Generate Images from Text in Python – Stable Diffusion
Last Updated :
28 Mar, 2024
Looking for the images can be quite a hassle don’t you think? Guess what? AI is here to make it much easier! Just imagine telling your computer what kind of picture you’re looking for and voila it generates it for you. That’s where Stable Diffusion, in Python, comes into play. It’s like magic – transforming words into visuals. In this article, we’ll explore how you can utilize Diffusion in Python to discover and craft stunning images. It’s, like having an artist right at your fingertips!
What is Stable Diffusion?
In 2022, the concept of Stable Diffusion, a model used for generating images from text, was introduced. This innovative approach utilizes diffusion techniques to create images based on textual descriptions. In addition to image generation, it can also be utilized for various tasks such as inpainting, outpainting, and generating image-to-image translations with the aid of a text prompt.
How does it work?
Diffusion models are a type of generative model that is trained to denoise an object, such as an image, to obtain a sample of interest. The model is trained to slightly denoise the image in each step until a sample is obtained. It first paints the image with random pixels and noise and tries to remove the noise by adjusting every step to give a final image that aligns with the prompt.
Simplified Working
- Basically stable diffusion uses the “diffusion” concept in generating high-quality images as output from text. The process involves adjusting the various pixels from the pure noise created at the start of the process based on a diffusion equation.
- The text prompt which is provided is first converted into individual pieces, this includes splitting the text into words or phrases, called tokens, and understanding their meaning. and these tokens are represented as a 768-dimensional vector known as embeddings.
- Stable diffusion operates on latent space. So, the model compresses the image into latent space rather than operating in the high-dimensional image space.
- The information is compressed by the autoencoder and again is reconstructed by the decoder. The noise pattern starts in this space, and every step tweaks its position in the space.
- The process continues until a set number of steps are completed, or the model determines that the image sufficiently matches the text description. Then the final image is generated.
Architecture of Stable Diffusion
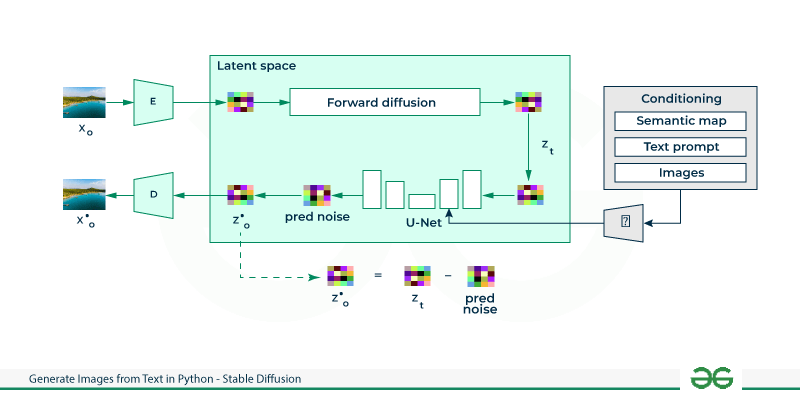
Stable Diffusion is founded on a diffusion model known as Latent Diffusion, which is recognized for its advanced abilities in image synthesis, specifically in tasks such as image painting, style transfer, and text-to-image generation. Unlike other diffusion models that focus solely on pixel manipulation, latent diffusion integrates cross-attention layers into its architecture. These layers enable the model to assimilate information from various sources, including text and other inputs.
There are three main components in latent diffusion:
- Autoencoder
- U-Net
- Text Encoder
Autoencoder:
An autoencoder is designed to learn a compressed version of the input image. A Variational Autoencoder consists of two main parts i.e. an encoder and a decoder. The encoder’s task is to compress the image into a latent form, and then the decoder uses this latent representation to recreate the original image.
U-Net:
U-Net is a kind of convolutional neural network (CNN) that’s used for cleaning up the latent representation of an image. It’s made up of a series of encoder-decoder blocks that step by step increase the image quality. The encoder part of the network reduces the image down to a lower resolution, and then the decoder works to bring this compressed image backup to its original, higher resolution and eliminate any noise in the process.
Text Encoder
The job of the text encoder is to convert text prompts into a latent form. Typically, this is achieved using a transformer-based model, such as the Text Encoder from CLIP, which takes a series of input tokens and transforms them into a sequence of latent text embeddings.
How to Generate Images from Text?
The Stable Diffusion model is a huge framework that requires us to write very lengthy code to generate an image from a text prompt. However, HuggingFace has introduced Diffusers to overcome this challenge. With Diffusers, we can easily generate numerous images by simply writing a few lines of Python code, without the need to worry about the architecture behind it. In our case, we will be utilizing the cutting-edge StableDiffusionPipeline provided by the Diffusers library. This helps in generating an image from a text prompt with only a few lines of Python code.
Requirements
- Diffusers: This is the main package we require to run the inference on the model.
pip install diffusers
- transformers: This package is required for encoding and decoding purposes.
pip install transformers
- Pillow: This package is used for Image processing.
pip install Pillow
- accelerate, scipy, and safetensors: These packages are required to run the model on our computer.
pip install accelerate scipy safetensors
Note: Use a virtual environment if you are running this project on your local machine to avoid any installation errors. Skip this if you are using Colab. It’s better to use Google Colab to run this model, as it requires a lot of CPU and GPU resources of your system to complete the processing.
Versions of Diffusion
Some of the popular Stable Diffusion Text-to-Image model versions are:
- Stable Diffusion v1 – The base model that is the start of image generation.
- Stable Diffusion v1.5 – Larger Image qualities and support for larger image sizes (up to 1024×1024).
- Stable Diffusion v2 – Improvements to image quality, conditioning, and generation speed are made.
- Stable Diffusion 2.1 – Optimized for speed with AI Template and supports all input shapes up to 1024×1024.
- Stable Diffusion XL 1.0 – Large language model with 1.28B parameters, trained on a huge dataset of text and images, can generate images from text descriptions. Can generate images at higher resolutions (up to 2048×2048) with improved image quality.
The better version the slower inference time and great image quality and results to the given prompt.
In this article, we will be using the stabilityai/stable-diffusion-2-1 model for generating images. stable-diffusion-2-1 model is fine-tuned from stable-diffusion-2. Stable Diffusion 2 is way better than Stable Diffusion 1 with improved image quality and is more realistic.
Generating Image
Here is the Python code to run the model which generates the image as output. If you are using Google Colab, change the runtime to T4 which is GPU with a high amount of RAM.
Python3
import torch
from diffusers import StableDiffusionPipeline
from PIL import Image
# Replace the model version with your required version if needed
pipeline = StableDiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-1", torch_dtype=torch.float16
)
# Running the inference on GPU with cuda enabled
pipeline = pipeline.to('cuda')
prompt = "Your prompt here"
image = pipeline(prompt=prompt).images[0]
This code will generate a Pillow Image as output and is stored in the “image” variable that is accessed later.
Note: When the above code is run for the first time, a few pytorch models, and safe sensors of size up to 5GB will be installed on your computer. Afterwards, it will just use those.
Displaying the Image
If you are running locally, use the following code to display the image.
Python3
If you are running on Google Colab, use the following code to display the image.
Python3
from IPython.display import display
display(image)
Prompt: Photograph of a horse on a highway road at sunset.
Output:
-compressed-300.jpg)
Tips to Generate Images from Text in Python
- If the stabilityai/stable-diffusion-2-1 model is taking much time to generate the image or is not installed on your computer due to its large size, better to use CompVis/stable-diffusion-v1-4 in the code for faster process times. Although, it may not produce the quality images like stable diffusion 2.
- The more descriptive the prompt is the better and more accurate the image as output.
- You can change the size of the image using the height and width parameters in the pipeline function like pipeline(prompt=prompt, height=1024, width=1024).images[0]
- Currently, the Stable Diffusion cannot provide accurate images that have text in them. It gives good results if the prompt is well-written.
Stable Diffusion: Frequently Asked Questions (FAQs)
What is Stable Diffusion?
Stable Diffusion is a machine learning model introduced in 2022 that utilizes diffusion techniques to generate images from text descriptions.
What are the key components of Stable Diffusion?
Stable Diffusion is based on a type of diffusion model known as Latent Diffusion. Its architecture consists of three main components: Autoencoder (VAE), U-Net, and Text Encoder.
What are some popular versions of the Stable Diffusion Text-to-Image model?
Notable versions include Stable Diffusion v1, v1.5, v2, 2.1, and XL 1.0.
Share your thoughts in the comments
Please Login to comment...