Competitive Programming is a mental sport which enables you to code a given problem under provided constraints. The purpose of this article is to provide an overview of the most frequent tricks used in Competitive Programming.

These 25 tricks will help you master competitive programming and solve the problems efficiently:
In competitive programming, it is important to read input as fast as possible, so we save valuable time.
You must have seen various problem statements saying: “Warning: Large I/O data, be careful with certain languages (though most should be OK if the algorithm is well designed)”. The key for such problems is to use Faster I/O techniques.
Fast I/O in C++: It is often recommended to use scanf/printf instead of cin/cout for fast input and output. However, you can still use cin/cout and achieve the same speed as scanf/printf by including the following two lines in your main() function:
ios_base::sync_with_stdio(false);
cin.tie(NULL);
Fast I/O in Java: It is recommended to use User defined FastReader Class which uses BufferedReader and StringTokenizer class with the advantage of user-defined methods for less typing and therefore a faster input altogether.
Fast I/O in Python: It is recommended to read inputs directly from the Judge’s file, instead of using input() function in Python. Inputs can be read directly from the Judge’s file using the os module. Similarly, instead of using print() function we should write directly to the Judge’s System file using sys.stdout.write() function.
In competitive programming, Range XOR with Prefix Sum is an efficient technique for calculating the XOR of elements within a specific range in an array. It utilizes the concept of prefix sums, which store the cumulative sum of elements up to a given index. Similarly, we can maintain a prefix XOR array which stores the cumulative XOR of elements upto a given index. Now, to calculate the XOR of elements within a range [l, r] in an array, we can utilize the prefix sum array. The XOR of the range can be expressed as:
XOR(l, r) = prefix[r] ^ prefix[l – 1]
where prefix[r] represents the prefix sum up to index r and prefix[l-1] represents the prefix sum up to index l-1. The XOR operation effectively isolates the XOR of elements within the specified range.
In competitive programming, Binary Search is defined as a searching algorithm used in a sorted array by repeatedly dividing the search interval in half. The idea of binary search is to use the information that the array is sorted and reduce the time complexity to O(log N). We can also apply Binary Search on Answer to find our answer with the help of given search space in which we take an element [mid] and check its validity as our answer, if it satisfies our given condition in the problem then we store its value and reduce the search space accordingly.
This is one of the most used techniques in competitive programming. We can use Matrix Exponentiation to find the Nth Fibonacci number in log(N) time. The Matrix Exponentiation method uses the following formula:
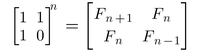
Click here to know more about the finding the Nth Fibonacci Number using Matrix Exponentiation.
In competitive programming, Sparse table concept is used for fast queries on a set of static data (elements do not change). It preprocesses so that the queries can be answered efficiently. The idea is to make a lookup table of size N X logN such that lookup[i][j] contains the answer of range starting from i and of size 2j. Sparse Table can be used to answer queries like Range Minimum Query, Range GCD query in logN time.
In competitive programming, Directed Acyclic Graphs (DAGs) and topological sorting can simplify complex problems in surprising ways. Topological sorting for Directed Acyclic Graph (DAG) is a linear ordering of vertices such that for every directed edge u-v, vertex u comes before v in the ordering. Topological Sorting is commonly used in problems where completion of one task depends on other task(s) and we are required to find the optimal sequence to perform all the tasks. We can also use Kahn’s Algorithm for topological sort to detect cycles in directed graphs.
In competitive programming, two pointers technique is really an easy and effective technique that is typically used for searching pairs in a sorted array. In two pointer approach, we maintain the search space of our answer using two pointers (start and end) and then decrease our search space be either incrementing the start or decrementing the end until we get our answer. Two Pointer approach is commonly used for problems like Two Sum, Triplet Sum, 4 Sum and other problems where we need to find pairs, triplets or quadruplets of elements.
In competitive programming, Mo’s Algorithm can be used to answer offline queries such as finding the sum of every query range. The idea of MO’s algorithm is to pre-process all queries so that result of one query can be used in next query. It can be used in many problems that require processing range queries in a static array, i.e., the array values do not change between the queries. In each query, for a given range [a, b] the idea is to calculate the value based on the array elements between positions of a and b. Since the array is static, the queries can be processed in any order, and Mo’s Algorithm processes the queries in a special order which guarantees that the algorithm works efficiently.
It maintains an active range of the array, and the result of a query concerning the active range is known at each moment. The algorithm processes the queries one by one, and always moves the endpoints of the active range by inserting and removing elements.
Time Complexity: O(N√N*f(N)), where the array has N elements and there are N queries and each insertion and removal of an element takes O(f(N)) time.
In competitive programming, Segment Tree is itself a great data structure that comes into play in many cases. In this post we will introduce the concept of Persistency in this data structure. Persistency simply means to retain the changes. But obviously, retaining the changes cause extra memory consumption and hence affect the Time Complexity.
Our aim is to apply persistency in segment tree and also to ensure that it does not take more than O(log n) time and space for each change.
In competitive programming, Chinese Remainder Theorem is used when we are given k numbers which are pairwise coprime and remainders of these numbers when an unknown number x is divided by them. We need to find the minimum possible value of x that produces given remainders.
The solution is based on the below formula:
x = ( ∑ (rem[i]*pp[i]*inv[i]) ) % prod, where 0 <= i <= n-1
rem[i] is given array of remainders
prod is product of all given numbers (prod = num[0] * num[1] * … * num[k-1])
pp[i] is product of all divided by num[i] (pp[i] = prod / num[i])
inv[i] = Modular Multiplicative Inverse of pp[i] with respect to num[i]
Click here to know more about the implementation.
A regular expression (regex) is a sequence of characters that define a search pattern. Here’s how to write regular expressions:
- Start by understanding the special characters used in regex, such as “.”, “*”, “+”, “?”, and more.
- Choose a programming language or tool that supports regex, such as Python, Perl, or grep.
- Write your pattern using the special characters and literal characters.
- Use the appropriate function or method to search for the pattern in a string.
Regular Expressions in C++: Regex is the short form for “Regular expression”, which is often used in this way in programming languages and many different libraries. It is supported in C++11 onward compilers.
Regular Expressions in Java: In Java, Regular Expressions or Regex (in short) in Java is an API for defining String patterns that can be used for searching, manipulating, and editing a string in Java. Email validation and passwords are a few areas of strings where Regex is widely used to define the constraints. Regular Expressions in Java are provided under java.util.regex package. This consists of 3 classes and 1 interface.
Regular Expressions in Python: The Python standard library provides a re module for regular expressions. Its primary function is to offer a search, where it takes a regular expression and a string. Here, it either returns the first match or else none.
In competitive programming, A bitset is an array of bools but each boolean value is not stored in a separate byte instead, bitset optimizes the space such that each boolean value takes 1-bit space only, so space taken by bitset is less than that of an array of bool or vector of bool.
A limitation of the bitset is that size must be known at compile time i.e. size of the bitset is fixed.
std::bitset is the class template for bitset that is defined inside <bitset> header file so we need to include the header file before using bitset in our program.
Syntax:
bitset<size> variable_name(initialization);
In competitive programming, Sparse matrices can optimize storage for problems involving large two-dimensional arrays with mostly zero values. Sparse matrices come to the rescue by offering a more efficient representation for arrays with a high concentration of zeros. Instead of storing all elements explicitly, they only store the non-zero values along with their corresponding indices. This approach significantly reduces memory requirements, especially for matrices with a sparsity ratio (percentage of zero values) exceeding 80%.
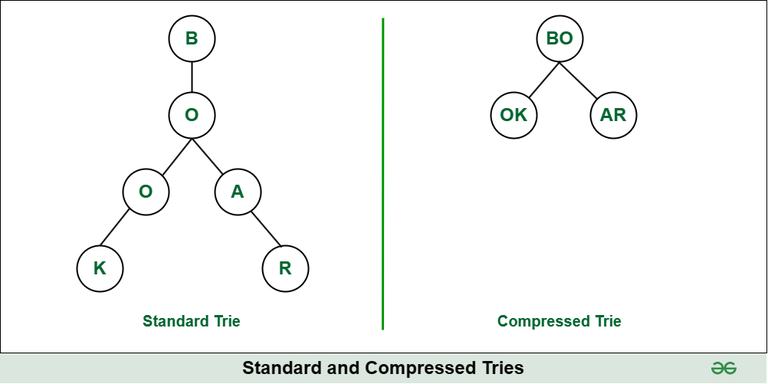
In competitive programming, Compressed tries are efficient data structures for storing and retrieving strings in memory. Tries with nodes of degree at least 2. It is accomplished by compressing the nodes of the standard trie. It is also known as Radix Tries. It is used to achieve space optimization.
Since the nodes are compressed. Let’s visually compare the structure of the Standard tree and the compressed tree for a better approach. In terms of memory, a compressed trie tree uses very few amounts of nodes which gives a huge memory advantage (especially for long) strings with long common prefixes. In terms of speed, a regular trie tree would be slightly faster because its operations don’t involve any string operations, they are simple loops.
In the below image, the left tree is a Standard trie, the right tree is a compressed trie.
In competitive programming, Radix sort is a hidden gem for sorting strings in linear time. Radix Sort is a linear sorting algorithm that sorts elements by processing them digit by digit. It is an efficient sorting algorithm for integers or strings with fixed-size keys. Radix Sort is an efficient non-comparison-based sorting algorithm which can sort a dataset in linear O(N) time complexity and hence, can be better than other competitive algorithms like Quick Sort. It uses another algorithm namely Counting Sort as a subroutine.
This technique uses bitmasks to represent states in dynamic programming problems, allowing for efficient compression of state space and optimization of memory usage. It proves particularly useful for problems with numerous states, where traditional approaches might consume more memory. The main idea is to assign a value to each mask (and, therefore, to each subset) and thus calculate the values for new masks using values of the already computed masks. DP with Bitmasking is generally used when we are given N number of elements and we have to choose subsets of elements to get the most optimal answer. Here, we represent the state of all elements using a bitmask of size N where the ith bit is set (1) if we have selected the ith element in the subset else the ith bit is unset (0).
In competitive programming, Heavy-Light Decomposition is a strategic approach for navigating and querying in trees. Heavy Light decomposition (HLD) is one of the most used techniques in competitive programming. HLD of a rooted tree is a method of decomposing the vertices of the tree into disjoint chains (no two chains share a node), to achieve important asymptotic time bounds for certain problems involving trees. HLD can also be seen as ‘coloring’ of the tree’s edges. The ‘Heavy-Light’ comes from the way we segregate edges. We use size of the subtrees rooted at the nodes as our criteria.
An edge is heavy if size(v) > size(u) where u is any sibling of v. If they come out to be equal, we pick any one such v as special. HLD constructs the tree into a set of chains or paths, where each chain is comprised of a heavy child and its light children. The heavy child refers to the child with the most descendants, while the light children refer to the remaining children. This decomposition strategically merges nodes into chains, prioritizing those with larger subtrees, thereby reducing the overall number of nodes to be traversed.
Euler’s Totient Function has applications beyond number theory, such as in hashing. Euler Totient Function or Phi-function for ‘n’, gives the count of integers in range ‘1′ to ‘n’ that are co-prime to ‘n’. It is denoted by Φ(N).
For example, the below table shows the ETF value of first 20 positive integers:

Some important properties of Euler Totient Function are:
- If N is a prime number, Φ(N) = N – 1
- For NK, where N is a prime number and K is a positive integer: Φ(NK) = NK * (1 – 1/N)
- If N and M are relatively prime, Φ(N*M) = Φ(N) * Φ(M)
Also known as a Binary Indexed Tree (BIT), this data structure allows for efficient manipulation and querying of prefix sums in arrays. It excels at handling problems involving range updates and subsequent queries for the sum within specific intervals. As compared to Segment Trees, Fenwick trees require less space (the size of Fenwick tree is equal to the number of elements whereas the size of segment tree is 4 times the number of elements in the input array). Also, Fenwick Trees are faster to code as it only requires few lines to implement.
In competitive programming, Centroid decomposition is a lesser-known technique for tree-related problems. Centroid of a Tree is a node which if removed from the tree would split it into a ‘forest’, such that any tree in the forest would have at most half the number of vertices in the original tree.
Let S(v) be size of subtree rooted at node v
S(v) = 1 + ∑ S(u)
Here u is a child to v (adjacent and at a depth one
greater than the depth of v).
Centroid is a node v such that, maximum(n – S(v), S(u1), S(u2), .. S(um)) <= n/2
where ui is i’th child to v.
In competitive programming, Binary Lifting is an important technique for efficiently finding the Lowest Common Ancestor in a tree. Binary Lifting is a Dynamic Programming approach for trees where we precompute some ancestors of every node. It is used to answer a large number of queries where in each query we need to find an arbitrary ancestor of any node in a tree in logarithmic time.
In preprocessing, we initialize the ancestor[][] table, such that ancestor[i][j] stores the jth ancestor of node i. The idea is that we can reach (2^j)th ancestor of node i, by making 2 jumps of size (2^(j-1)), that is (2^j) = (2^(j-1)) + (2^(j-1)). After the first jump from node i, we will reach ancestor[i][j-1] and after the 2nd jump from node ancestor[i][j-1], we will reach ancestor[ancestor[i][j-1]][j-1].
In Competitive Programming, Inversion counting techniques can solve problems related to counting inversions in arrays. Inversion Count for an array indicates – how far (or close) the array is from being sorted. If the array is already sorted, then the inversion count is 0, but if the array is sorted in reverse order, the inversion count is the maximum. We can count inversions in an array using various techniques like Merge Sort or using Binary Indexed Trees, etc.
In competitive programming, Randomized algorithms can provide efficient solutions to certain problems with a touch of randomness. An algorithm that uses random numbers to decide what to do next anywhere in its logic is called Randomized Algorithm. For example, in Randomized Quick Sort, we use a random number to pick the next pivot (or we randomly shuffle the array). Typically, this randomness is used to reduce time complexity or space complexity in other standard algorithms. Randomized Algorithms are often used for solving problems like Birthday Paradox, Expectation or expected value of an array, Shuffle a deck of cards, etc.
The Josephus Problem hides an elegant recursive solution applicable to various scenarios. There are N people standing in a circle waiting to be executed. The counting out begins at some point in the circle and proceeds around the circle in a fixed direction. In each step, a certain number of people are skipped, and the next person is executed. The elimination proceeds around the circle (which is becoming smaller and smaller as the executed people are removed), until only the last person remains, who is given freedom. The recursive solution for Josephus Problem is:
Code Snippet
int josephus(int n, int k)
{
return n > 1 ? (josephus(n - 1, k) + k - 1) % n + 1 : 1;
}
|
FFT is a powerful algorithm for efficiently multiplying large polynomials. It significantly outperforms the naive approach of polynomial multiplication, offering asymptotic complexity of O(n log n) compared to O(n^2). This makes it a valuable tool for problems involving polynomial manipulation and signal processing.
Share your thoughts in the comments
Please Login to comment...