The article provides a comprehensive understanding of the evolution from basic Convolutional Neural Networks (CNN) to the sophisticated Mask R-CNN, exploring the iterative improvements in object detection, instance segmentation, and the challenges and advantages associated with each model.
What is R-CNN?
R-CNN, which stands for Region-based Convolutional Neural Network, is a type of deep learning model used for object detection in computer vision tasks. The term “R-CNN” actually refers to a family of models that share a common approach to object detection. The key idea behind R-CNN is to divide the object detection task into two stages: region proposal and object classification.
How does R-CNN work?
- Region Proposal Network (RPN): In the first stage, the model generates a set of region proposals that are likely to contain objects. These proposals are potential bounding boxes around objects in the image. The region proposal network is responsible for suggesting these candidate regions.
- Region of Interest (RoI) Pooling: Once the region proposals are generated, each region is cropped from the image and resized to a fixed size. This process is known as RoI pooling, and it ensures that the region of interest is consistently represented in a fixed-size feature map, regardless of the size or aspect ratio of the original region proposal.
- Feature Extraction: The cropped and resized regions are then passed through a pre-trained convolutional neural network (CNN) to extract features from each region.
- Object Classification and Bounding Box Regression: The features extracted from each region are used for two tasks: object classification and bounding box regression. Object classification involves determining the class of the object within the region, and bounding box regression refines the coordinates of the bounding box around the object.
Later, Fast R-CNN was developed to enhance the speed and efficiency of the object detection process. The main issues with R-CNN are its slow training and inference times due to the need to independently process each region proposal using the CNN.
What is Fast R-CNN?
Fast R-CNN is an improved version of R-CNN, which aim to improve the efficiency and speed of the original model with the following additional steps:
- Region Proposal Network (RPN): Fast R-CNN integrates the region proposal step directly into the model. Instead of using an external method (as in the original R-CNN), it employs a Region Proposal Network to generate potential bounding boxes for objects within the image.
- RoI Pooling: After obtaining region proposals, Fast R-CNN uses RoI pooling to extract fixed-size feature maps from the convolutional feature maps. This ensures that the extracted features are consistently sized, regardless of the size or aspect ratio of the original region proposals.
The integration of the region proposal step into the model, along with the use of RoI pooling, makes Fast R-CNN more computationally efficient compared to the original R-CNN. The single-stage training and inference process also contributes to faster training and better overall performance. However, despite its improvements, Fast R-CNN still has room for optimization in terms of speed.
It’s worth noting that there have been subsequent developments in the R-CNN family, such as Mask R-CNN, which further improved speed and addressed additional tasks like instance segmentation.
Instance Segmentation
This segmentation identifies each instance (occurrence of each object present in the image and colors them with different pixels). It basically works to classify each pixel location and generate the segmentation mask for each of the objects in the image. This approach gives more idea about the objects in the image because it preserves the safety of those objects while recognizing them.
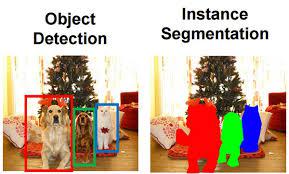
Instance Segmentation
What is Mask R-CNN?
Mask R-CNN (Mask Region-based Convolutional Neural Network) is an extension of the Faster R-CNN architecture that adds a branch for predicting segmentation masks on top of the existing object detection capabilities. It was introduced to address the task of instance segmentation, where the goal is not only to detect objects in an image but also to precisely segment the pixels corresponding to each object instance.
Mask R-CNN Architecture
Mask R-CNN was proposed by Kaiming He et al. in 2017. It is very similar to Faster R-CNN except there is another layer to predict segmented. The stage of region proposal generation is the same in both the architecture the second stage which works in parallel predicts the class generates a bounding box as well as outputs a binary mask for each RoI.
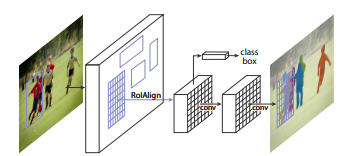
Mask R-CNN Architecture
It comprises of –
- Backbone Network
- Region Proposal Network
- Mask Representation
- RoI Align
Backbone Network
The authors of Mask R-CNN experimented with two kinds of backbone networks. The first is standard ResNet architecture (ResNet-C4) and another is ResNet with a feature pyramid network. The standard ResNet architecture was similar to that of Faster R-CNN but the ResNet-FPN has proposed some modification. This consists of a multi-layer RoI generation. This multi-layer feature pyramid network generates RoI of different scale which improves the accuracy of previous ResNet architecture.
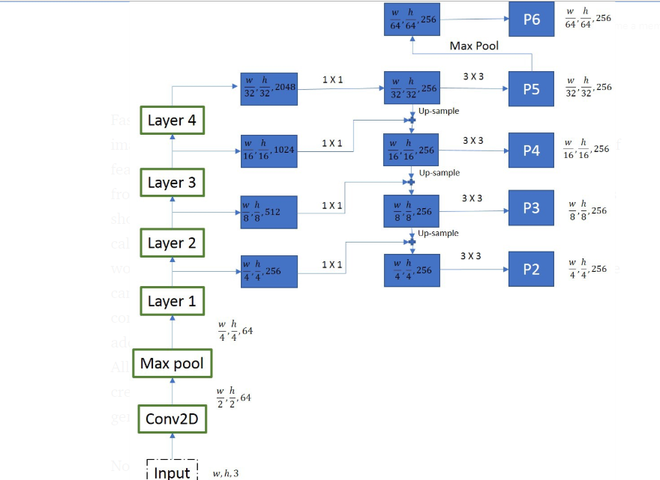
Mask R-CNN backbone architecture
At every layer, the feature map size is reduced by half and the number of feature maps is doubled. We took output from four layers (layers – 1, 2, 3, and 4). To generate final feature maps, we use an approach called the top-bottom pathway. We start from the top feature map(w/32, h/32, 256) and work our way down to bigger ones, by upscale operations. Before sampling, we also apply the 1*1 convolution to bring down the number of channels to 256. This is then added element-wise to the up-sampled output from the previous iteration. All the outputs are subjected to 3 X 3 convolution layers to create the final 4 feature maps(P2, P3, P4, P5). The 5th feature map (P6) is generated from a max pooling operation from P5.
Region Proposal Network
All the convolution feature map that is generated by the previous layer is passed through a 3*3 convolution layer. The output of this is then passed into two parallel branches that determine the objectness score and regress the bounding box coordinates.
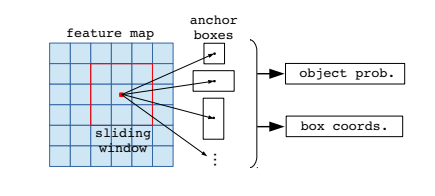
Anchor Generation Mask R-CNN
Here, we only use only one anchor stride and 3 anchor ratios for a feature pyramid (because we already have feature maps of different sizes to check for objects of different sizes).
Mask Representation
A mask contains spatial information about the object. Thus, unlike the classification and bounding box regression layers, we could not collapse the output to a fully connected layer to improve since it requires pixel-to-pixel correspondence from the above layer. Mask R-CNN uses a fully connected network to predict the mask. This ConvNet takes an RoI as input and outputs the m*m mask representation. We also upscale this mask for inference on the input image and reduce the channels to 256 using 1*1 convolution. In order to generate input for this fully connected network that predicts mask, we use RoIAlign. The purpose of RoIAlign is to use convert different-size feature maps generated by the region proposal network into a fixed-size feature map. Mask R-CNN paper suggested two variants of architecture. In one variant, the input of mask generation CNN is passed after RoIAlign is applied (ResNet C4), but in another variant, the input is passed just before the fully connected layer (FPN Network).
This mask generation branch is a full convolution network and it output a K * (m*m), where K is the number of classes (one for each class) and m=14 for ResNet-C4 and 28 for ResNet_FPN.
RoI Align
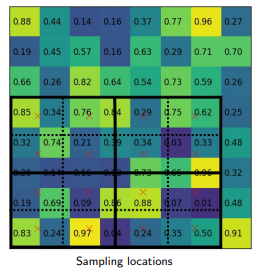
RoI align has the same motive as of RoI pool, to generate the fixed size regions of interest from region proposals. It works in the following steps:
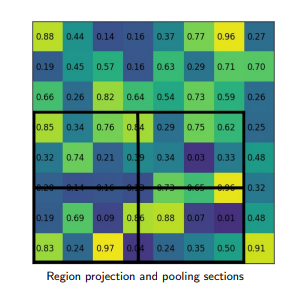
ROI Align
Given the feature map of the previous Convolution layer of size h*w, divide this feature map into M * N grids of equal size (we will NOT just take integer value).
The mask R-CNN inference speed is around 2 fps, which is good considering the addition of a segmentation branch in the architecture.
How does Mask R-CNN work?
As we have seen, Mask R-CNN builds upon the two-stage architecture of Faster R-CNN, incorporating an additional branch to predict segmentation masks for each detected object.
The key innovation in Mask R-CNN is the introduction of a third branch, the mask branch, which operates in parallel with the existing region proposal and classification branches. After the region proposals are generated by the region proposal network (RPN), the mask branch is responsible for predicting a binary mask for each proposed region, outlining the exact pixel-level boundaries of the object. This allows Mask R-CNN not only to identify and classify objects but also to provide a detailed segmentation mask for each instance.
The mask branch uses a pixel-to-pixel alignment mechanism, often implemented with spatially aligned RoI pooling, to ensure accurate correspondence between the proposed region and the generated mask. The final output is a set of bounding boxes, class labels, and pixel-level masks for each detected object in an image.
Advantages of Mask R-CNN
- Precise Instance Segmentation: Mask R-CNN excels at providing accurate pixel-level segmentation masks for each detected object.
- Versatility: It can handle multiple tasks in a single framework.
- Region Proposal Network (RPN): By incorporating an RPN, Mask R-CNN efficiently generates region proposals, allowing it to focus on relevant regions and significantly reducing the computational load compared to exhaustive scanning approaches.
- Flexible Architecture
- State-of-the-Art Performance: Mask R-CNN consistently achieves state-of-the-art results in instance segmentation benchmarks.
Disadvantages of Mask R-CNN
- Computational Intensity: The mask prediction branch increases the computational load.
- Resource Requirements: Mask R-CNN typically requires substantial computing resources like GPUs.
- Data Annotation Challenges: Labor-intensive and challenging to create for certain domains.
- Limited Real-Time Applications: Despite its accuracy, Mask R-CNN might not be suitable for real-time applications with strict latency requirements.
Applications of Mask R-CNN
Due to its additional capability to generate segmented masks, it is used in many computer vision applications such as:
- Human Pose Estimation
- Self Driving Car
- Drone Image Mapping etc.
Conclusion
In conclusion, Mask R-CNN’s ability to simultaneously detect and segment objects with high accuracy positions it as a powerful tool for various applications, from human pose estimation to autonomous vehicles.
Mask R-CNN – FAQs
Q. What is mask R-CNN used for?
Used for precise instance segmentation in computer vision tasks, providing detailed object masks.
Q. What is the difference between mask R-CNN and CNN?
Mask R-CNN extends CNN for instance segmentation, predicting pixel-level masks alongside object detection.
Q. What is the difference between mask R-CNN and Yolo?
YOLO focuses on real-time object detection, while Mask R-CNN additionally provides instance segmentation with masks.
Q. What is the main use of mask?
Masks in Mask R-CNN represent pixel-level segmentation, outlining precise boundaries of detected objects.
Q. What is ResNet in deep learning?
ResNet is a deep neural network architecture with residual connections, aiding in training very deep networks.
Share your thoughts in the comments
Please Login to comment...