YOLO v2 – Object Detection
Last Updated :
06 Dec, 2022
In terms of speed, YOLO is one of the best models in object recognition, able to recognize objects and process frames at the rate up to 150 FPS for small networks. However, In terms of accuracy mAP, YOLO was not the state of the art model but has fairly good Mean average Precision (mAP) of 63% when trained on PASCAL VOC2007 and PASCAL VOC 2012. However, Fast R-CNN which was the state of the art at that time has an mAP of 71%.
YOLO v2 and YOLO 9000 was proposed by J. Redmon and A. Farhadi in 2016 in the paper titled YOLO 9000: Better, Faster, Stronger. At 67 FPS, YOLOv2 gives mAP of 76.8% and at 67 FPS it gives an mAP of 78.6% on VOC 2007 dataset bettered the models like Faster R-CNN and SSD. YOLO 9000 used YOLO v2 architecture but was able to detect more than 9000 classes. YOLO 9000, however, has an mAP of 19.7%.
Let’s look at the architecture and working of YOLO v2:
Architecture Changes vs YOLOv1:
The previous YOLO architecture has a lot of problems when compared to the state-of-the-art method like Fast R-CNN. It made a lot of localization errors and has a low recall. So, the goal of this paper is not only to improve these shortcomings of YOLO but also to maintain the speed of the architecture. There are some incremental improvements that are made in basic YOLO. Let’s discuss these changes below:

Darknet-19 simplified
- Batch Normalization:
By adding batch normalization to the architecture we can increase the convergence of the model that leads us for faster training. This also eliminates the need for applying other types of normalization such as Dropout without overfitting. It is also observed that adding batch normalization alone can cause an increase in mAP by 2% as compared to basic YOLO.
- High Resolution Classifier:
The previous version of YOLO uses 224 *224 as input size during training but at the time of detection, it takes an image up to size 448*448. This causes the model to adjust to a new resolution that in turn causes a decrease in mAP.
The YOLOv2 version trains on higher resolution (448 * 448) for 10 epochs on ImageNet data. This gives network time to adjust the filters for higher resolution. By training on 448*448 images size the mAP increased by 4%.
- Use Anchor Boxes For Bounding Boxes:
YOLO uses fully connected layers to predict bounding boxes instead of predicting coordinates directly from the convolution network like in Fast R-CNN, Faster R-CNN.
In this version, we remove the fully connected layer and instead add the anchor boxes to predict the bounding boxes. We made the following changes in the architecture:
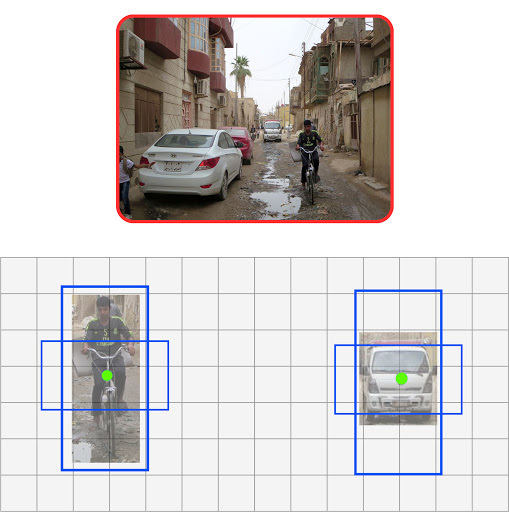
Bounding Boxes with more than 1 anchors (that will provide more accurate localisation)
- We remove the fully connected layer responsible for predicting bounding boxes and replace it with anchor boxes prediction.

YOLOv1 with layers removed (in filled red color)
- We change the size of input from 448 * 448 to 416 * 416. This creates a feature map of size 13 * 13 when we downsample it 32x. The idea behind this that there is a good possibility of the object at the center of the feature map.
- Remove one pooling layer to get 13 * 13 spatial network instead of 7*7
With these changes, the mAP of the model is slightly decreased (from 69.5% to 69.2%) however recall increases from 81% to 88%.
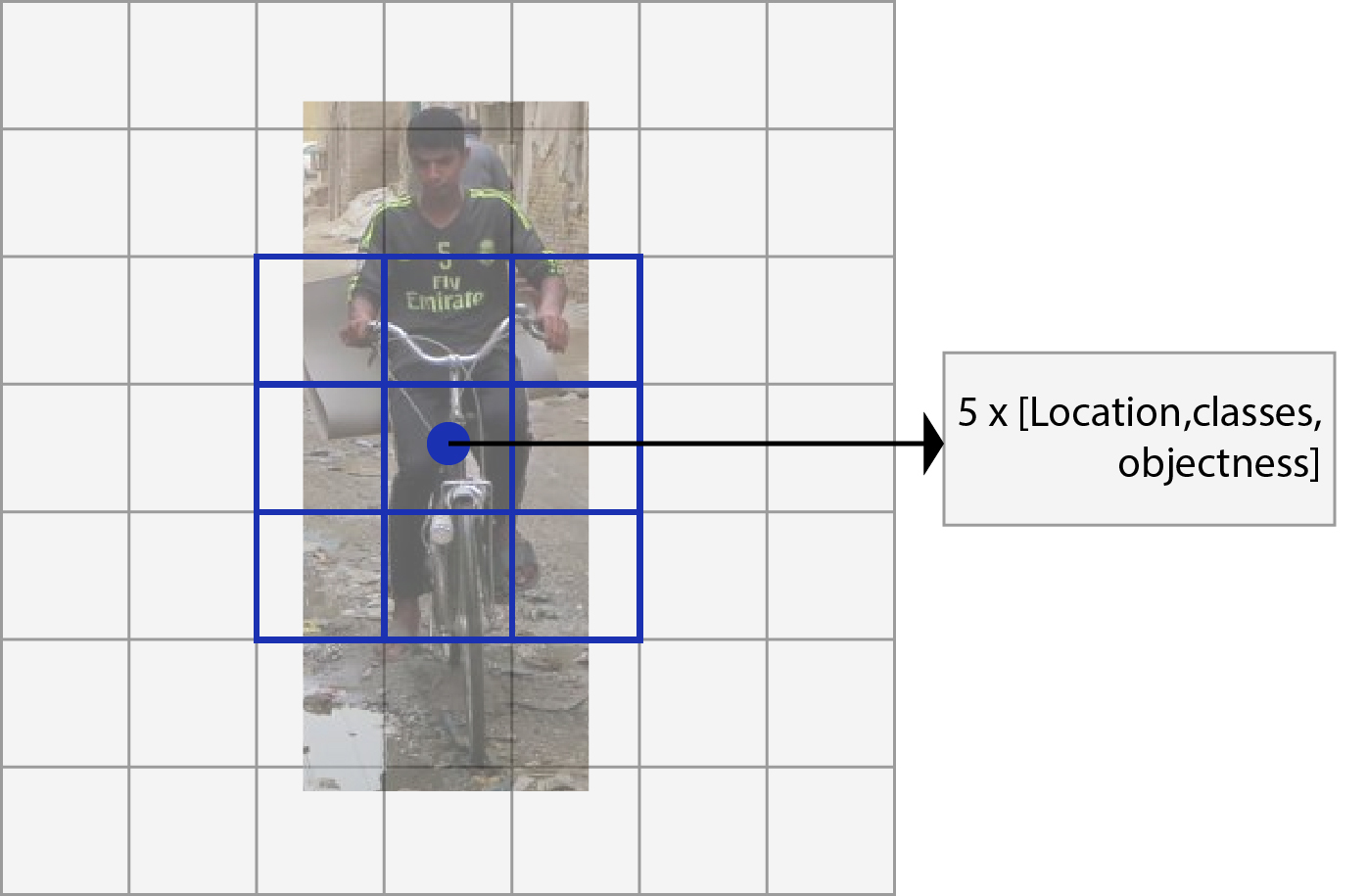
Output of each object proposal
- Dimensionality clusters:
We need to identify the number of anchors (priors) generated so that they provide the best results. Let’s take as K for now. Our task is to identify the top-K bounding boxes for images that have maximum accuracy. We use the K-means clustering algorithm for that purpose. But, we don’t need to minimize the Euclidean distance instead we maximize the IOU as the target of this algorithm.
YOLO v2 uses K=5 for the better trade-off of the algorithm. We can conclude from the graph below that as we increase the value of K=5 accuracy doesn’t change significantly.
IOU based clustering on K = 5 gives mAP of 61%.

Dimension clusters(number of dimension for each anchors) vs mAP
- Direct Location Problem:
The previous version of YOLO does not have a constraint on location prediction which makes it unstable on early iteration. YOLOv2 predicts 5 parameters (tx, ty, tw, th, to (objectness score)) and applies the sigma function to constraint its value falls between 0 and 1.


This direct location constraint increases the mAP by 5%.
- Fine Grained Features :
YOLOv2 which generates 13 * 13 is sufficient fr detecting large objects. However, if we want to detect finer objects we can modify the architecture such that the output of previous layer 26 * 26 * 512 to 13 * 13 * 2048 and concatenates with the original 13 * 13 * 1024 output layer making our output layer of size.
- Multi-Scale Training :
YOLO v2 has been trained on different input sizes from 320 * 320 to 608 * 608 using step of 32. This architecture randomly chooses image dimensions for every 10 batches. There can be a trade-off established between accuracy and image size. For Example, YOLOv2 with images size of 288 * 288 at 90 FPS gives as much as mAP as Fast R-CNN.

Architecture:
YOLO v2 is trained on different architectures such as VGG-16 and GoogleNet. The paper also proposed an architecture called Darknet-19. The reason for choosing the Darknet architecture is its lower processing requirement than other architectures 5.58 FLOPS ( as compared to 30.69 FLOPS on VGG-16 for 224 * 224 image size and 8.52 FLOPS in customized GoogleNet). The structure of Darknet-19 is given below:
For detection purposes, we replace the last convolution layer of this architecture and instead add three 3 * 3 convolution layers every 1024 filters followed by 1 * 1 convolution with the number of outputs we need for detection.
For VOC we predict 5 boxes with 5 coordinates (tx, ty, tw, th, to (objectness score)) each with 20 classes per box. So total number of filters is 125.

Darknet-19 architecture
Training:
The YOLOv2 is trained for two purposes :
- For classification task the model is trained on ImageNet-1000 classification task for 160 epochs with a starting learning rate 0.1, weight decay of 0.0005 and momentum of 0.9 using Darknet-19 architecture. There are some standard Data augmentation techniques applied for this training.
- For detection there are some modifications made in the Darknet-19 architecture which we discussed above. The model is trained for 160 epochs on starting learning rate 10-3, weight decay of 0.0005 and momentum of 0.9. The same strategy used for training the model on both COCO and VOC.
Results and Conclusion:

Results of Different object detection frameworks
YOLOv2 gives state-of-the-art detection accuracy on the PASCAL VOC and COCO. It can run on varying sizes offering a tradeoff between speed and accuracy. At 67 FPS, YOLOv2 can give an mAP of 76.8 while at 40 FPS the detector gives an accuracy of 78.6 mAP, better than the state-of-the-model such as Faster R-CNN and SSD while running significantly faster than those models.

Speed vs Accuracy Curve for different object detection
This model has also been the basis of the YOLO9000 model which is able to detect more than 9000 classes in real-time.
Reference:
Share your thoughts in the comments
Please Login to comment...