Region Proposal Network (RPN) in Object Detection
Last Updated :
08 Sep, 2023
In recent times Object Detection Algorithms have evolved manifold and this has led to many advancements in the applications which helped us solve real-world problems with the utmost efficiency and latency of real-time. In this article, we will look a Region Proposal Networks which serve as an important milestone in the advancements of Object Detection Algorithms.
What is Object Detection?
Object Detection is a computer vision technique that is used for locating objects in a digital image or video, and identifying (or classifying) them. It can be done using single-stage approaches as well as two-stage. Each approach has its pros and cons. Typically, the two stages of object detection are:
- Extracting Regions of Interest (RoI) by generating candidate boxes.
- Classifying the RoIs
Region Proposal Network (RPN) is used in the first step to generate proposals of regions of interest, where the model extracts potential candidates of objects in the image or video. It basically tells the network where to look. Traditionally, this was done using computer vision techniques like selective search, which were computationally expensive. RPN became extremely popular due to its power as well as faster computation. It helped in reducing the running time of detection networks like Fast RCNN and SPPnet. Let us understand how it works.
Region Proposal in R-CNN family
R-CNN stands for Region-based Convolutional Neural Network. It is a family of machine learning models used for computer vision tasks, specifically object detection. Traditionally, object detection was done by scanning every grid position of an image using different sizes of frames to identify the object’s location and class. Applying CNN on every frame took a very long time. R-CNN reduced this problem. It uses Selective Search to select the candidate region and then applies CNN to each region proposal. However, it was still slow due to the repeated application of CNN on overlapping candidate regions.
Fast R-CNN extracts features by applying convolution layers on the entire image. It then selects CNN features on each region proposal obtained by Selective Search. Thus, Fast R-CNN was more than 200 times faster than R-CNN but the latency due to region proposal using selective search was still high.
Faster R-CNN eliminated the bottleneck due to Selective Search by using a neural network for region proposal. RPN reduced the latency by 10 times and the model could run in real-time. It was proven to be more efficient because it used feature maps, whereas, selective search used raw image pixels. Moreover, it does not add much overhead because the feature maps are shared between RPN and the rest of the network. Refer to the figure below.

Python3
def create_faster_rcnn_model(features, scaled_gt_boxes,
dims_input, cfg):
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model,
[cfg["MODEL"].POOL_NODE_NAME],
[cfg["MODEL"].LAST_HIDDEN_NODE_NAME],
clone_method=CloneMethod.clone)
feat_norm = features - Constant([[[v]]
for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
rpn_rois, rpn_losses = create_rpn(conv_out,
scaled_gt_boxes,
dims_input, cfg)
rois, label_targets, \
bbox_targets, bbox_inside_weights = \
create_proposal_target_layer(rpn_rois,
scaled_gt_boxes, cfg)
cls_score, \
bbox_pred = create_fast_rcnn_predictor(conv_out,
rois,
fc_layers, cfg)
detection_losses = create_detection_losses(...)
loss = rpn_losses + detection_losses
pred_error = classification_error(cls_score,
label_targets, axis=1)
return loss, pred_error
|
The bounding boxes around the objects or the RoIs proposed by RPN will look like the image shown below. With the right training data, the model gives good accuracy and precision.

Working of Region Proposal Network (RPN)
RPN is a fully convolutional network that predicts the object bounds by learning from feature maps extracted from a base network. It has a classifier that returns the probability of the region and a regressor that returns the coordinates of bounding boxes.
Anchor boxes
A feature map is extracted from the convolutional neural network layers. Every point on this feature map is considered. Every point on the feature map is called an anchor.
- Anchor boxes are boxes generated at image dimension, based on the aspect ratios and scales of the images. Aspect ratio is the ratio of width to height of the image and scale is the size of the image.
- The anchor boxes are positioned (in centers) on each anchor point of the convolutional feature map as shown in the image below. Each anchor box is slid across the entire feature map. You can imagine this like a sliding window. With each point as the center of the anchor box, it produces a prediction of whether the box has an object or not.
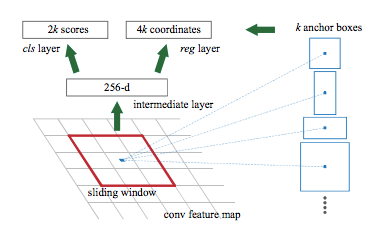
Therefore, if we have k anchor boxes, then for every position on the feature map, we will have k predictions. These predictions are essentially binary classifications of foreground and background.
Intersection-Over-Union (IoU)
The foreground and background labels are assigned based on a metric called Intersection over Union (IoU) that determines the amount of overlap of the anchor box with the object of interest. It is calculated as the ratio of the area of intersection between the anchor box and the box with an area of interest to the area of the union of the two boxes. IoU > 0.7 usually implies a foreground.
Note: The bounding box classifier in RPN does not tell us whether an object is an animal or a vehicle. It only tells us if the part of the image is background or foreground.
Regression
Values which are the coordinates of the center, width, and height respectively of the bounding box. Since it is a learning model, it has a cost function that can be defined as the sum of classification loss and regression loss. It can be written as follows:



The offsets thus obtained, are applied to get the RoIs, which are further processed in the object detection. In a nutshell, the RPN proposes a bunch of boxes that are classified as background or foreground, and the foreground anchors boxes are further refined to obtain the regions of interest.
Share your thoughts in the comments
Please Login to comment...