Scrape LinkedIn Using Selenium And Beautiful Soup in Python
Last Updated :
01 Aug, 2023
In this article, we are going to scrape LinkedIn using Selenium and Beautiful Soup libraries in Python.
First of all, we need to install some libraries. Execute the following commands in the terminal.
pip install selenium
pip install beautifulsoup4
In order to use selenium, we also need a web driver. You can download the web driver of either Internet Explorer, Firefox, or Chrome. In this article, we will be using the Chrome web driver.
Note: While following along with this article, if you get an error, there are most likely 2 possible reasons for that.
- The webpage took too long to load (probably because of a slow internet connection). In this case, use time.sleep() function to provide extra time for the webpage to load. Specify the number of seconds to sleep as per your need.
- The HTML of the webpage has changed from the one when this article was written. If so, you will have to manually select the required webpage elements, instead of copying the element names written below. How to find the element names is explained below. Additionally, don’t decrease the window height and width from the default height and width. It also changes the HTML of the webpage.
Logging in to LinkedIn
Here we will write code for login into Linkedin, First, we need to initiate the web driver using selenium and send a get request to the URL and Identify the HTML document and find the input tags and button tags that accept username/email, password, and sign-in button.
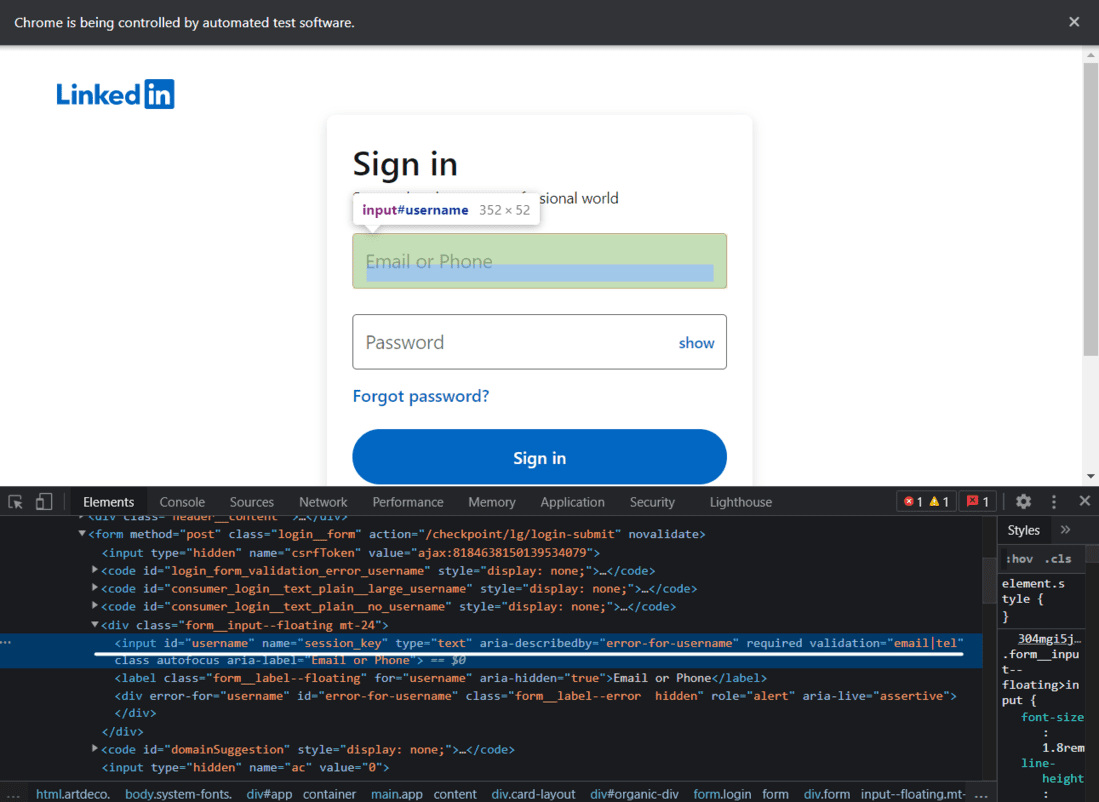
LinkedIn Login Page
Code:
Python3
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome("Enter-Location-Of-Your-Web-Driver")
time.sleep(5)
username = driver.find_element(By.ID, "username")
username.send_keys("User_email")
pword = driver.find_element(By.ID, "password")
pword.send_keys("User_pass")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
|
After executing the above command, you will be logged into your LinkedIn profile. Here is what it would look like.
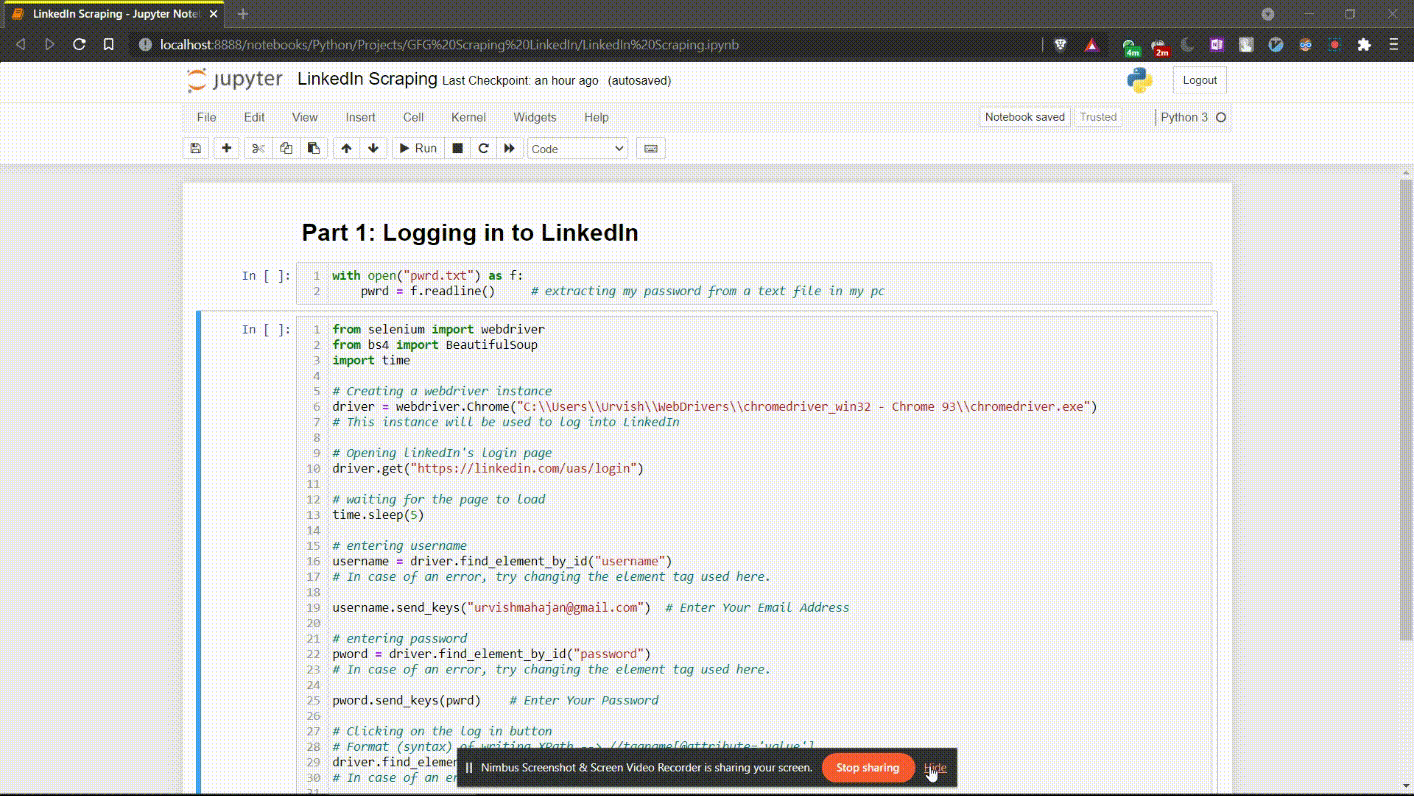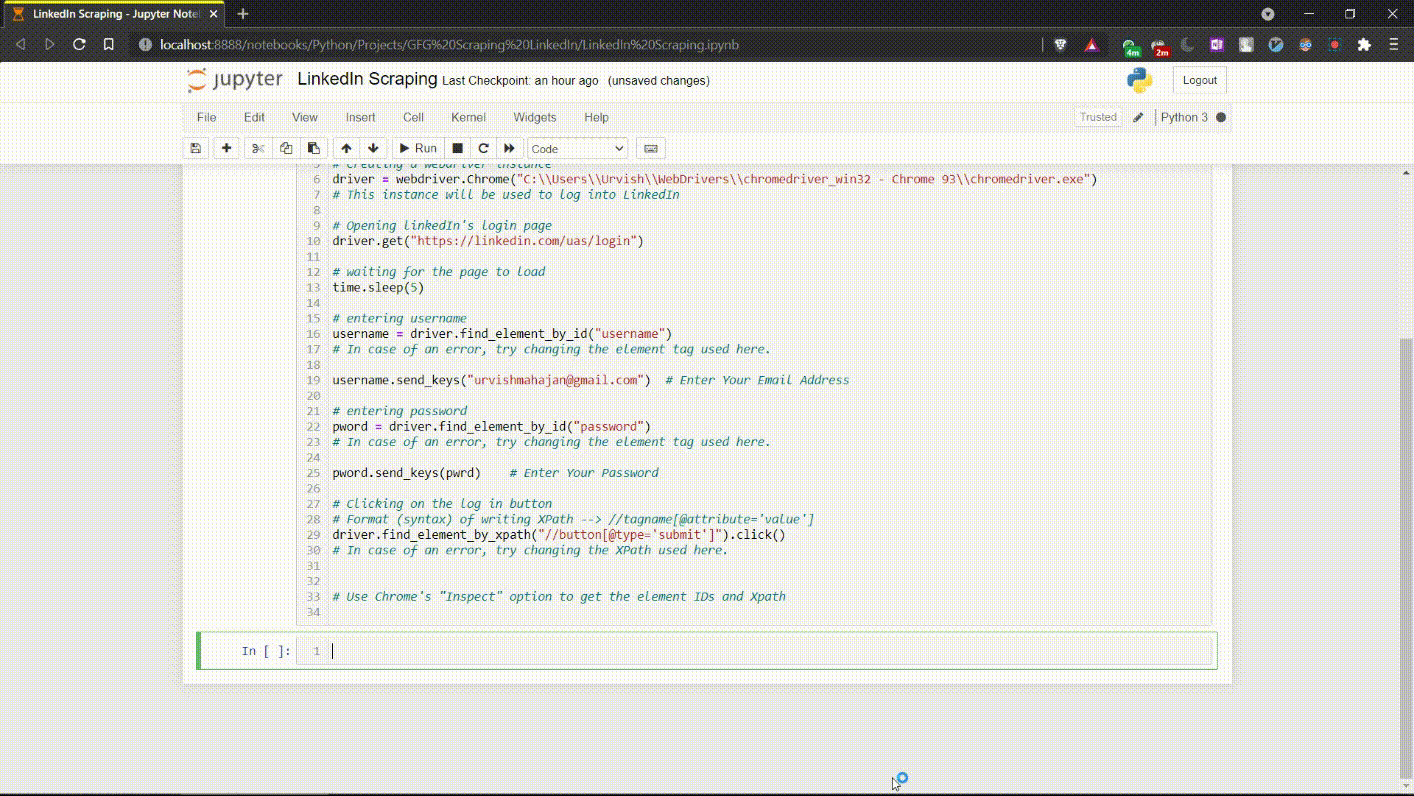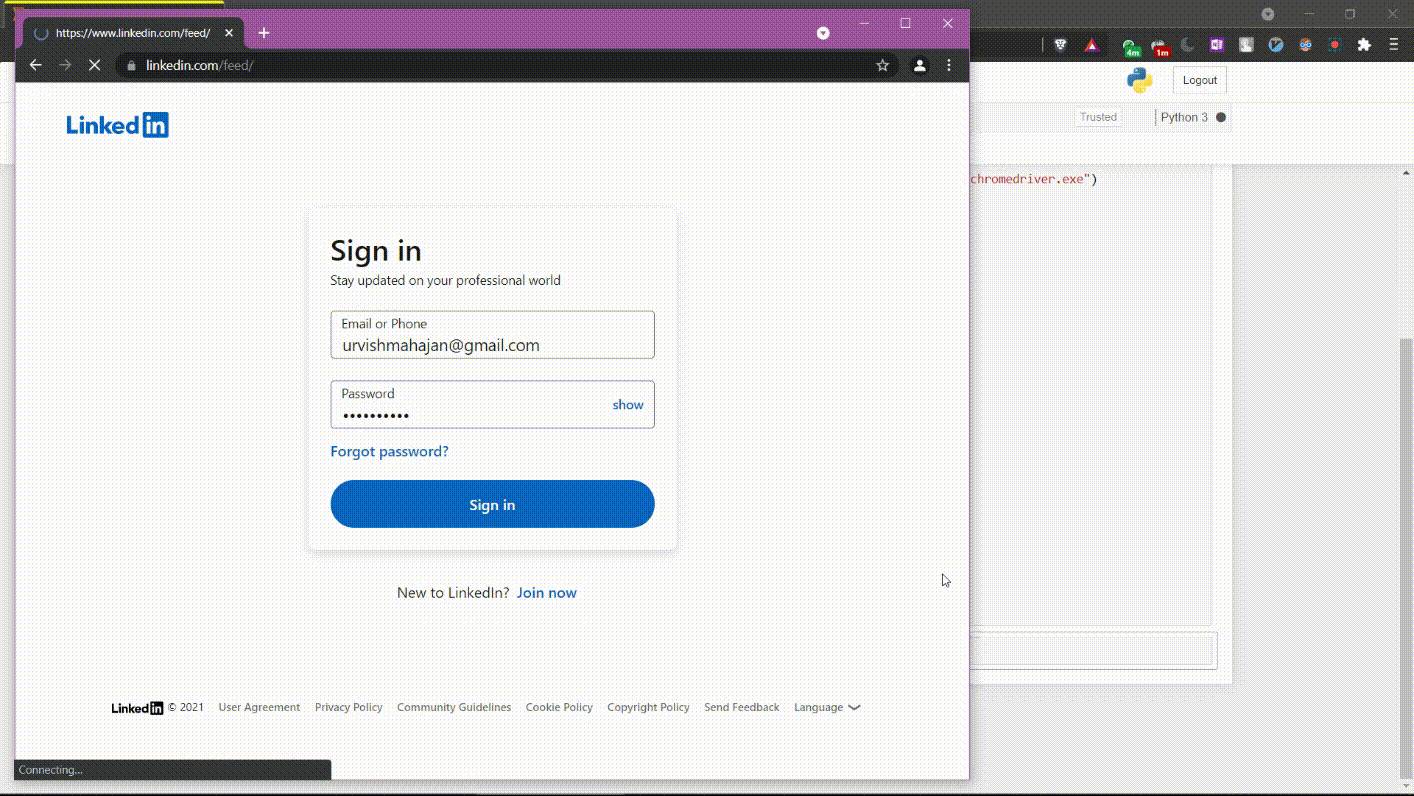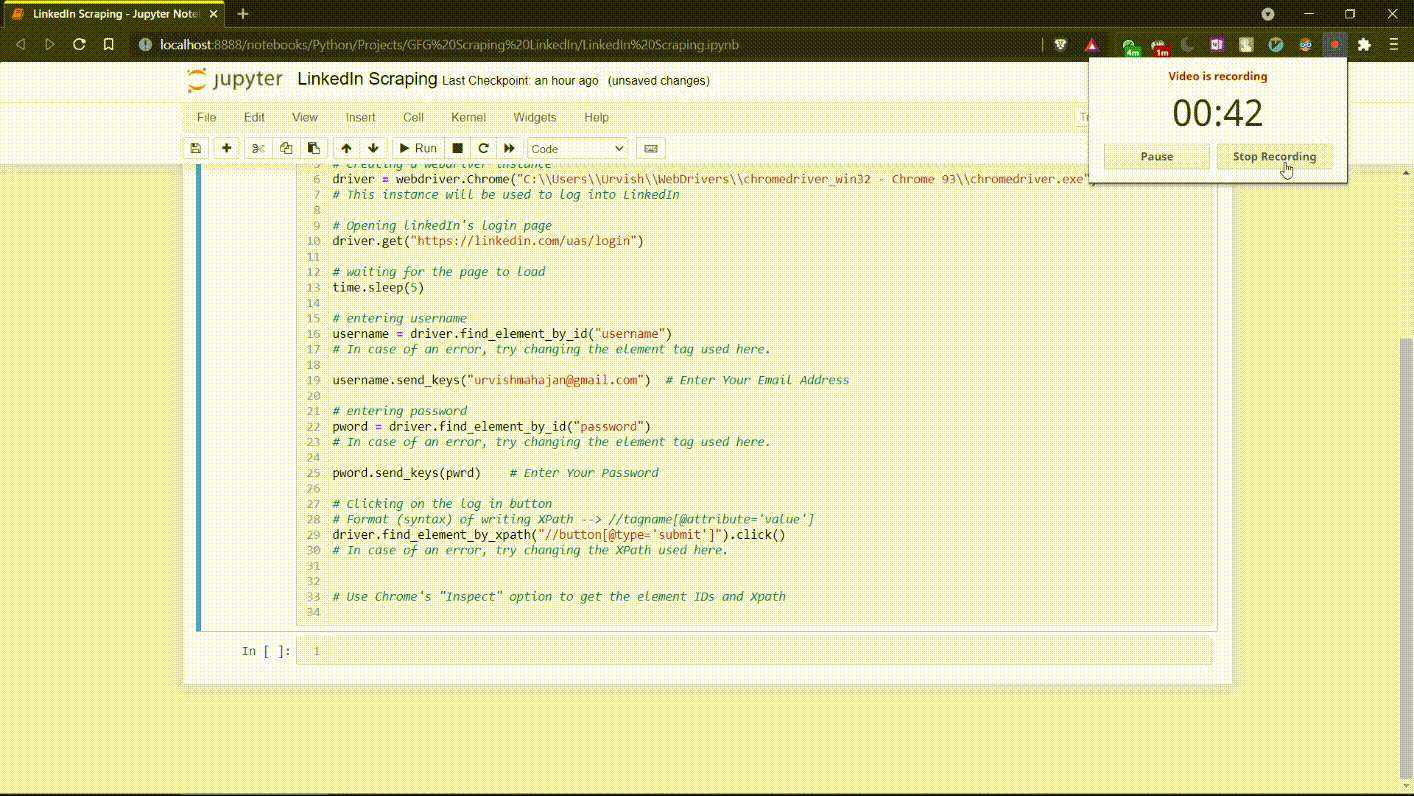
Part 1 Code Execution
Extracting Data From a LinkedIn Profile
Here is the video of the execution of the complete code.
Part 2 Code Execution
2.A) Opening a Profile and Scrolling to the Bottom
Let us say that you want to extract data from Kunal Shah’s LinkedIn profile. First of all, we need to open his profile using the URL of his profile. Then we have to scroll to the bottom of the web page so that the complete data gets loaded.
Python3
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
driver = webdriver.Chrome("Enter-Location-Of-Your-Web-Driver")
time.sleep(5)
username = driver.find_element(By.ID, "username")
username.send_keys("")
pword = driver.find_element(By.ID, "password")
pword.send_keys("")
driver.find_element(By.XPATH, "//button[@type='submit']").click()
driver.get(profile_url)
|
Output:
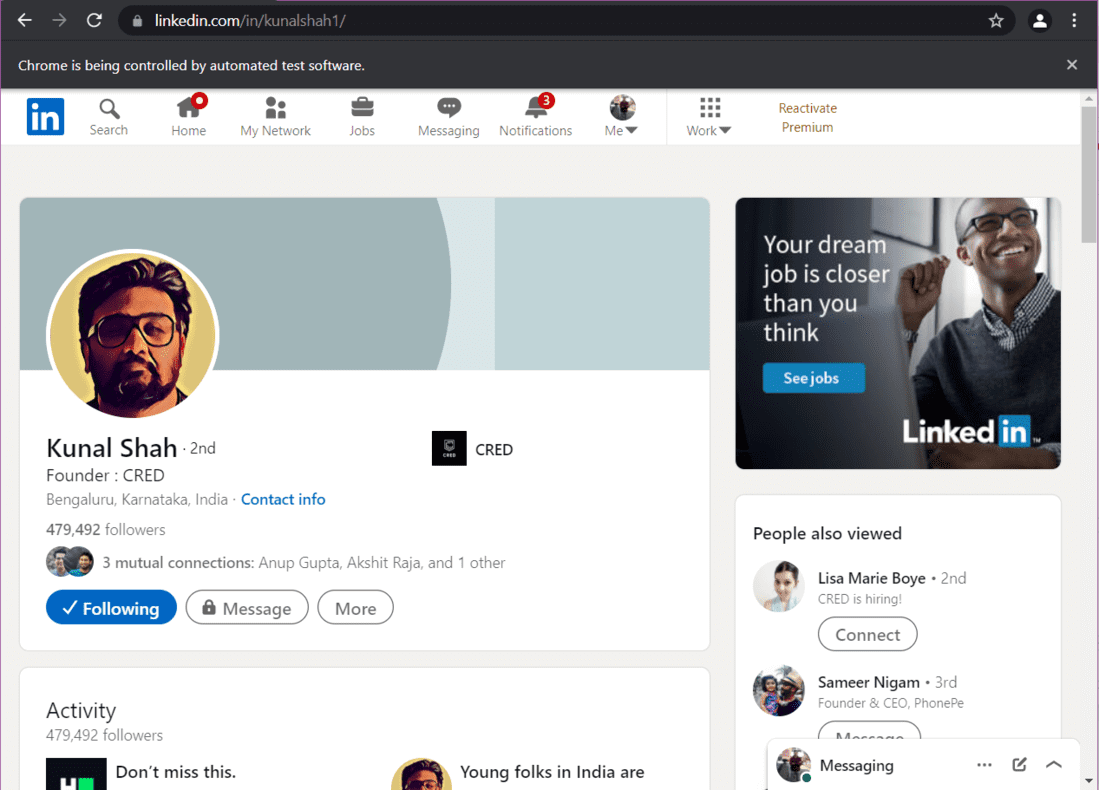
Kunal Shah – LinkedIn Profile
Now, we need to scroll to the bottom. Here is the code to do that:
Python3
start = time.time()
initialScroll = 0
finalScroll = 1000
while True:
driver.execute_script(f"window.scrollTo({initialScroll},
{finalScroll})
")
initialScroll = finalScroll
finalScroll += 1000
time.sleep(3)
end = time.time()
if round(end - start) > 20:
break
|
The page is now scrolled to the bottom. As the page is completely loaded, we will scrape the data we want.
Extracting Data from the Profile
To extract data, firstly, store the source code of the web page in a variable. Then, use this source code to create a Beautiful Soup object.
Python3
src = driver.page_source
soup = BeautifulSoup(src, 'lxml')
|
Extracting Profile Introduction:
To extract the profile introduction, i.e., the name, the company name, and the location, we need to find the source code of each element. First, we will find the source code of the div tag that contains the profile introduction.
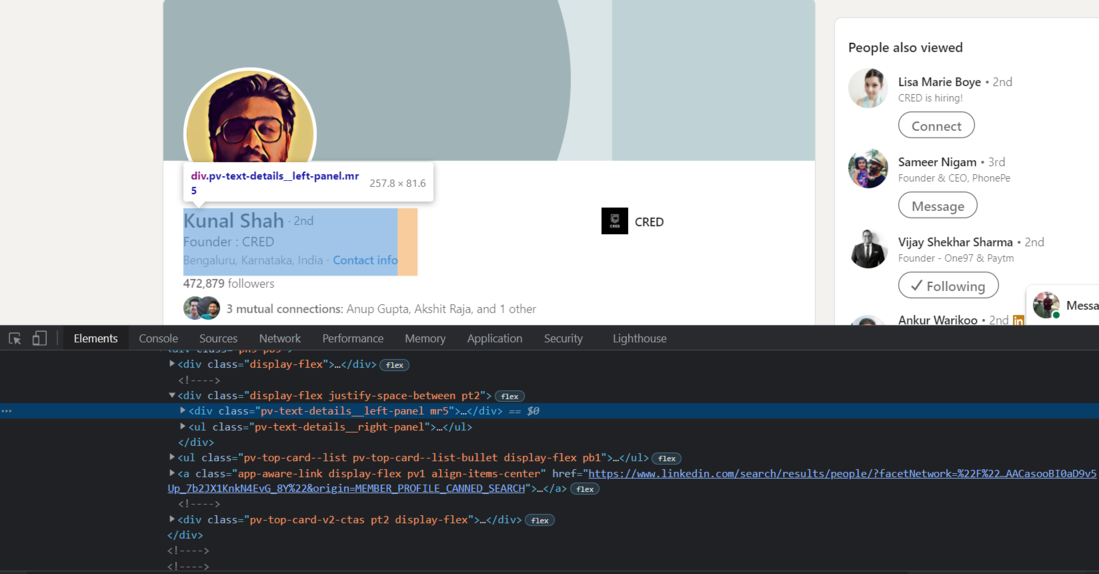
Chrome – Inspect Elements
Now, we will use Beautiful Soup to import this div tag into python.
Python3
intro = soup.find('div', {'class': 'pv-text-details__left-panel'})
print(intro)
|
Output:
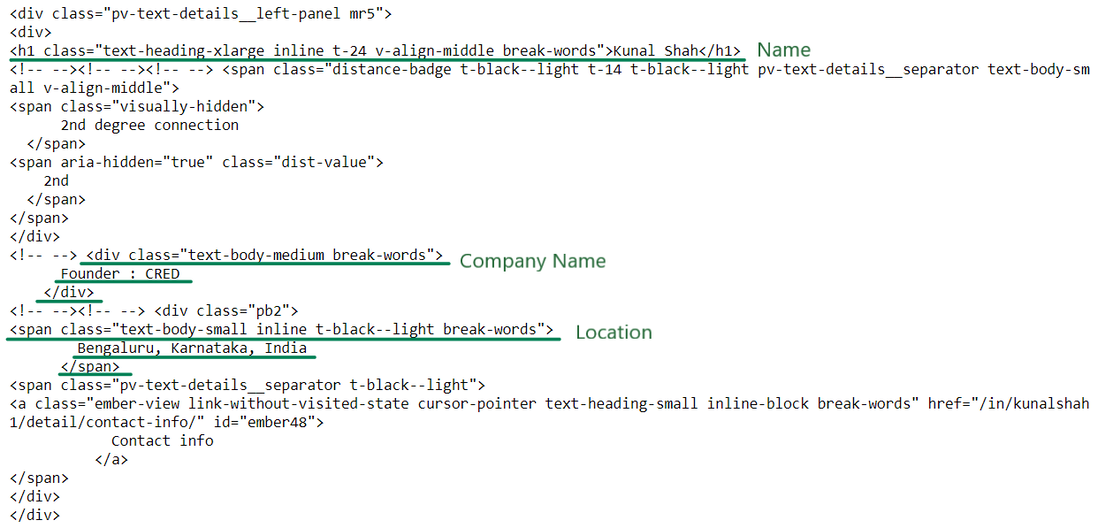
(Scribbled) Introduction HTML
We now have the required HTML to extract the name, company name, and location. Let’s extract the information now:
Python3
name_loc = intro.find("h1")
name = name_loc.get_text().strip()
works_at_loc = intro.find("div", {'class': 'text-body-medium'})
works_at = works_at_loc.get_text().strip()
location_loc = intro.find_all("span", {'class': 'text-body-small'})
location = location_loc[0].get_text().strip()
print("Name -->", name,
"\nWorks At -->", works_at,
"\nLocation -->", location)
|
Output:
Name --> Kunal Shah
Works At --> Founder : CRED
Location --> Bengaluru, Karnataka, India
Extracting Data from the Experience Section
Next, we will extract the Experience from the profile.
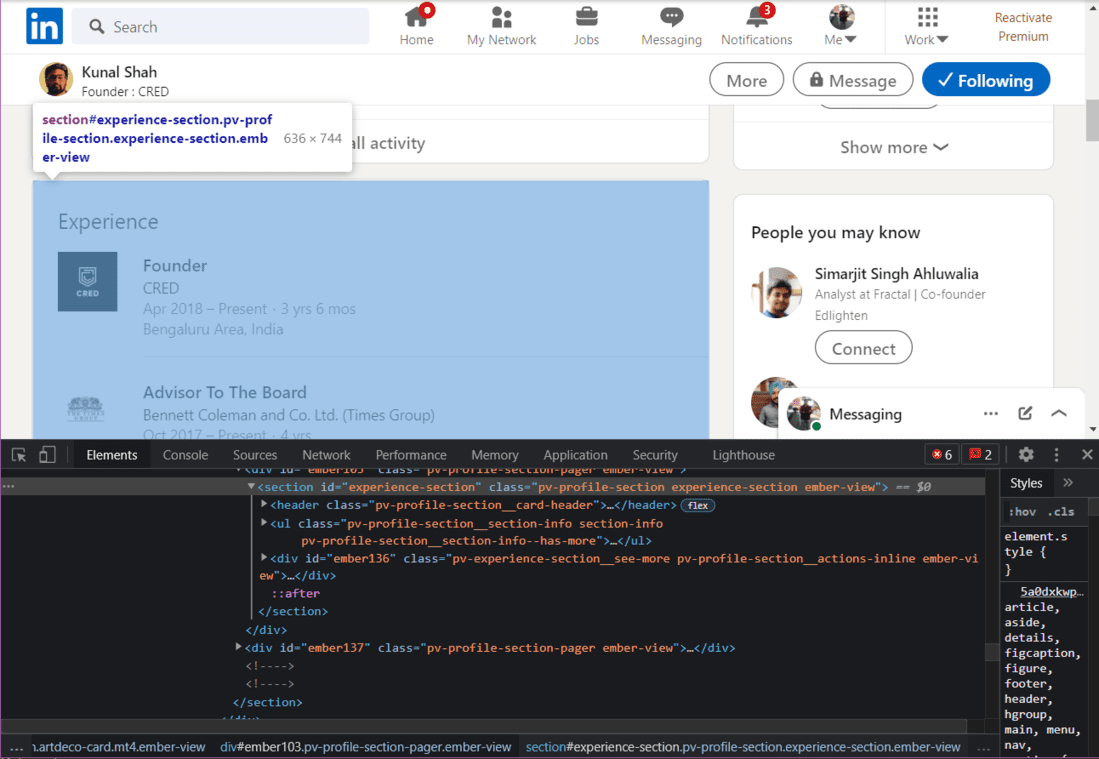
HTML of Experience Section
Python3
experience = soup.find("section", {"id": "experience-section"}).find('ul')
print(experience)
|
Output:
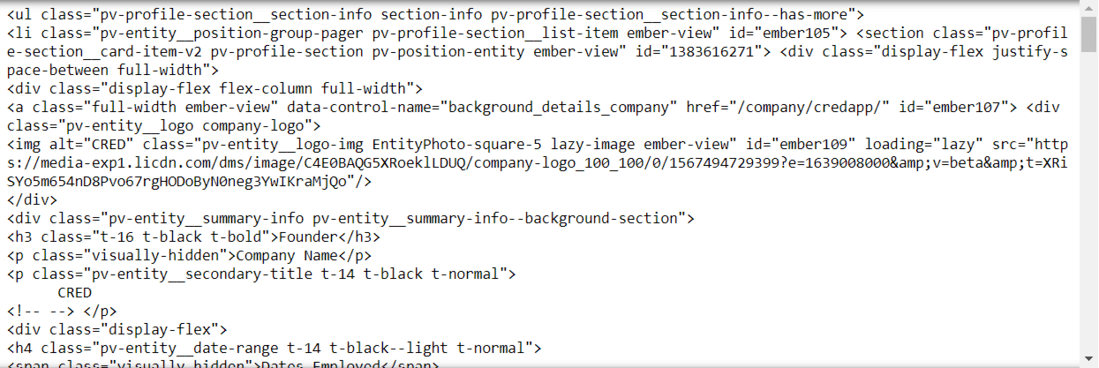
Experience HTML Output
We have to go inside the HTML tags until we find our desired information. In the above image, we can see the HTML to extract the current job title and the name of the company. We now need to go inside each tag to extract the data
Scrape Job Title, company name and experience:
Python3
li_tags = experience.find('div')
a_tags = li_tags.find("a")
job_title = a_tags.find("h3").get_text().strip()
print(job_title)
company_name = a_tags.find_all("p")[1].get_text().strip()
print(company_name)
joining_date = a_tags.find_all("h4")[0].find_all("span")[1].get_text().strip()
employment_duration = a_tags.find_all("h4")[1].find_all(
"span")[1].get_text().strip()
print(joining_date + ", " + employment_duration)
|
Output:
'Founder'
'CRED'
Apr 2018 – Present, 3 yrs 6 mos
Extracting Job Search Data
We will use selenium to open the jobs page.
Python3
jobs = driver.find_element(By.XPATH, "//a[@data-link-to='jobs']/span")
jobs.click()
|
Now that the jobs page is open, we will create a BeautifulSoup object to scrape the data.
Python3
job_src = driver.page_source
soup = BeautifulSoup(job_src, 'lxml')
|
Scrape Job Title:
First of all, we will scrape the Job Titles.
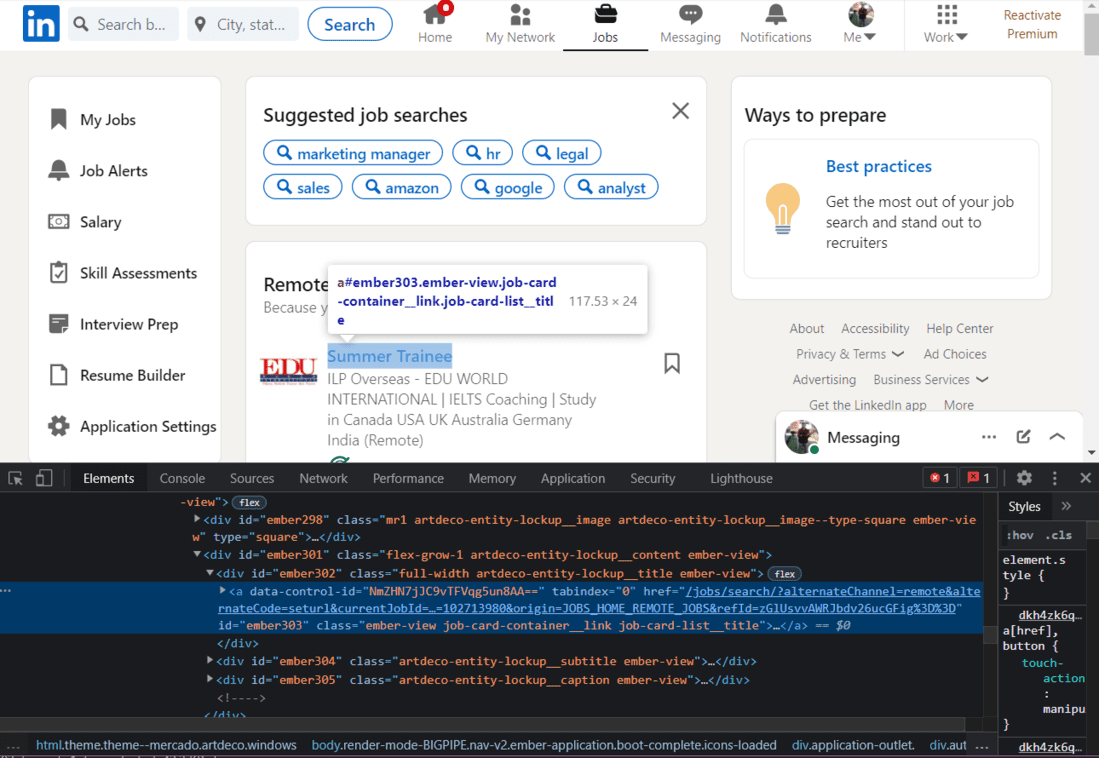
HTML of Job Title
On skimming through the HTML of this page, we will find that each Job Title has the class name “job-card-list__title”. We will use this class name to extract the job titles.
Python3
jobs_html = soup.find_all('a', {'class': 'job-card-list__title'})
job_titles = []
for title in jobs_html:
job_titles.append(title.text.strip())
print(job_titles)
|
Output:

Job Titles List
Scrape Company Name:
Next, we will extract the Company Name.
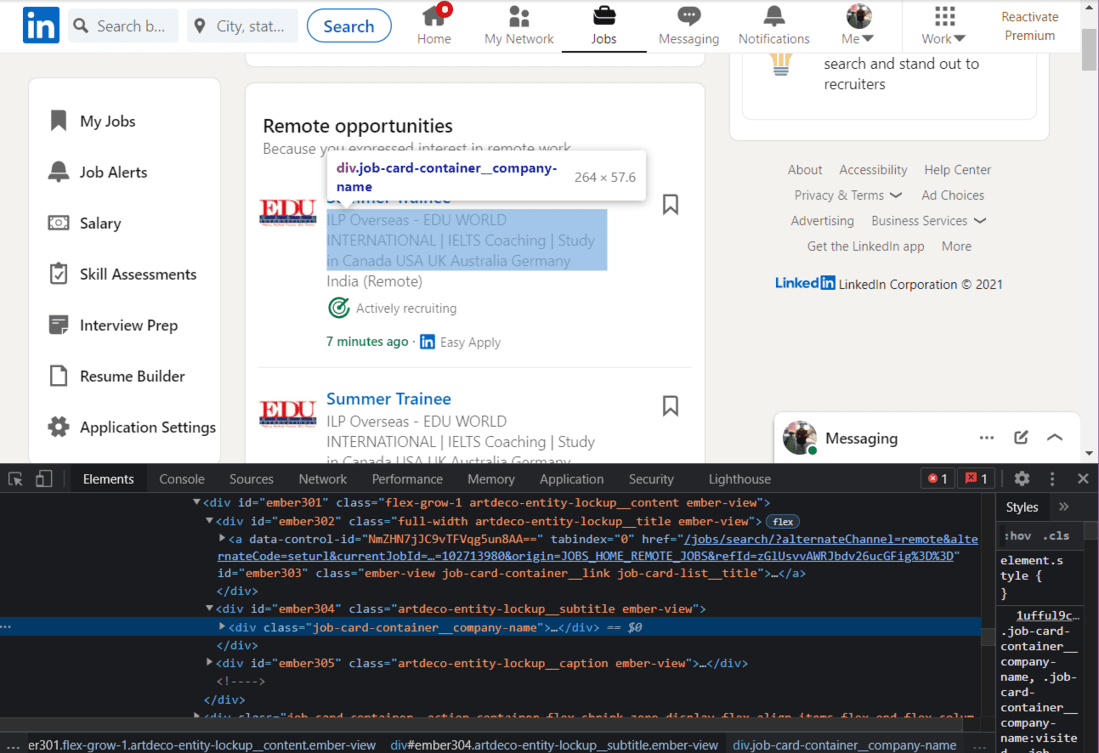
HTML of Company Name
We will use the class name to extract the names of the companies:
Python3
company_name_html = soup.find_all(
'div', {'class': 'job-card-container__company-name'})
company_names = []
for name in company_name_html:
company_names.append(name.text.strip())
print(company_names)
|
Output:

Company Names List
Scrape Job Location:
Finally, we will extract the Job Location.
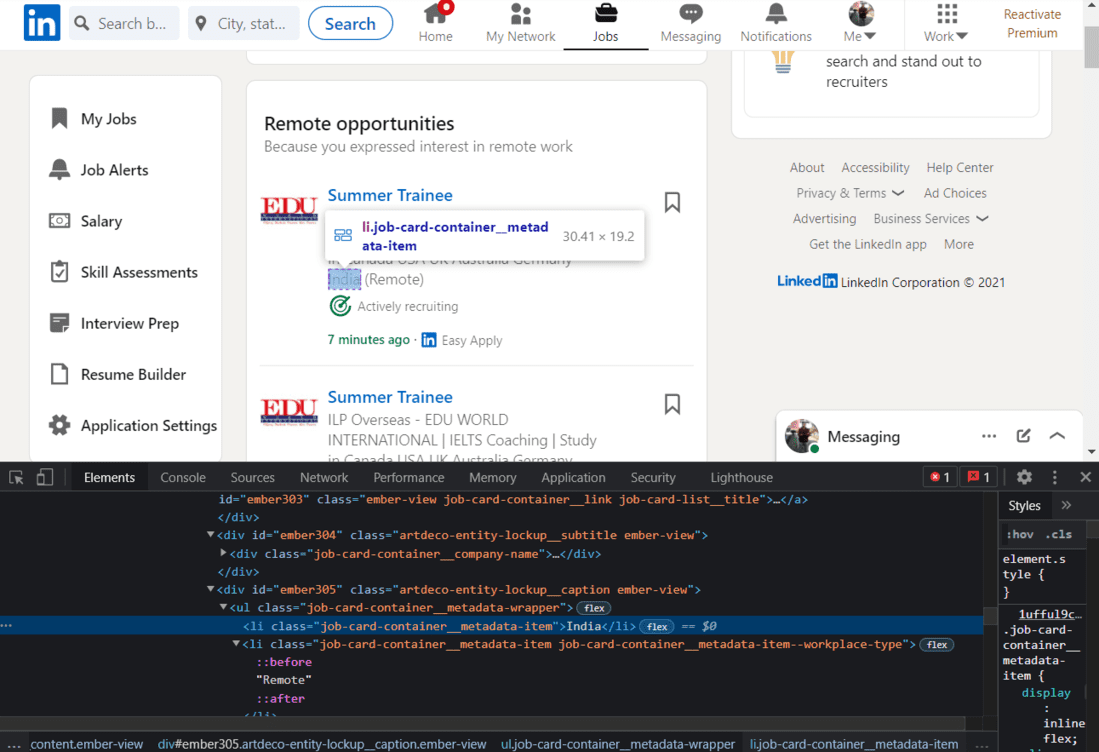
HTML of Job Location
Once again, we will use the class name to extract the location.
Python3
import re
location_html = soup.find_all(
'ul', {'class': 'job-card-container__metadata-wrapper'})
location_list = []
for loc in location_html:
res = re.sub('\n\n +', ' ', loc.text.strip())
location_list.append(res)
print(location_list)
|
Output:

Job Locations List
Share your thoughts in the comments
Please Login to comment...