Classification of Routing Algorithms
Last Updated :
19 Jan, 2024
Pre-requisites: Difference between Static and Dynamic Routing
Routing is the process of establishing the routes that data packets must follow to reach the destination. In this process, a routing table is created which contains information regarding routes that data packets follow. Various routing algorithms are used for the purpose of deciding which route an incoming data packet needs to be transmitted on to reach the destination efficiently.
Classification of Routing Algorithms
The routing algorithms can be classified as follows:
- Adaptive Algorithms
- Non-Adaptive Algorithms
- Hybrid Algorithms
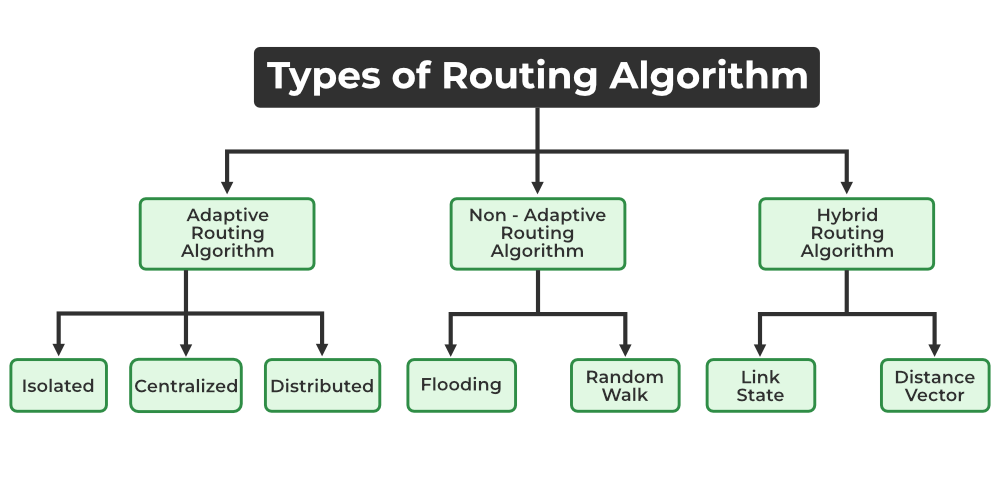
Types of Routing Algorithm
1. Adaptive Algorithms
These are the algorithms that change their routing decisions whenever network topology or traffic load changes. The changes in routing decisions are reflected in the topology as well as the traffic of the network. Also known as dynamic routing, these make use of dynamic information such as current topology, load, delay, etc. to select routes. Optimization parameters are distance, number of hops, and estimated transit time.
Further, these are classified as follows:
- Isolated: In this method each, node makes its routing decisions using the information it has without seeking information from other nodes. The sending nodes don’t have information about the status of a particular link. The disadvantage is that packets may be sent through a congested network which may result in delay. Examples: Hot potato routing, and backward learning.
- Centralized: In this method, a centralized node has entire information about the network and makes all the routing decisions. The advantage of this is only one node is required to keep the information of the entire network and the disadvantage is that if the central node goes down the entire network is done. The link state algorithm is referred to as a centralized algorithm since it is aware of the cost of each link in the network.
- Distributed: In this method, the node receives information from its neighbors and then takes the decision about routing the packets. A disadvantage is that the packet may be delayed if there is a change in between intervals in which it receives information and sends packets. It is also known as a decentralized algorithm as it computes the least-cost path between source and destination.
2. Non-Adaptive Algorithms
These are the algorithms that do not change their routing decisions once they have been selected. This is also known as static routing as a route to be taken is computed in advance and downloaded to routers when a router is booted.
Further, these are classified as follows:
- Flooding: This adapts the technique in which every incoming packet is sent on every outgoing line except from which it arrived. One problem with this is that packets may go in a loop and as a result of which a node may receive duplicate packets. These problems can be overcome with the help of sequence numbers, hop count, and spanning trees.
- Random walk: In this method, packets are sent host by host or node by node to one of its neighbors randomly. This is a highly robust method that is usually implemented by sending packets onto the link which is least queued.
Random Walk
3. Hybrid Algorithms
As the name suggests, these algorithms are a combination of both adaptive and non-adaptive algorithms. In this approach, the network is divided into several regions, and each region uses a different algorithm.
Further, these are classified as follows:
- Link-state: In this method, each router creates a detailed and complete map of the network which is then shared with all other routers. This allows for more accurate and efficient routing decisions to be made.
- Distance vector: In this method, each router maintains a table that contains information about the distance and direction to every other node in the network. This table is then shared with other routers in the network. The disadvantage of this method is that it may lead to routing loops.
Difference between Adaptive and Non-Adaptive Routing Algorithms
The main difference between Adaptive and Non-Adaptive Algorithms is:
Adaptive Algorithms are the algorithms that change their routing decisions whenever network topology or traffic load changes. It is called Dynamic Routing. Adaptive Algorithm is used in a large amount of data, highly complex network, and rerouting of data.
Non-Adaptive Algorithms are algorithms that do not change their routing decisions once they have been selected. It is also called static Routing. Non-Adaptive Algorithm is used in case of a small amount of data and a less complex network.
For more differences, you can refer to Differences between Adaptive and Non-Adaptive Routing Algorithms.
Types of Routing Protocol in Computer Networks
1. Routing information protocol (RIP)
One of the earliest protocols developed is the inner gateway protocol, or RIP. we can use it with local area networks (LANs), that are linked computers in a short range, or wide area networks (WANs), which are telecom networks that cover a big range. Hop counts are used by the Routing Information Protocol (RIP) to calculate the shortest path between networks.
2. Interior gateway protocol (IGRP)
IGRP was developed by the multinational technology corporation Cisco. It makes use of many of the core features of RIP but raises the maximum number of supported hops to 100. It might therefore function better on larger networks. IGRPs are elegant and distance-vector protocols. In order to work, IGRP requires comparisons across indicators such as load, reliability, and network capacity. Additionally, this kind updates automatically when things change, such as the route. This aids in the prevention of routing loops, which are mistakes that result in an unending data transfer cycle.
3. Exterior Gateway Protocol (EGP)
Exterior gateway protocols, such as EGP, are helpful for transferring data or information between several gateway hosts in autonomous systems. In particular, it aids in giving routers the room they need to exchange data between domains, such as the internet.
4. Enhanced interior gateway routing protocol (EIGRP)
This kind is categorised as a classless protocol, inner gateway, and distance vector routing. In order to maximise efficiency, it makes use of the diffusing update method and the dependable transport protocol. A router can use the tables of other routers to obtain information and store it for later use. Every router communicates with its neighbour when something changes so that everyone is aware of which data paths are active. It stops routers from miscommunicating with one another. The only external gateway protocol is called Border Gateway Protocol (BGP).
5. Open shortest path first (OSPF)
OSPF is an inner gateway, link state, and classless protocol that makes use of the shortest path first (SPF) algorithm to guarantee effective data transfer. Multiple databases containing topology tables and details about the network as a whole are maintained by it. The ads, which resemble reports, provide thorough explanations of the path’s length and potential resource requirements. When topology changes, OSPF recalculates paths using the Dijkstra algorithm. In order to guarantee that its data is safe from modifications or network intrusions, it also employs authentication procedures. Using OSPF can be advantageous for both large and small network organisations because to its scalability features.
6. Border gateway protocol (BGP)
Another kind of outer gateway protocol that was first created to take the role of EGP is called BGP. It is also a distance vector protocol since it performs data package transfers using the best path selection technique. BGP defines communication over the internet. The internet is a vast network of interconnected autonomous systems. Every autonomous system has autonomous system number (ASN) that it receives by registering with the Internet Assigned Numbers Authority.
Difference between Routing and Flooding
The difference between Routing and Flooding is listed below:
| A routing table is required. |
No Routing table is required. |
| May give the shortest path. |
Always gives the shortest path. |
| Less Reliable. |
More Reliable. |
| Traffic is less. |
Traffic is high. |
| No duplicate packets. |
Duplicate packets are present. |
Frequently Asked Question on Classification of Routing Algorithm – FAQs
What is a routing algorithm?
Routing algoritm is a set of rules that determine the path of a data packet to reach it from source to destination.
Why do we use routing algorithm?
The primary function of routing algorithm is to find the shortest and optimal path between source and destination in computer Networks.
What are the main two types of routing?
There are mainly two types of routing ie Static and Dynamic Routing
Static Routing : Static Routing is also known as non-adaptive routing which doesn’t change the routing table unless the network administrator changes or modifies them manually. Static routing does not use complex routing algorithms and It provides high or more security than dynamic routing.
Dynamic Routing : Dynamic routing is also known as adaptive routing which changes the routing table according to the change in topology. Dynamic routing uses complex routing algorithms and it does not provide high security like static routing.
What is the role of routing in Internet?
Internet ensures that the data packet is sent from source to destination efficiently.
What are the metrics used in routing algorithm?
There are some metricused in routing algorithm are hop count, bandwidth, latency, reliability, and cost. These metrics ensures to determine the best path for data packets to reach to destintion.
Share your thoughts in the comments
Please Login to comment...