ML | OPTICS Clustering Explanation
Last Updated :
02 May, 2023
Prerequisites: DBSCAN Clustering OPTICS Clustering stands for Ordering Points To Identify Cluster Structure. It draws inspiration from the DBSCAN clustering algorithm. It adds two more terms to the concepts of DBSCAN clustering.
OPTICS (Ordering Points To Identify the Clustering Structure) is a density-based clustering algorithm, similar to DBSCAN (Density-Based Spatial Clustering of Applications with Noise), but it can extract clusters of varying densities and shapes. It is useful for identifying clusters of different densities in large, high-dimensional datasets.
The main idea behind OPTICS is to extract the clustering structure of a dataset by identifying the density-connected points. The algorithm builds a density-based representation of the data by creating an ordered list of points called the reachability plot. Each point in the list is associated with a reachability distance, which is a measure of how easy it is to reach that point from other points in the dataset. Points with similar reachability distances are likely to be in the same cluster.
The OPTICS algorithm follows these main steps:
Define a density threshold parameter, Eps, which controls the minimum density of clusters.
For each point in the dataset, calculate the distance to its k-nearest neighbors.
Starting with an arbitrary point, calculate the reachability distance of each point in the dataset, based on the density of its neighbors.
Order the points based on their reachability distance and create the reachability plot.
Extract clusters from the reachability plot by grouping points that are close to each other and have similar reachability distances.
One of the main advantage of OPTICS over DBSCAN, is that it does not require to set the number of clusters in advance, instead, it extracts the clustering structure of the data and produces the reachability plot. This allows the user to have more flexibility in selecting the number of clusters, by cutting the reachability plot at a certain point.
Also, unlike other density-based clustering algorithms like DBSCAN, It can handle clusters of different densities and shapes and can identify hierarchical structure.
OPTICS is implemented in Python using the sklearn.cluster.OPTICS class in the scikit-learn library. It takes several parameters including the minimum density threshold (Eps), the number of nearest neighbors to consider (min_samples), and a reachability distance cutoff (xi).
They are:-
- Core Distance: It is the minimum value of radius required to classify a given point as a core point. If the given point is not a Core point, then it’s Core Distance is undefined.
- Reachability Distance: It is defined with respect to another data point q(Let). The Reachability distance between a point p and q is the maximum of the Core Distance of p and the Euclidean Distance(or some other distance metric) between p and q. Note that The Reachability Distance is not defined if q is not a Core point.
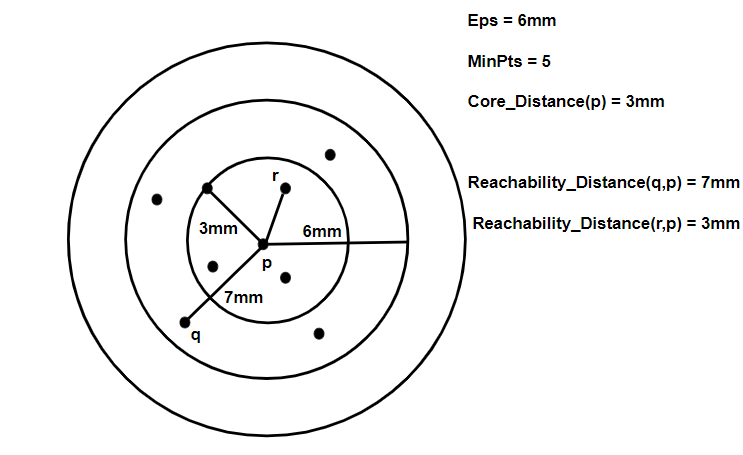 This clustering technique is different from other clustering techniques in the sense that this technique does not explicitly segment the data into clusters. Instead, it produces a visualization of Reachability distances and uses this visualization to cluster the data. Pseudocode: The following Pseudocode has been referred from the Wikipedia page of the algorithm.
This clustering technique is different from other clustering techniques in the sense that this technique does not explicitly segment the data into clusters. Instead, it produces a visualization of Reachability distances and uses this visualization to cluster the data. Pseudocode: The following Pseudocode has been referred from the Wikipedia page of the algorithm.
OPTICS(DB, eps, MinPts)
#Repeating the process for all points in the database
for each point pt of DB
#Initializing the reachability distance of the selected point
pt.reachable_dist = UNDEFINED
for each unprocessed point pt of DB
#Getting the neighbours of the selected point
#according to the definitions of epsilon and
#minPts in DBSCAN
Nbrs = getNbrs(pt, eps)
mark pt as processed
output pt to the ordered list
#Checking if the selected point is not noise
if (core_dist(pt, eps, Minpts) != UNDEFINED)
#Initializing a priority queue to get the closest data point
#in terms of Reachability distance
Seeds = empty priority queue
#Calling the update function
update(Nbrs, pt, Seeds, eps, Minpts)
#Repeating the process for the next closest point
for each next q in Seeds
Nbrs' = getNbrs(q, eps)
mark q as processed
output q to the ordered list
if (core_dist(q, eps, Minpts) != UNDEFINED)
update(Nbrs', q, Seeds, eps, Minpts)
The pseudo-code for the update function is given below:
update(Nbrs, pt, Seeds, eps, MinPts)
#Calculating the core distance for the given point
coredist = core_dist(pt, eps, MinPts)
#Updating the Reachability distance for each neighbour of p
for each obj in Nbrs
if (obj is not processed)
new_reach_distance = max(coredist, dist(pt, obj))
#Checking if the neighbour point is in seeds
if (obj.reachable_dist == UNDEFINED)
#Updation step
obj.reachabled_dist = new_reach_distance
Seeds.insert(obj, new_reach_distance)
else
if (new_reach_distance < obj.reachable_dist)
#Updation step
o.reachable_dist = new_reach_distance
Seeds.move-up(obj, new_reach_distance)
OPTICS Clustering v/s DBSCAN Clustering:
- Memory Cost : The OPTICS clustering technique requires more memory as it maintains a priority queue (Min Heap) to determine the next data point which is closest to the point currently being processed in terms of Reachability Distance. It also requires more computational power because the nearest neighbour queries are more complicated than radius queries in DBSCAN.
- Fewer Parameters : The OPTICS clustering technique does not need to maintain the epsilon parameter and is only given in the above pseudo-code to reduce the time taken. This leads to the reduction of the analytical process of parameter tuning.
- This technique does not segregate the given data into clusters. It merely produces a Reachability distance plot and it is upon the interpretation of the programmer to cluster the points accordingly.
- Handling varying densities: DBSCAN clustering can struggle to handle datasets with varying densities, as it requires a single value of epsilon to define the neighborhood size for all points. In contrast, OPTICS can handle varying densities by using the concept of reachability distance, which adapts to the local density of the data. This means that OPTICS can identify clusters of different sizes and shapes more effectively than DBSCAN in datasets with varying densities.
- Cluster extraction: While both OPTICS and DBSCAN can identify clusters, OPTICS produces a reachability distance plot that can be used to extract clusters at different levels of granularity. This allows for more flexible clustering and can reveal clusters that may not be apparent with a fixed epsilon value in DBSCAN. However, this also requires more manual interpretation and decision-making on the part of the programmer.
- Noise handling: DBSCAN explicitly distinguishes between core points, boundary points, and noise points, while OPTICS does not explicitly identify noise points. Instead, points with high reachability distances can be considered as potential noise points. However, this also means that OPTICS may be less effective at identifying small clusters that are surrounded by noise points, as these clusters may be merged with the noise points in the reachability distance plot.
- Runtime complexity: The runtime complexity of OPTICS is generally higher than that of DBSCAN, due to the use of a priority queue to maintain the reachability distances. However, recent research has proposed optimizations to reduce the computational complexity of OPTICS, making it more scalable for large datasets.
Example :
Python3
from sklearn.cluster import OPTICS
from sklearn import datasets
import numpy as np
iris = datasets.load_iris()
X = iris.data
clustering = OPTICS(min_samples=20, xi=.05, min_cluster_size=.05)
clustering.fit(X)
labels = clustering.labels_
print("Cluster Labels:", labels)
|
Output:
Cluster Labels: [-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1 -1
-1 -1 -1 -1
Share your thoughts in the comments
Please Login to comment...