Image Processing in Python
Last Updated :
21 Mar, 2024
Image processing in Python is a rapidly growing field with a wide range of applications. It is used in a variety of industries, including Computer vision, medical imaging, security, etc.
In this article, we’ll look at how to use OpenCV in Python to process the images.
What is Image Processing?
Image processing is the field of study and application that deals with modifying and analyzing digital images using computer algorithms. The goal of image processing is to enhance the visual quality of images, extract useful information, and make images suitable for further analysis or interpretation.
Image Processing Using OpenCV
OpenCV (Open Source Computer Vision) is a powerful and widely-used library for image processing and computer vision tasks. It provides a comprehensive set of functions and tools that facilitate the development of applications dealing with images and videos.
While taking photographs is as simple as pressing a button, processing and improving those images sometimes takes more than a few lines of code. That’s where image processing libraries like OpenCV come into play. OpenCV is a popular open-source package that covers a wide range of image processing and computer vision capabilities and methods. It supports multiple programming languages including Python, C++, and Java. OpenCV is highly tuned for real-time applications and has a wide range of capabilities.
Image Processing with Python
We will make the following operations most commonly uses for data augmentation task which training the model in computer Vision.
Input Image

Image Resizing
Scaling operations increase or reduce the size of an image.
- The
cv2.resize() function is used to resize an python image in OpenCV. It takes the following arguments:
cv2.resize(src, dsize,interpolation)
Here,
src :The image to be resized.
dsize :The desired width and height of the resized image.
interpolation:The interpolation method to be used.
- When the python image is resized, the interpolation method defines how the new pixels are computed. There are several interpolation techniques, each of which has its own quality vs. speed trade-offs.
- It is important to note that resizing an image can reduce its quality. This is because the new pixels are calculated by interpolating between the existing pixels, and this can introduce some blurring.
Python3
# Import the necessary libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('Ganeshji.webp')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Define the scale factor
# Increase the size by 3 times
scale_factor_1 = 3.0
# Decrease the size by 3 times
scale_factor_2 = 1/3.0
# Get the original image dimensions
height, width = image_rgb.shape[:2]
# Calculate the new image dimensions
new_height = int(height * scale_factor_1)
new_width = int(width * scale_factor_1)
# Resize the image
zoomed_image = cv2.resize(src =image_rgb,
dsize=(new_width, new_height),
interpolation=cv2.INTER_CUBIC)
# Calculate the new image dimensions
new_height1 = int(height * scale_factor_2)
new_width1 = int(width * scale_factor_2)
# Scaled image
scaled_image = cv2.resize(src= image_rgb,
dsize =(new_width1, new_height1),
interpolation=cv2.INTER_AREA)
# Create subplots
fig, axs = plt.subplots(1, 3, figsize=(10, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image Shape:'+str(image_rgb.shape))
# Plot the Zoomed Image
axs[1].imshow(zoomed_image)
axs[1].set_title('Zoomed Image Shape:'+str(zoomed_image.shape))
# Plot the Scaled Image
axs[2].imshow(scaled_image)
axs[2].set_title('Scaled Image Shape:'+str(scaled_image.shape))
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:

Image Rotation
Images can be rotated to any degree clockwise or otherwise. We just need to define rotation matrix listing rotation point, degree of rotation and the scaling factor.
- The
cv2.getRotationMatrix2D() function is used to create a rotation matrix for an image. It takes the following arguments: - The center of rotation for the image.
- The angle of rotation in degrees.
- The scale factor.
- The
cv2.warpAffine() function is used to apply a transformation matrix to an image. It takes the following arguments: - The python image to be transformed.
- The transformation matrix.
- The output image size.
- The rotation angle can be positive or negative. A positive angle rotates the image clockwise, while a negative angle rotates the image counterclockwise.
- The scale factor can be used to scale the image up or down. A scale factor of 1 will keep the image the same size, while a scale factor of 2 will double the size of the python image.
Python3
# Import the necessary Libraries
import cv2
import matplotlib.pyplot as plt
# Read image from disk.
img = cv2.imread('Ganeshji.webp')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Image rotation parameter
center = (image_rgb.shape[1] // 2, image_rgb.shape[0] // 2)
angle = 30
scale = 1
# getRotationMatrix2D creates a matrix needed for transformation.
rotation_matrix = cv2.getRotationMatrix2D(center, angle, scale)
# We want matrix for rotation w.r.t center to 30 degree without scaling.
rotated_image = cv2.warpAffine(image_rgb, rotation_matrix, (img.shape[1], img.shape[0]))
# Create subplots
fig, axs = plt.subplots(1, 2, figsize=(7, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image')
# Plot the Rotated image
axs[1].imshow(rotated_image)
axs[1].set_title('Image Rotation')
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
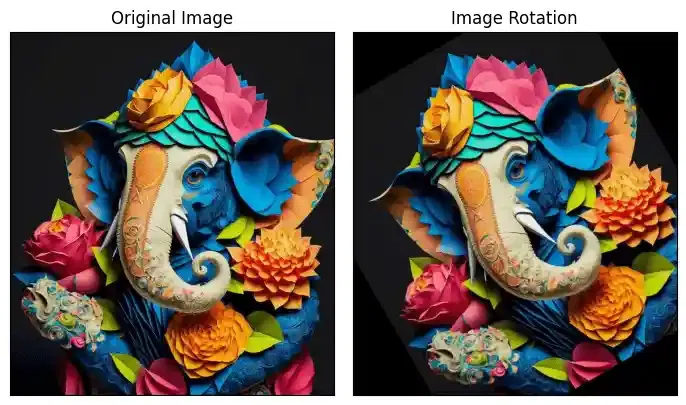
Image Translation
Translating an image means shifting it within a given frame of reference that can be along the x-axis and y-axis.
- To translate an image using OpenCV, we need to create a transformation matrix. This matrix is a 2×3 matrix that specifies the amount of translation in each direction.
- The
cv2.warpAffine() function is used to apply a transformation matrix to an image. It takes the following arguments: - The image to be transformed.
- The transformation matrix.
- The output image size.
- The translation parameters are specified in the transformation matrix as the
tx and ty elements. The tx element specifies the amount of translation in the x-axis, while the ty element specifies the amount of translation in the y-axis.
Python3
# Import the necessary Libraries
import cv2
import matplotlib.pyplot as plt
# Read image from disk.
img = cv2.imread('Ganesh.jpg')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
width = image_rgb.shape[1]
height = image_rgb.shape[0]
tx = 100
ty = 70
# Translation matrix
translation_matrix = np.array([[1, 0, tx], [0, 1, ty]], dtype=np.float32)
# warpAffine does appropriate shifting given the Translation matrix.
translated_image = cv2.warpAffine(image_rgb, translation_matrix, (width, height))
# Create subplots
fig, axs = plt.subplots(1, 2, figsize=(7, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image')
# Plot the transalted image
axs[1].imshow(translated_image)
axs[1].set_title('Image Translation')
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
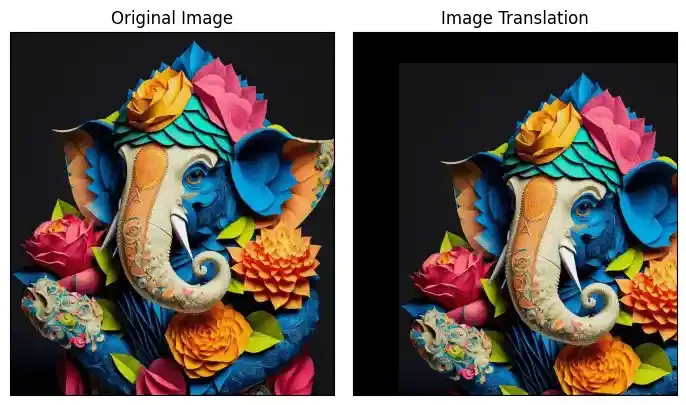
Image shearing is a geometric transformation that skews an image along one or both axes i.e x or y axis.
- To shear an image using OpenCV, we need to create a transformation matrix. This matrix is a 2×3 matrix that specifies the amount of shearing in each direction.
- The
cv2.warpAffine() function is used to apply a transformation matrix to an image. It takes the following arguments: - The image to be transformed.
- The transformation matrix.
- The output image size.
- The shearing parameters are specified in the transformation matrix as the
shearX shearY elements. The shearX element specifies the amount of shearing in the x-axis, while the shearY element specifies the amount of shearing in the y-axis.
Python3
# Import the necessary Libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('Ganesh.jpg')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Image shape along X and Y
width = image_rgb.shape[1]
height = image_rgb.shape[0]
# Define the Shearing factor
shearX = -0.15
shearY = 0
# Define the Transformation matrix for shearing
transformation_matrix = np.array([[1, shearX, 0],
[0, 1, shearY]], dtype=np.float32)
# Apply shearing
sheared_image = cv2.warpAffine(image_rgb, transformation_matrix, (width, height))
# Create subplots
fig, axs = plt.subplots(1, 2, figsize=(7, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image')
# Plot the Sheared image
axs[1].imshow(sheared_image)
axs[1].set_title('Sheared image')
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
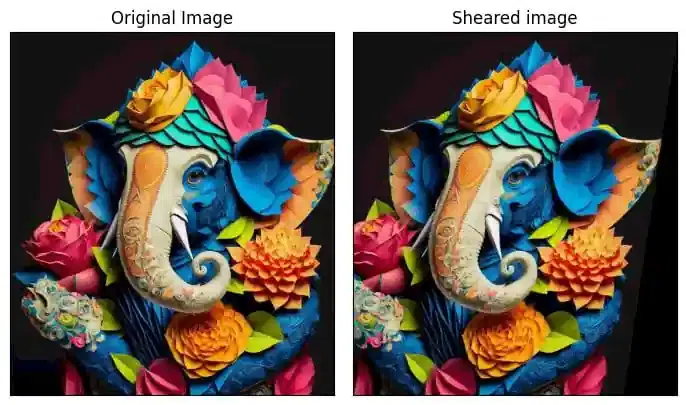
Image Normalization
Image normalization is a process of scaling the pixel values in an image to a specific range.This is often done to improve the performance of image processing algorithms, as many algorithms work better when the pixel values are within a certain range.
- In OpenCV, the
cv2.normalize() function is used to normalize an image. This function takes the following arguments: - The input image.
- The output image.
- The minimum and maximum values of the normalized image.
- The normalization type.
- The dtype of the output image.
- The normalization type specifies how the pixel values are scaled. There are several different normalization types available, each with its own trade-offs between accuracy and speed.
- Image normalization is a common preprocessing step in many image processing tasks. It can help to improve the performance of algorithms such as image classification, object detection, and image segmentation.
Python3
# Import the necessary Libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('Ganesh.jpg')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Split the image into channels
b, g, r = cv2.split(image_rgb)
# Normalization parameter
min_value = 0
max_value = 1
norm_type = cv2.NORM_MINMAX
# Normalize each channel
b_normalized = cv2.normalize(b.astype('float'), None, min_value, max_value, norm_type)
g_normalized = cv2.normalize(g.astype('float'), None, min_value, max_value, norm_type)
r_normalized = cv2.normalize(r.astype('float'), None, min_value, max_value, norm_type)
# Merge the normalized channels back into an image
normalized_image = cv2.merge((b_normalized, g_normalized, r_normalized))
# Normalized image
print(normalized_image[:,:,0])
plt.imshow(normalized_image)
plt.xticks([])
plt.yticks([])
plt.title('Normalized Image')
plt.show()
Output:
[[0.0745098 0.0745098 0.0745098 ... 0.07843137 0.07843137 0.07843137]
[0.0745098 0.0745098 0.0745098 ... 0.07843137 0.07843137 0.07843137]
[0.0745098 0.0745098 0.0745098 ... 0.07843137 0.07843137 0.07843137]
...
[0.00392157 0.00392157 0.00392157 ... 0.0745098 0.0745098 0.0745098 ]
[0.00392157 0.00392157 0.00392157 ... 0.0745098 0.0745098 0.0745098 ]
[0.00392157 0.00392157 0.00392157 ... 0.0745098 0.0745098 0.0745098 ]]

Edge detection of Image
The process of image edge detection involves detecting sharp edges in the image. This edge detection is essential in the context of image recognition or object localization/detection. There are several algorithms for detecting edges due to its wide applicability.
In image processing and computer vision applications, Canny Edge Detection is a well-liked edge detection approach. In order to detect edges, the Canny edge detector first smoothes the image to reduce noise, then computes its gradient, and then applies a threshold to the gradient. The multi-stage Canny edge detection method includes the following steps:
- Gaussian smoothing: The image is smoothed using a Gaussian filter to remove noise.
- Gradient calculation: The gradient of the image is calculated using the Sobel operator.
- Non-maximum suppression: Non-maximum suppression is applied to the gradient image to remove spurious edges.
- Hysteresis thresholding: Hysteresis thresholding is applied to the gradient image to identify strong and weak edges.
The Canny edge detector is a powerful edge detection algorithm that can produce high-quality edge images. However, it can also be computationally expensive.
Python3
# Import the necessary Libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Read image from disk.
img = cv2.imread('Ganesh.jpg')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Apply Canny edge detection
edges = cv2.Canny(image= image_rgb, threshold1=100, threshold2=700)
# Create subplots
fig, axs = plt.subplots(1, 2, figsize=(7, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image')
# Plot the blurred image
axs[1].imshow(edges)
axs[1].set_title('Image edges')
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
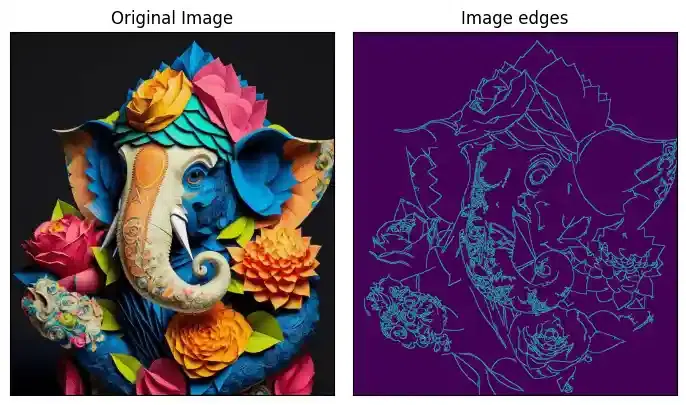
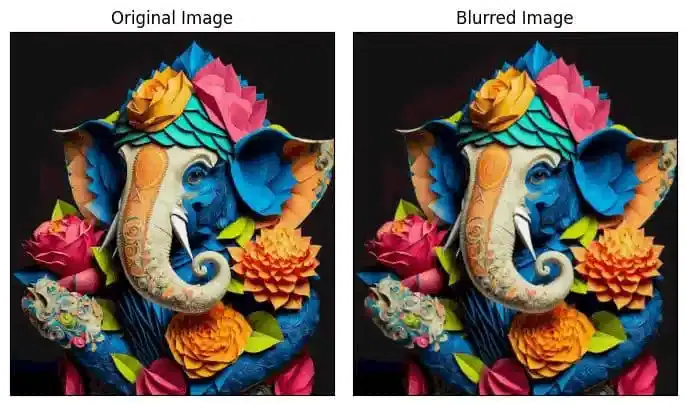
Image Blurring
Image blurring is the technique of reducing the detail of an image by averaging the pixel values in the neighborhood. This can be done to reduce noise, soften edges, or make it harder to identify a picture. In many image processing tasks, image blurring is a common preprocessing step. It is useful in the optimization of algorithms such as image classification, object identification, and image segmentation. In OpenCV, a variety of different blurring methods are available, each with a particular trade-off between blurring strength and speed.
Some of the most common blurring techniques include:
- Gaussian blurring: This is a popular blurring technique that uses a Gaussian kernel to smooth out the image.
- Median blurring: This blurring technique uses the median of the pixel values in a neighborhood to smooth out the image.
- Bilateral blurring: This blurring technique preserves edges while blurring the image.
Python3
# Import the necessary Libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('Ganesh.jpg')
# Convert BGR image to RGB
image_rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# Apply Gaussian blur
blurred = cv2.GaussianBlur(image, (3, 3), 0)
# Convert blurred image to RGB
blurred_rgb = cv2.cvtColor(blurred, cv2.COLOR_BGR2RGB)
# Create subplots
fig, axs = plt.subplots(1, 2, figsize=(7, 4))
# Plot the original image
axs[0].imshow(image_rgb)
axs[0].set_title('Original Image')
# Plot the blurred image
axs[1].imshow(blurred_rgb)
axs[1].set_title('Blurred Image')
# Remove ticks from the subplots
for ax in axs:
ax.set_xticks([])
ax.set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
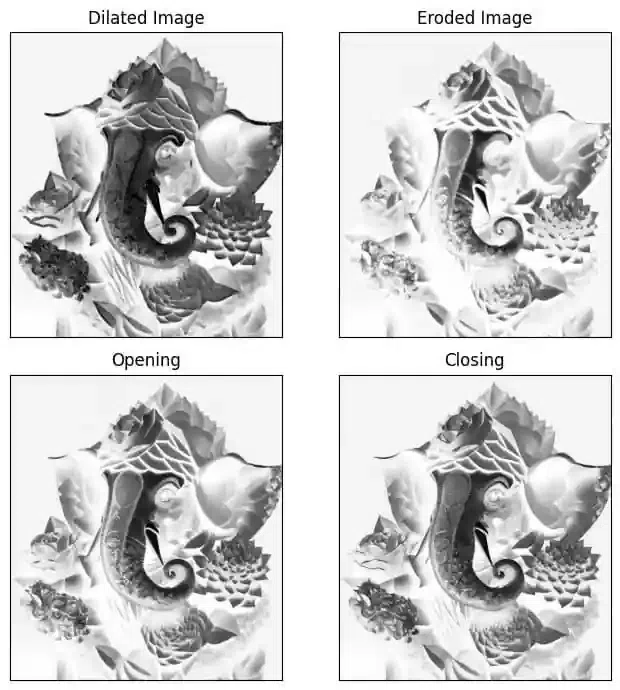
Morphological Image Processing
Morphological image processing is a set of python image processing techniques based on the geometry of objects in an image. These procedures are commonly used to eliminate noise, separate objects, and detect edges in images.
Two of the most common morphological operations are:
- Dilation: This operation expands the boundaries of objects in an image.
- Erosion: This operation shrinks the boundaries of objects in an image.
Morphological procedures are often used in conjunction with other image processing methods like segmentation and edge detection.
Python3
# Import the necessary Libraries
import cv2
import numpy as np
import matplotlib.pyplot as plt
# Load the image
image = cv2.imread('Ganesh.jpg')
# Convert BGR image to gray
image_gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Create a structuring element
kernel = np.ones((3, 3), np.uint8)
# Perform dilation
dilated = cv2.dilate(image_gray, kernel, iterations=2)
# Perform erosion
eroded = cv2.erode(image_gray, kernel, iterations=2)
# Perform opening (erosion followed by dilation)
opening = cv2.morphologyEx(image_gray, cv2.MORPH_OPEN, kernel)
# Perform closing (dilation followed by erosion)
closing = cv2.morphologyEx(image_gray, cv2.MORPH_CLOSE, kernel)
# Create subplots
fig, axs = plt.subplots(2, 2, figsize=(7, 7))
# Plot the Dilated Image
axs[0,0].imshow(dilated, cmap='Greys')
axs[0,0].set_title('Dilated Image')
axs[0,0].set_xticks([])
axs[0,0].set_yticks([])
# Plot the Eroded Image
axs[0,1].imshow(eroded, cmap='Greys')
axs[0,1].set_title('Eroded Image')
axs[0,1].set_xticks([])
axs[0,1].set_yticks([])
# Plot the opening (erosion followed by dilation)
axs[1,0].imshow(opening, cmap='Greys')
axs[1,0].set_title('Opening')
axs[1,0].set_xticks([])
axs[1,0].set_yticks([])
# Plot the closing (dilation followed by erosion)
axs[1,1].imshow(closing, cmap='Greys')
axs[1,1].set_title('Closing')
axs[1,1].set_xticks([])
axs[1,1].set_yticks([])
# Display the subplots
plt.tight_layout()
plt.show()
Output:
Conclusion
OpenCV‘s image processing offers a strong basis for a variety of jobs, but it may be improved even more by utilizing the convolutional capability of deep learning. Advanced convolutional neural networks are available in these deep learning frameworks, which can preprocess images more accurately and effectively.
Image Processing- FAQs
What is image processing in Python?
Python enables image processing through libraries like OpenCV, PIL, and scikit-image for diverse applications.
How to do image preprocessing in Python?
Preprocess images using Python by libraries like OpenCV and scikit-image for tasks like resizing and filtering.
Which is the famous image processing Python?
OpenCV is a popular and powerful image processing library widely used for computer vision applications.
Share your thoughts in the comments
Please Login to comment...