We all are living in an era of Artificial Intelligence and have felt its impact. There are numerous AI tools for various purposes ranging from Text Generation to image Generation to Video Generation to many more things. You must have used text-to-image models like Dall-E3, Stable Diffusion, MidJourney, etc. And it might be that you’re fascinated with their image-generation capabilities as they can generate realistic images of non-existent objects or can enhance existing images. They can convert your imagination into an image in a matter of seconds. But how?
In this article, we are going to explore how all these TTM models have this kind of imagination that can generate images that they’ve never seen.

How does an AI generate images?
What is AI Image Generation?
An AI image generator also termed a generative model utilizes a trained ANN (Artificial Neural Network) i.e., modeled to biological neural networks to generate images from scratch. These trained ANNs can generate realistic images based on the textual input provided by the user. But they have some remarkable capabilities like fusing styles, concepts, and attributes to contextually related images. and That is availed via using a Generative AI.
An AI Image Generator that we are using is trained on a vast amount of data consisting of texts and corresponding images. Throughout the training process, the model learns various aspects, characteristics, and patterns in the images provided in the dataset. After completion of training of the model, the Model becomes capable of generating new images that have similar design, style, or content that was there in the training data.
There are various AI Image Generation Models that have their capabilities and use different kinds of technologies to generate text from images.
Notably, there are four technologies for Image Generation:
- Generative Adversarial Networks (GANs)
- Neural Style Transfer (NST)
- Diffusion Models
- Variational Autoencoders (VAEs)
But before using any of the above-mentioned technologies Image Generation model uses an NLP Model to understand the text prompts provided by the user to translate it into a machine-friendly language i.e., numerical representations or embeddings.
The NLP model encodes the prompt text into a numerical format that captures the various elements mentioned in the prompt and the relationship among them. This model will create a rulebook for image generation on how the components mentioned in the prompt will be incorporated and interact with each other.
After the completion of the NLP model’s task, these Image Generation models come into action. Let’s discuss how different algorithms are used for image generation.
Generative Adversarial Networks (GANs)
Generative Adversarial Networks or GANs are a type of machine learning algorithm used for unsupervised learning. I use two neural networks competing with each other. One is the generator, and the other is a discriminator. The term adversarial is used in its name meaning that these two networks are pitted against each other in a zero-sum game.
A Generative Adversarial Network has two parts:
- The Generator tries to fool the discriminator by producing random noise samples based on the samples provided while training.
- The Discriminator tries to distinguish between the data produced by the generator and the actual data provided while training the model.
.jpg)
GANs Architecture
At the start of training, the Generator starts by producing absolute fake data that the discriminator can easily identify this is fake. As the training keeps on going the generator gets closer to producing output that can’t be easily distinguished by the Discriminator. Finally, If the training goes as planned the discriminator will lose the game and fail in distinguishing between the real and the fake output. As a result of this interactive competition between the generator and discriminator, both of the neural networks drive toward advancement. And becomes capable of generating realistic, high-quality images. GANs are highly versatile algorithms as they can be used in image synthesis, style transfer, etc.
Neural Style Transfer (NST)
Neural Style Transfer also known as NST is a deep learning application that can fuse the artistic component of an image with the visual patterns, textures, and colors of another image to generate an image that has never existed before. It’s not similar to physically blending one image over another instead it takes another approach to match the artistic components of one image with the patterns, textures or the colors of another images. As shown in the below image, first image has a dog, and Second image has some patterns, textures and colors. So, the resultant image created by NST was a fusion of both images. A dog in the pattern, texture and color provided in the second image.

NST Working
At a higher level, NST revolves around Convolutional Neural Networks (CNNs) particularly using pre-trained models like VCG or ResNet that can analyze visuals and employ additional measures to extract style from one image and apply it to another image. At the beginning convolutional layers of pre-trained models are used to extract all the component and style-related information from the provided image.
NST uses a multi-layered architecture in which early layers of architecture capture the low-level features like textures and colors meanwhile the deeper layer of the model is used to capture more complex and abstract features aiming to preserve the structures and the content-specific details.
After all the extractions like Style, Content, Pattern, Texture, Colors, etc. are performed. Image generation starts with the content image or a random noise. Some optimization processes are also employed to adjust the pixel values of the initialized image to match the content representation of the first image and the style representation of the second image.
NST loss function consists of three main components:
- Content Loss (Measure of difference in the content of the generated image and actual image)
- Style Loss (Measure of difference in the style of generated image and the actual image)
- Total Variation loss (It controls the smoothness of the generated image).
A weighted sum of all these losses is used to guide the optimization process to generate an image that is a balance between both the first and second images.
Diffusion Models
Diffusion models are a kind of generative model that means they generate new data based on the training data. It uses an approach to generate high-quality images by iteratively reducing noises in the image. This technique is based on iteratively adding noise to an image and gradually removing the noise in order to unveil the desired image. The model operates through a sequence of steps where noise levels decrease over time, revealing a more refined image. This model is specifically known for its ability to generate high-quality images.

Diffusion Model Working
Essentially, the Diffusion model starts with an initial image that serves as a starting point and then incrementally starts adding Gaussian Noise to the initial image across multiple steps until it becomes total noise (As shown above image noise is gradually added to the cat’s image).
Then each step of the diffusion process decreases the intensity or level of added noise in the image. After completing all the steps of noise addition and reduction, an inversion process takes place. That reverses the diffusion steps, starting from the image with noise, the model reconstructs the original, high-quality image.
The main aim of the model is to minimize the difference between the generated image by the model and the actual image provided. The iterative noise reduction process of Diffusion Models facilitates the image creation with fine details and sharp features. And the best thing is these models are versatile and can be scaled to handle high-resolution images. Famous image-generation AI tools like DALL-E2, Midjourney & Stable Diffusion are based on this algorithm.
Variational Autoencoders (VAEs)
Variational Autoencoders also known as VAEs are one of the most powerful generative models used for Image Generation. Likewise, GANs also use two neural networks named encoder and decoder but, in a bit, different manner.
VAEs have two important components:
- The Encoder is usually a CNN (Convolutional Neural Network) that reduces the input image to a latent space representation (mean & variance vectors).
- The Decoder is also a CNN (Convolutional Neural Network) model that takes the latent space representation and performs the task of reconstruction of the image.
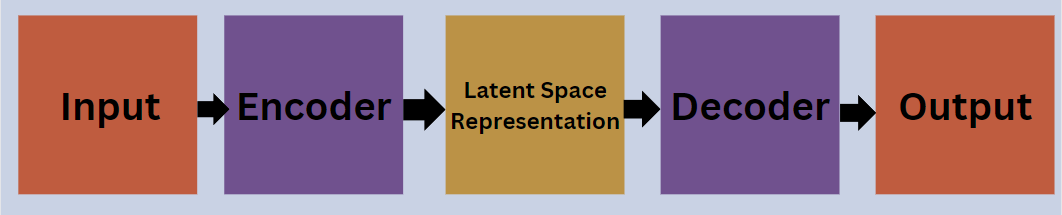
VAEs Architecture
In VAEs, the input image is passed through the encoder to get the mean and variance vectors representing latent space. Then a sample point is taken in the latent space by using the reparameterization technique. After that, the sampled point from the latent space is fed into the decoder i.e., a neural network to generate a reconstructed image.
VAEs loss function consists of two parts:
- Reconstruction Loss (It measures the difference between the input image provided to the encoder and the reconstructed image generated by the decoder)
- and KL Divergence Loss (It helps in preventing overfitting by ensuring that the learned latent space is close to a unit Gaussian Distribution).
During training our aim to minimize the combined loss using techniques like Backpropagation. And by updating the weights in Encoder and Decoder. Gradually this process will improve their ability to encode and decode images efficiently.
Also check:
Share your thoughts in the comments
Please Login to comment...