree, i.e., call Preorder(left->subtree)
- Traverse the right subtree, i.e., call Preorder(right->subtree)
Algorithm Postorder(tree)
- Traverse the left subtree, i.e., call Postorder(left->subtree)
- Traverse the right subtree, i.e., call Postorder(right->subtree)
- Visit the root
For each node, first, the node is visited and then it’s child nodes are put in a FIFO queue. Then again the first node is popped out and then it’s child nodes are put in a FIFO queue and repeat until the queue becomes empty.
Q23. Minimum number of jumps to reach end
Start from the first element and recursively call for all the elements reachable from the first element. The minimum number of jumps to reach the end from first can be calculated using the minimum value from the recursive calls.
minJumps(start, end) = 1 + Min(minJumps(k, end)) for all k reachable from start.
Q24. Subarray with given sum
The idea is to consider all subarrays one by one and check the sum of every subarray.
Run two loops: the outer loop picks a starting point i and the inner loop tries all subarrays starting from I.
Q25. Detect loop or cycle in a linked list
The idea is to insert the nodes in the hashmap and whenever a node is encountered that is already present in the hashmap then return true.
Q26. Reverse a Linked List
Follow the steps below to solve the problem:
- Initialize three pointers prev as NULL, curr as head, and next as NULL.
- Iterate through the linked list. In a loop, do the following:
- Before changing the next of curr, store the next node
- Now update the next pointer of curr to the prev
- Update prev as curr and curr as next
Q27. Check if a pair with given Sum exists in the Array
The idea is to use the two-pointer technique. But for using the two-pointer technique, the array must be sorted. Once the array is sorted the two pointers can be taken which mark the beginning and end of the array respectively. If the sum is greater than the sum of those two elements, shift the right pointer to decrease the value of the required sum and if the sum is lesser than the required value, shift the left pointer to increase the value of the required sum.
Q29. Sort an array of 0s, 1s and 2s
- The problem is similar tosolve
- The problem was posed with three colors, here `0′, `1′ and `2′. The array is divided into four sections:
- arr[1] to arr[low – 1]
- arr[low] to arr[mid – 1]
- arr[mid] to arr[high – 1]
- arr[high] to arr[n]
- If the ith element is 0 then swap the element to the low range.
- Similarly, if the element is 1 then keep it as it is.
- If the element is 2 then swap it with an element in high range.
Q30. Binary Search
In this algorithm,
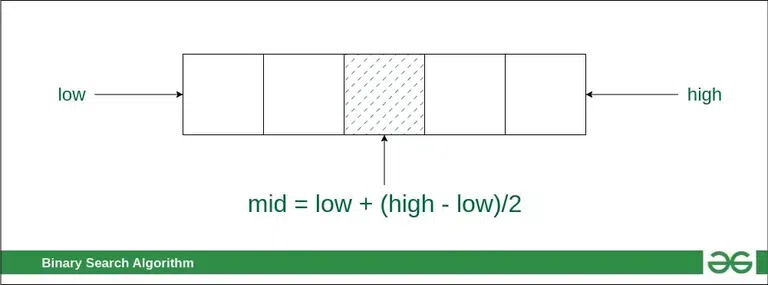 Binary Search
Binary Search
- Compare the middle element of the search space with the key.
- If the key is found at middle element, the process is terminated.
- If the key is not found at middle element, choose which half will be used as the next search space.
- If the key is smaller than the middle element, then the left side is used for next search.
- If the key is larger than the middle element, then the right side is used for next search.
- This process is continued until the key is found or the total search space is exhausted.
Q31. Length of the longest substring without repeating characters
Length of the longest substring without repeating characters using Binary Search on Answer:
The idea is to check if a substring of a certain size “mid” is valid (A size mid is valid if there exists atleast one substring of size mid which contains all unique characters ), then all the size less than “mid” will also be valid. Similarly, if a substring of size “mid” is not valid(A size mid is not valid if there does not exists any substring of size mid which contains all unique characters ), then all the size larger than “mid” will also not be valid. This allows us to apply binary search effectively.
Q32. Remove Duplicates from an Unsorted Linked List
Remove duplicates from an Unsorted Linked List using Hashing:
The idea for this approach is based on the following observations:
- Traverse the link list from head to end.
- For every newly encountered element, check whether if it is in the hash table:
- if yes, remove it
- otherwise put it in the hash table.
- At the end, the Hash table will contain only the unique elements.
Q33. Count All Palindromic Subsequence in a given String
Initial Values : i= 0, j= n-1;
CountPS(i,j)
// Every single character of a string is a palindrome
// subsequence
if i == j
return 1 // palindrome of length 1
// If first and last characters are same, then we
// consider it as palindrome subsequence and check
// for the rest subsequence (i+1, j), (i, j-1)
Else if (str[i] == str[j])
return countPS(i+1, j) + countPS(i, j-1) + 1;
else
// check for rest sub-sequence and remove common
// palindromic subsequences as they are counted
// twice when we do countPS(i+1, j) + countPS(i,j-1)
return countPS(i+1, j) + countPS(i, j-1) – countPS(i+1, j-1)
Q34. Binary Tree to DLL
The idea is to do in-order traversal of the binary tree. While doing inorder traversal, keep track of the previously visited node in a variable, say prev. For every visited node, make it next to the prev and set previous of this node as prev.
Q35. Count the Zeros
Since the input array is sorted, we can use Binary Search to find the first occurrence of 0. Once we have the index of the first element, we can return count as n – index of the first zero.
Q36. Difference between List, Set and Map in Java
|
The list interface allows duplicate elements
|
Set does not allow duplicate elements.
|
The map does not allow duplicate elements
|
|
The list maintains insertion order.
|
Set do not maintain any insertion order.
|
The map also does not maintain any insertion order.
|
|
We can add any number of null values.
|
But in set almost only one null value.
|
The map allows a single null key at most and any number of null values.
|
|
List implementation classes are Array List, LinkedList.
|
Set implementation classes are HashSet, LinkedHashSet, and TreeSet.
|
Map implementation classes are HashMap, HashTable, TreeMap, ConcurrentHashMap, and LinkedHashMap.
|
|
The list provides get() method to get the element at a specified index.
|
Set does not provide get method to get the elements at a specified index
|
The map does not provide get method to get the elements at a specified index
|
Q37. Majority Element
The basic solution is to have two loops and keep track of the maximum count for all different elements. If the maximum count becomes greater than n/2 then break the loops and return the element having the maximum count. If the maximum count doesn’t become more than n/2 then the majority element doesn’t exist.
P.S: To check the Virtusa Experiences and other asked questions go through the attached link
Share your thoughts in the comments
Please Login to comment...