R-CNN vs Fast R-CNN vs Faster R-CNN | ML
Last Updated :
26 Jan, 2023
R-CNN: R-CNN was proposed by Ross Girshick et al. in 2014 to deal with the problem of efficient object localization in object detection. The previous methods use what is called Exhaustive Search which uses sliding windows of different scales on image to propose region proposals Instead, this paper uses the Selective search algorithm which takes advantage of segmentation of objects and Exhaustive search to efficiently determine the region proposals. This selective search algorithm proposes approximately 2000 region proposals per image. These are then passed to the CNN model (Here AlexNet is used).
- AlexNet is a convolutional neural network (CNN) architecture that was developed by Alex Krizhevsky, Ilya Sutskever, and Geoffrey Hinton in 2012. It was the first CNN to win the ImageNet Large Scale Visual Recognition Challenge (ILSVRC), a major image recognition competition, and it helped to establish CNNs as a powerful tool for image recognition.
- AlexNet consists of several layers of convolutional and pooling layers, followed by fully connected layers. The architecture includes five convolutional layers, three pooling layers, and three fully connected layers.
- The first two convolutional layers use a kernel of size 11×11 and apply 96 filters to the input image. The third and fourth convolutional layers use a kernel of size 5×5 and apply 256 filters. The fifth convolutional layer uses a kernel of size 3×3 and applies 384 filters. The output of these convolutional layers is then passed through max-pooling layers that reduce the spatial dimensions of the feature maps.
- The output of the pooling layers is then passed through three fully connected layers, with 4096, 4096, and 1000 neurons respectively. The last fully connected layer is used for classification, and produces a probability distribution over the 1000 ImageNet classes.
- AlexNet was trained on the ImageNet dataset, which consists of 1.2 million images with 1000 classes, and was able to achieve high recognition accuracy. The AlexNet architecture was the first to show that CNNs could significantly outperform traditional machine learning methods in image recognition tasks, and was an important step in the development of deeper architectures like VGGNet, GoogleNet, and ResNet.
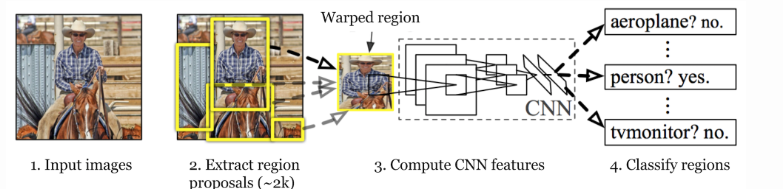
R-CNN architecture
This CNN model then outputs a (1, 4096) feature vector from each region proposal. This vector then passed into the SVM model for classification of object and bounding box regressor for localization. Problem with R-CNN:
- Each image needs to classify 2000 region proposals. So, it takes a lot of time to train the network.
- It requires 49 seconds to detect the objects in an image on GPU.
- To store the feature map of the region proposal, lots of Disk space is also required.
Fast R-CNN : In R-CNN we passed each region proposal one by one in the CNN architecture and selective search generated around 2000 region proposal for an image. So, it is computationally expensive to train and even test the image using R-CNN. To deal with this problem Fast R-CNN was proposed, It takes the whole image and region proposals as input in its CNN architecture in one forward propagation. It also combines different parts of architecture (such as ConvNet, RoI pooling, and classification layer) in one complete architecture. That also removes the requirement to store a feature map and saves disk space. It also uses the softmax layer instead of SVM in its classification of region proposal which proved to be faster and generate better accuracy than SVM.

Fast R-CNN architecture
Fast R-CNN drastically improves the training (8.75 hrs vs 84 hrs) and detection time from R-CNN. It also improves Mean Average Precision (mAP) marginally as compare to R-CNN. Problems with Fast R-CNN:
- Most of the time taken by Fast R-CNN during detection is a selective search region proposal generation algorithm. Hence, it is the bottleneck of this architecture which was dealt with in Faster R-CNN.
Faster R-CNN: Faster R-CNN was introduced in 2015 by k He et al. After the Fast R-CNN, the bottleneck of the architecture is selective search. Since it needs to generate 2000 proposals per image. It constitutes a major part of the training time of the whole architecture. In Faster R-CNN, it was replaced by the region proposal network. First of all, in this network, we passed the image into the backbone network. This backbone network generates a convolution feature map. These feature maps are then passed into the region proposal network. The region proposal network takes a feature map and generates the anchors (the centre of the sliding window with a unique size and scale). These anchors are then passed into the classification layer (which classifies that there is an object or not) and the regression layer (which localize the bounding box associated with an object).
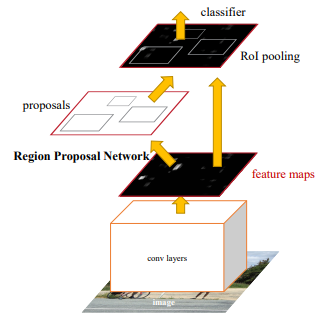
Faster R-CNN architecture
In terms of Detection time, Faster R-CNN is faster than both R-CNN and Fast R-CNN. The Faster R-CNN also has better mAP than both the previous ones. Comparison Between R-CNN, Fast R-CNN and Faster R-CNN:
| |
R-CNN |
Fast R-CNN |
Faster R-CNN |
| Method For Generating Region Proposals |
Selective Search |
Selective Search |
Region Proposal Network |
| The mAP on Pascal VOC 2007 test dataset(%) |
58.5 |
66.9 (when trained with VOC 2007 only)
70.0 (when trained with VOC 2007 and 2012 both)
|
69.9(when trained with VOC 2007 only)
73.2 (when trained with VOC 2007 and 2012 both)
78.8(when trained with VOC 2007 and 2012 and COCO)
|
| The mAP on Pascal VOC 2012 test dataset (%) |
53.3 |
65.7 (when trained with VOC 2012 only)
68.4 (when trained with VOC 2007 and 2012 both)
|
67.0(when trained with VOC 2012 only)
70.4 (when trained with VOC 2007 and 2012 both)
75.9(when trained with VOC 2007 and 2012 and COCO)
|
| Detection Time (sec) |
~ 49 (with region proposal generation) |
~ 2.32(with region proposal generation) |
0.2 (with VGG),
0.059 (with ZF)
|
Uses :
- R-CNN, Fast R-CNN, and Faster R-CNN are all popular object detection algorithms used in machine learning.
- R-CNN (Regions with CNN) uses a selective search algorithm to propose regions of interest (ROIs) in an image, and then uses a CNN to classify each ROI.
- Fast R-CNN improves upon R-CNN by using a shared convolutional layer to process the entire image and all ROIs, rather than processing each ROI independently. This greatly reduces the computational time needed for object detection.
- Faster R-CNN further improves upon Fast R-CNN by using a region proposal network (RPN) to generate ROIs, which is much faster than the selective search algorithm used in R-CNN and Fast R-CNN. The network uses the feature maps of the CNN to predict object bounds.
- All three of these algorithms are widely used in various applications such as autonomous vehicles, security systems, and robotics, to name a few.
The above Detection time results are from the research paper. They can vary depending upon the machine configurations. References:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...