uniq Command in Linux with Examples
Last Updated :
15 Feb, 2024
The uniq command in Linux is a command-line utility that reports or filters out the repeated lines in a file. In simple words, uniq is the tool that helps to detect the adjacent duplicate lines and also deletes the duplicate lines. uniq filters out the adjacent matching lines from the input file(that is required as an argument) and writes the filtered data to the output file.
Syntax of uniq Command
The basic syntax of the `uniq` command is:
uniq [OPTIONS] [INPUT_FILE [OUTPUT_FILE]]
Here,
`OPTIONS`: Optional flags that modify the behavior of the `uniq` command.`INPUT_FILE`: The path to the input file containing the text data. If not specified, `uniq` reads from the standard input (usually the keyboard).`OUTPUT_FILE`: The path to the output file where the unique lines will be written. If not specified, `uniq` writes to the standard output (usually the terminal).
Common Options of the uniq Command
Here are some common options that can be used with the `uniq` command:
|
Options
|
Description
|
|
-c, –count
|
Prefix lines by the number of occurrences in the input, followed by a space.
|
|
-d, –repeated
|
Only output lines that are repeated in the input.
|
|
-i, –ignore-case
|
Ignore differences in case when comparing lines.
|
|
-f, –skip-fields=N
|
Avoid comparing the first N fields in each line.
|
|
-s, –skip-chars=N
|
Avoid comparing the first N characters in each line.
|
|
-u, –unique
|
Only output lines that are unique in the input.
|
Examples of Using the `uniq` Command
Now, let’s understand the use of this with the help of an example. Suppose you have a text file named kt.txt which contains repeated lines that needs to be omitted. This can simply be done with uniq.
//displaying contents of kt.txt//
$cat kt.txt
I love music.
I love music.
I love music.
I love music of Kartik.
I love music of Kartik.
Thanks.
How to Remove Duplicate Lines Using `uniq` Command
To remove duplicate lines from `kt.txt`, we can use the `uniq` command:
uniq kt.txt

remove duplicate lines
As you can see that we just used the name of the input file in the above uniq example and as we didn’t use any output file to store the produced output, the uniq command displayed the filtered output on the standard output with all the duplicate lines removed.
Note: uniq isn’t able to detect the duplicate lines unless they are adjacent to each other. The content in the file must be therefore sorted before using uniq or you can simply use sort -u instead of uniq command.
How to Count Duplicate Lines Using `uniq` Command in Linux
The `-c` option prefixes each line with the number of occurrences in the input:
uniq -c kt.txt
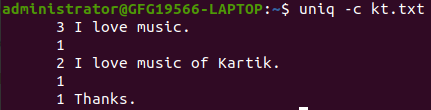
Counting occurrence of duplicate lines
In this example at the starting of each line its repeated number is displayed
How to Display Repeated Lines Using `uniq` Command in Linux
The `-d` option only prints duplicate lines:
uniq -d kt.txt

display only duplicate lines
How to Display all Duplicate Lines Using `uniq` Command in Linux
The `-D` option prints all duplicate lines, not just one per group:
uniq -D kt.txt
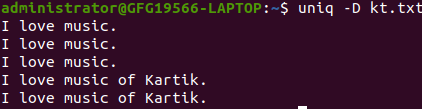
prints all duplicate lines
How to Display Unique Lines Using `uniq` Command in Linux
The `-u` option prints only unique lines:
uniq -u kt.txt

prints only unique lines
Skipping First N Fields (-f option) Using `uniq` Command in Linux
The `-f N` option skips the first N fields before comparing lines. Useful for numbered lines:
uniq -f 2 f1.txt
//displaying contents of f1.txt//
1. I love music.
2. I love music.
3. I love music of Kartik.
4. I love music of Kartik.

`-s N` option
In this example , 2 is used cause we needed to compare the lines after the numbering 1,2.. and after dots
Skipping First N Characters (-s option) Using `uniq` Command in Linux
The `-s N` option skips the first N characters in each line:
//displaying content of f2.txt//
#%@I love music.
^&(I love music.
*-!@thanks.
#%@!thanks.
uniq -s 3 f2.txt
In this example lines same after skipping 3 characters are filtered.

`-s N` option
Limiting Comparison to First N Characters (-w option) Using `uniq` Command in Linux
Using -w option : Similar to the way of skipping characters, we can also ask uniq to limit the comparison to a set number of characters. For this, -w command-line option is used.
//displaying content of f3.txt//
How it is possible?
How it can be done?
How to use it?
uniq -w 3 f3.txt
As the first 3 characters of all the 3 lines are same that’s why uniq treated all these as duplicates and gave output accordingly.

Using -w option
Case-Insensitive Comparison (-i option) Using `uniq` Command in Linux
The `-i` option makes the comparison case-insensitive:
//displaying contents of f4.txt//
I LOVE MUSIC
i love music
THANKS
uniq f4.txt
Here lines aren’t treated as duplicates with simple use of uniq
//now using -i option//
uniq -i f4.txt
Now second line is removed when -i option is used.

comparison case-insensitive
NULL Terminated Output (-z option) Using `uniq` Command in Linux
Using -z option : By default, the output uniq produces is newline terminated. However, if you want, you want to have a NULL terminated output instead (useful while dealing with uniq in scripts). This can be made possible using the -z command line option.
Syntax:
uniq -z file-name
Conclusion
In this article we discussed the uniq command in Linux is a versatile tool for handling duplicate lines in text files. By understanding its various options, you can efficiently manage and process text data. Experiment with different options and examples to master the usage of the uniq command.
?list=PLqM7alHXFySFc4KtwEZTANgmyJm3NqS_L
Share your thoughts in the comments
Please Login to comment...