Scraping Reddit with Python and BeautifulSoup
Last Updated :
21 Nov, 2022
In this article, we are going to see how to scrape Reddit with Python and BeautifulSoup. Here we will use Beautiful Soup and the request module to scrape the data.
Module needed
- bs4: Beautiful Soup(bs4) is a Python library for pulling data out of HTML and XML files. This module does not come built-in with Python. To install this type the below command in the terminal.
pip install bs4
- requests: Request allows you to send HTTP/1.1 requests extremely easily. This module also does not come built-in with Python. To install this type the below command in the terminal.
pip install requests
Approach:
- Import all the required modules.
- Pass the URL in the getdata function(UDF) to that will request to a URL, it returns a response. We are using the GET method to retrieve information from the given server using a given URL.
Syntax: requests.get(url, args)
- Now Parse the HTML content using bs4.
Syntax: soup = BeautifulSoup(r.content, ‘html5lib’)
Parameters:
- r.content : It is the raw HTML content.
- html.parser : Specifying the HTML parser we want to use.
- Now filter the required data using soup.Find_all function.
Let’s see the stepwise execution of the script.
Step 1: Import all dependence
Python3
import requests
from bs4 import BeautifulSoup
|
Step 2: Create a URL get function
Python3
def getdata(url):
r = requests.get(url, headers = HEADERS)
return r.text
|
Step 3: Now take the URL and pass the URL into the getdata() function and Convert that data into HTML code.
Python3
htmldata = getdata(url)
soup = BeautifulSoup(htmldata, 'html.parser')
print(soup)
|
Output:
Note: This is only HTML code or Raw data.
Getting Author Name
Now find authors with a div tag where class_ =”NAURX0ARMmhJ5eqxQrlQW”. We can open the webpage in the browser and inspect the relevant element by pressing right-click as shown in the figure.
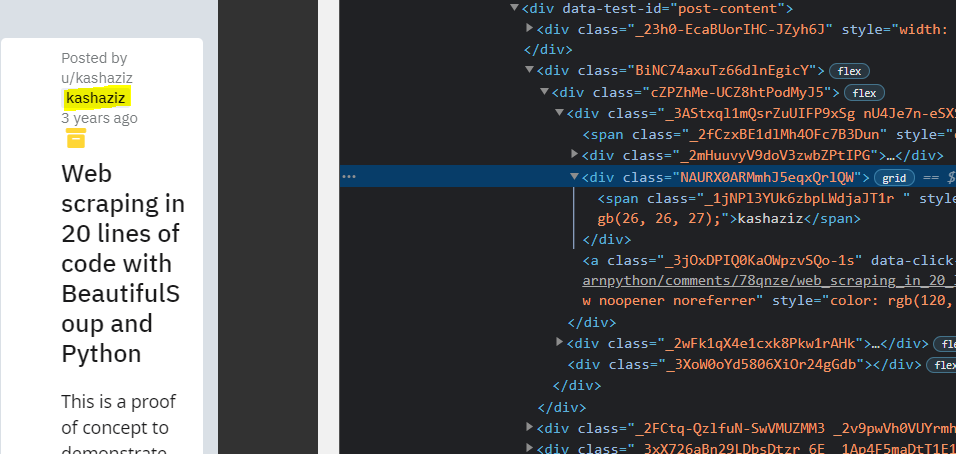
Example:
Python3
data_str = ""
for item in soup.find_all("div", class_="NAURX0ARMmhJ5eqxQrlQW"):
data_str = data_str + item.get_text()
print(data_str)
|
Output:
kashaziz
Getting article contains
Now find the article text, here we will follow the same methods as the above example.
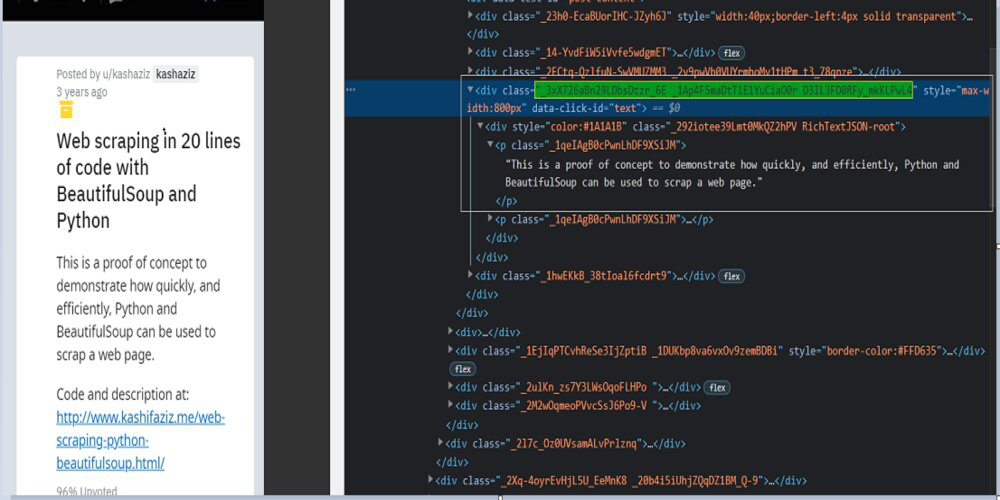
Example:
Python3
data_str = ""
result = ""
for item in soup.find_all("div", class_="_3xX726aBn29LDbsDtzr_6E _1Ap4F5maDtT1E1YuCiaO0r D3IL3FD0RFy_mkKLPwL4"):
data_str = data_str + item.get_text()
print(data_str)
|
Output:

Getting the comments
Now Scrape the comments, here we will follow the same methods as the above example.
Python3
data_str = ""
for item in soup.find_all("p", class_="_1qeIAgB0cPwnLhDF9XSiJM"):
data_str = data_str + item.get_text()
print(data_str)
|
Output:

Share your thoughts in the comments
Please Login to comment...