Working with large CSV files in Python
Last Updated :
12 Mar, 2024
Data plays a key role in building machine learning and the AI model. In today’s world where data is being generated at an astronomical rate by every computing device and sensor, it is important to handle huge volumes of data correctly. One of the most common ways of storing data is in the form of Comma-Separated Values(CSV). Directly importing a large amount of data leads to out-of-memory error and reading the entire file at once leads to system crashes due to insufficient RAM.
Working with large CSV files in Python
The following are a few ways to effectively handle large data files in .csv format and read large CSV files in Python. The dataset we are going to use is gender_voice_dataset.
- Using pandas.read_csv(chunk size)
- Using Dask
- Use Compression
Read large CSV files in Python Pandas Using pandas.read_csv(chunk size)
One way to process large files is to read the entries in chunks of reasonable size and read large CSV files in Python Pandas, which are read into the memory and processed before reading the next chunk. We can use the chunk size parameter to specify the size of the chunk, which is the number of lines. This function returns an iterator which is used to iterate through these chunks and then processes them. Since only a part of the file is read at a time, low memory is enough for processing.
The following is the code to read entries in chunks.
chunk = pandas.read_csv(filename,chunksize=...)
The below code shows the time taken to read a dataset without using chunks:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time = time.time()
df = pd.read_csv("gender_voice_dataset.csv")
e_time = time.time()
print("Read without chunks: ", (e_time-s_time), "seconds")
# data
df.sample(10)
Output:
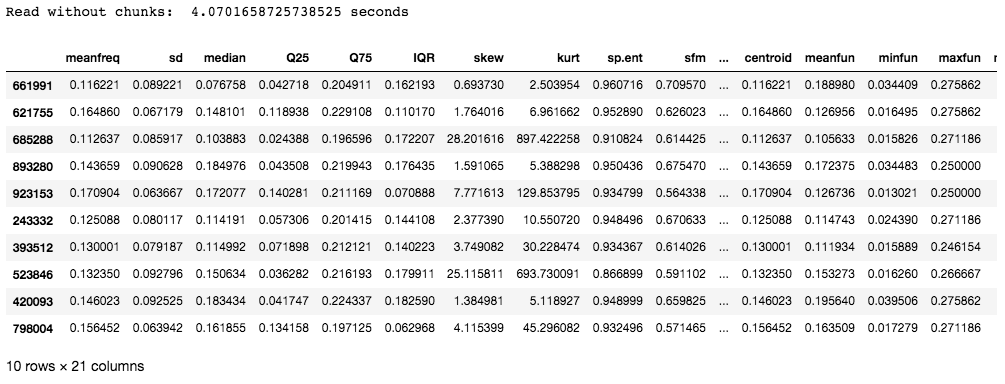
The data set used in this example contains 986894 rows with 21 columns. The time taken is about 4 seconds which might not be that long, but for entries that have millions of rows, the time taken to read the entries has a direct effect on the efficiency of the model.
Now, let us use chunks to read the CSV file:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time_chunk = time.time()
chunk = pd.read_csv('gender_voice_dataset.csv', chunksize=1000)
e_time_chunk = time.time()
print("With chunks: ", (e_time_chunk-s_time_chunk), "sec")
df = pd.concat(chunk)
# data
df.sample(10)
Output:
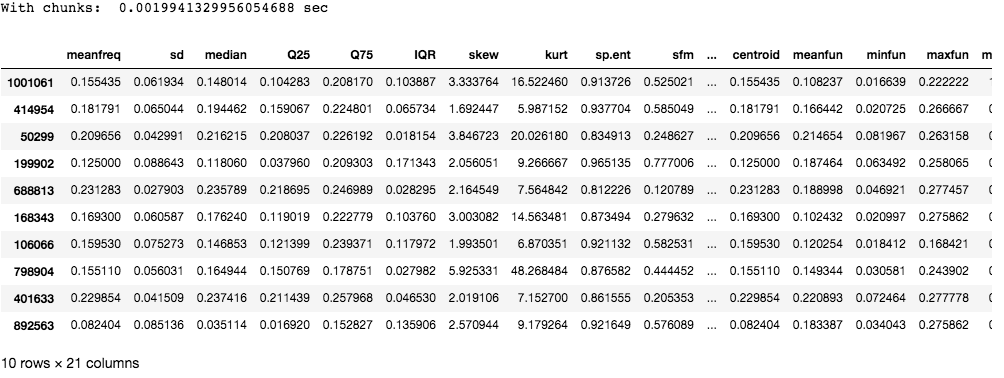
As you can see chunking takes much lesser time compared to reading the entire file at one go.
Read large CSV files in Python Pandas Using Dask
Dask is an open-source python library that includes features of parallelism and scalability in Python by using the existing libraries like pandas, NumPy, or sklearn.
To install:
pip install dask
Dask is preferred over chunking as it uses multiple CPU cores or clusters of machines (Known as distributed computing). In addition to this, it also provides scaled NumPy, pandas, and sci-kit libraries to exploit parallelism. The following is the code to read files using dask:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
from dask import dataframe as df1
# time taken to read data
s_time_dask = time.time()
dask_df = df1.read_csv('gender_voice_dataset.csv')
e_time_dask = time.time()
print("Read with dask: ", (e_time_dask-s_time_dask), "seconds")
# data
dask_df.head(10)
Output:
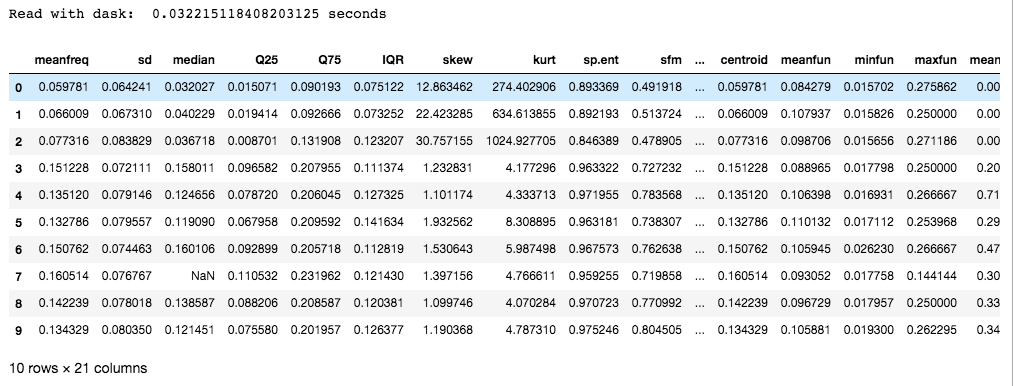
Read large CSV files in Python Pandas Using Compression
Compression method in Pandas’ `read_csv` allows you to read compressed CSV files efficiently. Specify the compression type (e.g., ‘gzip’, ‘zip’, ‘xz’) with the `compression` parameter. To enable this feature, ensure the required library is installed using below command `pip install ‘library_name’` Example :
pip install gzip
In this example , below Python code uses Pandas Dataframe to read a large CSV file in chunks, prints the shape of each chunk, and displays the data within each chunk, handling potential file not found or unexpected errors.
Python3
import pandas as pd
chunk_size = 1000
compression_type = None # Set to None for non-compressed files
file_path = '/content/drive/MyDrive/voice.csv'
try:
chunk_iterator = pd.read_csv(file_path, chunksize=chunk_size, compression=compression_type)
for i, chunk in enumerate(chunk_iterator):
print(f'Chunk {i + 1} shape: {chunk.shape}')
print(chunk) # Print the data in each chunk
except FileNotFoundError:
print(f"Error: File '{file_path}' not found. Please provide the correct file path.")
except Exception as e:
print(f"An unexpected error occurred: {e}")
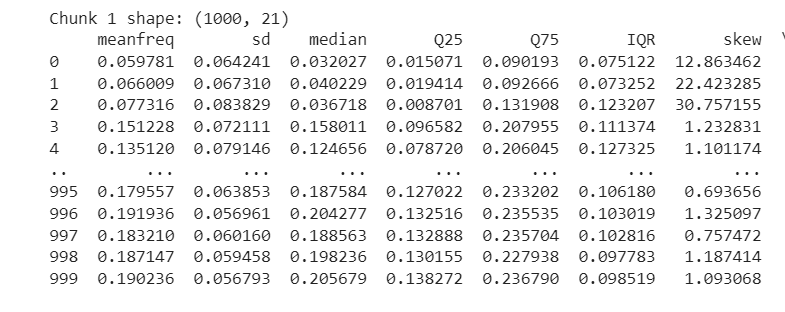
Output :
Note: The dataset in the link has around 3000 rows. Additional data was added separately for the purpose of this article, to increase the size of the file. It does not exist in the original dataset.
Share your thoughts in the comments
Please Login to comment...