Deep Face Recognition
Last Updated :
19 Dec, 2022
DeepFace is the facial recognition system used by Facebook for tagging images. It was proposed by researchers at Facebook AI Research (FAIR) at the 2014 IEEE Computer Vision and Pattern Recognition Conference (CVPR).
In modern face recognition there are 4 steps:
- Detect
- Align
- Represent
- Classify
This approach focuses on alignment and representation of facial images. We will discuss these two part in detail.
Alignment:
The goal of this alignment part is to generate frontal face from the input image that may contain faces from different pose and angles. The method proposed in this paper used 3D frontalization of faces based on the fiducial (face feature points) to extract the frontal face. The whole alignment process is done in the following steps:
- Given an input image, we first identify the face using six fiducial points. These six fiducial points are 2 eyes, tip of the nose and 3 points on the lips. These feature points are used to detect faces in the image.

6-fiducial points
- In this step we generate the 2D-face image cropped from the original image using 6 fiducial points.

2D-cropped face
- In the third step, we apply the 67 fiducial point map with their corresponding Delaunay Triangulation on the 2D-aligned cropped image. This step is done in order to align the out of plane rotations. In this step, we also generate a 3D-model using a generic 2D to 3D model generator and plot 67 fiducial points on that manually.

67 fiducial points with Delaunay triangulation

3D shape generated from the align 2D-crop image

Visibility map of 2D shape in 3D (darker triangles are less visible as compared to light triangles)
- Then we try to establish a relation between 2D and 3D using given relation

Here to improve this transformation, we need to minimize the loss on  which can be calculated by the following relation:
which can be calculated by the following relation:

where,

and ∑  is a covariance matrix and dimensions of (67 x 2) x (67 x 2), X3d is (67 x 2) x 8 and [Tex]\overrightarrow{P} [/Tex] has dimensions of (2 x 4). We are using Cholesky decomposition to convert that loss function into ordinary least square.
is a covariance matrix and dimensions of (67 x 2) x (67 x 2), X3d is (67 x 2) x 8 and [Tex]\overrightarrow{P} [/Tex] has dimensions of (2 x 4). We are using Cholesky decomposition to convert that loss function into ordinary least square.
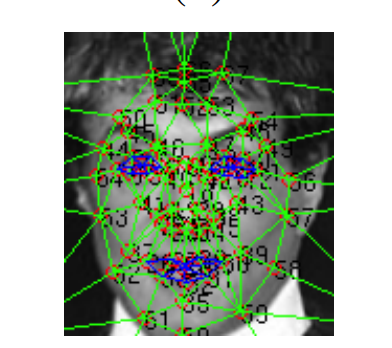
67 fiducial point mapping on 2D-3D affine face.
- The final stage is frontalization of alignment. But before achieving frontalization we add the residual component to x-y coordinates of 3D warp because it reduces corruption in 3D-warp. Finally, frontalization is achieved by doing piece-wise affine on Delaunay triangulation that we generated on 67-fiducial points.

final frontalization
Representation and Classification Architecture:
DeepFace is trained for multi-class face recognition i.e. to classify the images of multiple peoples based on their identities.
It takes input into a 3D-aligned RGB image of 152*152. This image is then passed the Convolution layer with 32 filters and size 11*11*3 and a 3*3 max-pooling layer with the stride of 2. This is followed by another convolution layer of 16 filters and size 9*9*16. The purpose of these layers to extract low-level features from the image edges and textures.
The next three layers are locally connected layers, a type of fully connected layer that has different types of filters in a different feature map. This helps in improving the model because different regions of the face have different discrimination ability so it is better to have different types of feature maps to distinguish these facial regions.

DeepFace full architecture
The last two layers of the model are fully connected layers. These layers help in establishing a correlation between two distant parts of the face. Example: Position and shape of eyes and position and shape of the mouth. The output of the second last fully connected layer is used as a face representation and the output of the last layer is the softmax layer K classes for the classification of the face.
The total number of parameters in this network is 120 million approximately with most of them (~95%) comes from the final fully connected layers. The interesting property of this network is the feature map/vector generated during the training of this model amazingly sparse. For Example, 75% of the values in topmost layers is 0. This may be because of this network uses ReLU activation function in every convolution network which is essentially max(0, x). This network also uses Drop-out Regularization which also contributed to sparsity. However, Dropout is only applied to the first fully connected layer.
In the final stages of this network, we also normalize the feature to be between 0 and 1. This also reduces the effect of illumination changes across. We also perform an L2-regularization after this normalization.
Verification Metric:
We need to define some metric that measures whether two input images belong to the same class or not. There are two methods: supervised and unsupervised with supervised having better accuracy than unsupervised. It is intuitive because while training on particular target dataset one is able to improve the accuracy by fine-tuning the model according to it. For Example, Labeled Faces in the Wild (LFW) dataset has 75% of faces are male, training on LFW may introduce some bias and add some generalization which is not suitable while testing on other face recognition datasets. However, training using a small dataset may reduce generalization when used on other datasets. In these cases, the unsupervised similarity metric is better. This paper uses the inner product of two feature vectors generated from representation architecture for unsupervised similarity. This paper also uses two supervised verification metrics. These are
- The Weighted [Tex]\chi ^{2} [/Tex]distance :
The Weighted  similarity is defined as :
similarity is defined as :
![\chi^{2}_{f_1, f_2} = \sum _{i}\omega_{i} \dfrac{\left ( f_1\left [ i \right ] - f_2\left [ i \right ]\right )^2}{f_1\left [ i \right ] + f_2\left [ i \right ]}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-940db55f1c42410abc06d5fdb86d2130_l3.png "Rendered by QuickLaTeX.com")
where  are face representation vector and
are face representation vector and  is weight we can learn using linear SVM.
is weight we can learn using linear SVM.
- Siamese Network:
Siamese network is a very common approach and used to predict whether two faces belong to the same class or not. It calculates the Siamese distance between two face representations if the distance is within tolerance then if the distance is under the tolerance level then it predicts two faces belong to the same class else not. Siamese distance is defined as
![d_{\left ( f_1, f_2 \right )} = \sum_{i}\alpha_i\left | f_1\left [ i \right ] - f_2\left [ i \right ] \right |](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-061945f63c28a908c324c60dd20eea50_l3.png "Rendered by QuickLaTeX.com")
Training and Results
DeepFace is trained and experimented on the following three datasets
- SFC dataset:
This is the dataset generated by Facebook itself. It contains nearly 4.4 million images of 4030 peoples each having 800 to 1200 face images. For the testing purpose, they take 5% most recent images from each class. The model is trained using a standard feed-forward network with SGD with momentum = 0.9, batch size = 128 and the learning rate is the same for all the layer i.e 0.01.
The model is trained on three subsets of dataset 1.5k people (1.5 M images), 3k people (3.3 M images) and 4k people (4.4 M images). The classification error rate on these subsets are 7%, 7.2% and 8.7% respectively.
- LFW dataset:
It is one of the most popular datasets in the domain of face recognition. It contains more than 13000 web images of more than 5700 celebrities. The performance is measured using three methods:- Restricted method in which the pair of images provided to model and the goal is to identify whether the image is same or not same.
- Unrestricted method in which more images than a single pair is accessible to training.
- Unsupervised method in which the model has not been trained on LFW dataset.
The results are as follows:

Here, DeepFace-ensamble represents combination of different DeepFace-single model that uses different verification metrics we discussed above.
As we can conclude that DeepFace-ensemble reach maximum accuracy of 97.35% accuracy which is very close to the human level 97.53%
- YTF dataset:
It contains 3425 videos of 1595 celebrities (a subset of celebrities from LFW). These videos are divided into 5000 video pairs of 10 splits and used to evaluate performance on video level face verification. The results on YTF dataset is as follows:

Results on YTF
Notice, because of motion blur and other factors the image quality of video datasets is generally worse than images dataset. However, 91.4% is still the state-of-the-art accuracy at that time and reduces the error rate by more than 50%.
In terms of testing time, DeepFace takes 0.33 seconds when tested on a single-core 2.2GHz Intel processor. This includes 0.05 seconds taken on alignment and 0.18 seconds on feature extraction.
Conclusion:
At the time of its publication, It was one of the best face recognition model now of course models such as Google-FaceNet and other models which provide accuracy up to 99.6% on LFW dataset. The main problem the DeepFace has been able to solve is to build a model that is invariant to light effect, pose, facial expression, etc. and that’s why it is used in most of the Facebook’s face recognition tasks. The novel approach to use 3D alignment also contributed to the increase in the accuracy of the model.
Reference:
Share your thoughts in the comments
Please Login to comment...