Data pipelining is essential for transforming raw text data into a numeric format suitable for analysis and model training in Natural Language Processing (NLP).
This article outlines a comprehensive preprocessing pipeline, leveraging Python and the NLTK library, to convert textual data into a usable form for training and modeling.
Data Pipeline
Data Pipeline is the process of transforming the data from the initial one to other form passing it through various stages. In the case of textual data, such as a collection of words or language, data pipelining is essential. This is because we cannot directly apply our statistical formulae or train the model on raw text. Therefore, it becomes necessary to pre-process the text and convert it into a numeric form. This numeric representation is valuable for interpretation, analysis, and model training.
Data analytics involves multiple stages, starting with data collection and followed by data processing. The data prepared for analysis, involving steps like cleaning, transformation, and feature extraction. Finally, the insights derived from the processed data are presented, supporting informed decision-making in Firms and Organizations.
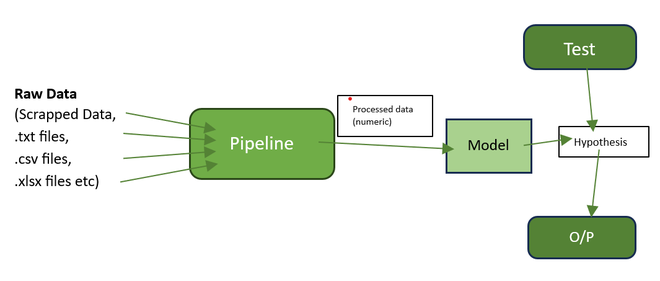
Data Pipelining Structure
Steps involves for creating pipeline to make data usable for training and modelling is listed below…
- Data Collection
- Data Preprocessing (Tokenisation, Stopword removal etc.)
- Data Stemming
- Building a vocabulary and Vectorization
- Classification & Training
“Python provides NLTK library which stands for Natural Language Toolkit, and is powerful enough to work which human language data(text). NLTK provides easy to use interfaces to work over Corpora and lexical resources. Corpus is a collection of text documents and NLTK provides various corpora to provide wide range of language and topics.”
Build a Data Pipeline to ceovert text to Numeric Vector
We’ll start with installing necessary libraries using movie reviews dataset, an opensource dataset from kaggle.
Dataset Link: train_reviews.csv
Python3
import numpy as np
import pandas as pd
|
Python
df = pd.read_csv('train_reviews.csv')
print(df.head(n=5))
|
Output:
review label
0 mature intelligent and highly charged melodram... pos
1 http://video.google.com/videoplay?docid=211772... pos
2 Title: Opera (1987) Director: Dario Argento Ca... pos
3 I think a lot of people just wrote this off as... pos
4 This is a story of two dogs and a cat looking ... pos
Splitting the Data
Python3
reviews_raw_data = df.values
reviews_rawX = reviews_raw_data[:, :-1]
reviews_rawY = reviews_raw_data[:, -1]
print("Text reviews examples: \n", reviews_rawX[:2])
print("\nText corresponding labels examples: \n", reviews_rawY[:2])
|
Output:
Text reviews examples:
[["mature intelligent and highly charged melodrama unbelivebly filmed in China in 1948. wei wei's stunning performance as the catylast in a love triangle is simply stunning if you have the oppurunity to see this magnificent film take it"]
['http://video.google.com/videoplay?docid=211772166650071408&hl=en Distribution was tried.<br /><br />We opted for mass appeal.<br /><br />We want the best possible viewing range so, we forgo profit and continue our manual labor jobs gladly to entertain you for working yours.<br /><br />View Texas tale, please write about it... If you like it or not, if you like Alex or not, if you like Stuie, Texas or Texas tale... Just write about it.<br /><br />Your opinion rules.']]
Text corresponding labels examples:
['pos' 'pos']
Data Pipeline
1. Data preprocessing & cleaning
In the initial stages of natural language processing, raw data undergoes preprocessing to prepare for subsequent analysis. This process includes steps such as tokenization of words and sentences as well as removal of stopwords from raw text.
Stopwords are the commonly used words and are often removed from texts while Natural language processing. These words do not significantly contribute to meaning of sentence whether they exists or not.
For processing our text, Bag-of-words model is generally used. In this model, sequence of words does not matter and focus on single word as a feature. Removing stopwords is crucial in this context, not only to enhance the efficiency of training model but also to give more importance to more meaningful words in the analysis.
eg. stopwords might include words like “a”, “an”, “the”, “and”, “but”, “or”, “in”, “on”, “at”, “with”,…………
NLTK `corpus.stopwords`corpora and`tokenize`module facilitate for tokenization and stopwords removing with ease.
2. Data Lemmatization
Lemmatization is crucial step in text processing that involves reducing words to their base or root form. This process simplifies variations in word forms, enhancing text analysis by grouping similar words together that helps to limit our feature length. Large unique words can cause potential issues like memory error, or time limit exceeding, these techniques helps us to minimize our columns or feature length.
NLTK Modules
Python
import nltk
nltk.download('stopwords')
nltk.download('punkt'
nltk.download('wordnet')
|
Preprocessing Code
Python3
from nltk.corpus import stopwords
from nltk.tokenize import RegexpTokenizer
from nltk.stem import WordNetLemmatizer
wnl = WordNetLemmatizer()
stpwords = set(stopwords.words('english'))
negationwords = {"aren't", "can't", "couldn't", "no", "not", "nor", "didn't", "doesn't", "don't", "hadn't", "hasn't",
"haven't", "isn't", "mightn't", "mustn't", "needn't", "shan't", "shouldn't", "wasn't", "weren't", "won't", "wouldn't"}
stpwords = stpwords - negationwords
tokenizer = RegexpTokenizer(r'\w+')
def cleaned_reviews(text):
text = text.lower()
text = text.replace("<br />", "")
tokenized_review = nltk.word_tokenize(text)
cleaned_review=[]
for token in tokenized_review:
if token.isdigit():
pass
elif token in stpwords:
pass
else:
lemma_words = wnl.lemmatize(token)
cleaned_review.append(lemma_words)
return " ".join(cleaned_review)
cleaned_review = cleaned_reviews(text)
print(cleaned_review)
print(type(cleaned_review))
|
Output:
mature intelligent highly charged melodrama unbelivebly filmed china 1948. wei wei 's stunning performance catylast love triangle simply stunning oppurunity see magnificent film take
<class 'str'>
3. Building Vocabulary and Vectorization
Building a vocabulary refers to the process of selecting and retaining a limited set of meaningful unique words after preprocessing text data. In the context mentioned, our goal is to minimize our vocabulary size by extracting feature words, stemming them, tokenizing the text and removing stopwords. Each action perfomed to text is for minimizing our bag size rather than keeping all the words and maintaining their count per document it is good to keep only relevant and meaningful text.
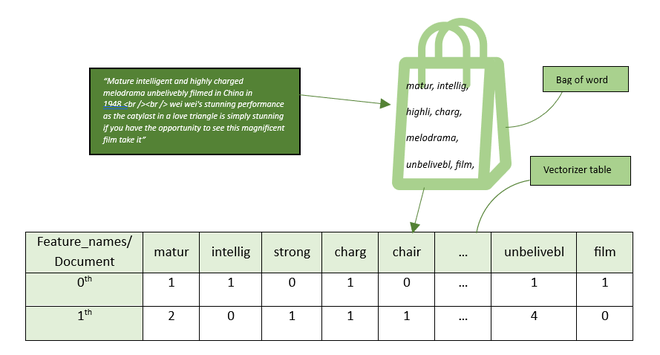
Building Vocabulary & Vectorizaton
Vectorization, is a Critical process in text processing that converts the words into numeric data so that it becomes easy to do mathematical operations over them. Since, many classifiers and model which rely on statistical computation understands only numeric data. Vectorizer table stores frequency of unique words per document. This numeric data table corresponds to texts data can be used in different ML model. bruteforcely, we can achieve the same goal through word-index mapping and word count frequency but this will be time consuming task and also inefficient.
Fortunately, Scikit-learn offers `feature_extraction.text.CountVectorizer`module for streamlining the process in fast & efficient manner.
Python3
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer(ngram_range=(1, 1))
def vectorize_text(cleaned_review):
vector = cv.fit_transform(cleaned_review).toarray()
return vector
vector = vectorize_text([cleaned_review])
print(vector)
|
Output:
[[1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 1 1 1 2]]
This vectorized_train_x is resultant numeric table and is ready to be used for training model.
Pipeline Function For Text to Numeric Vector
Python
def Data_pipeline(reviews):
Reviews = []
for text in reviews:
Reviews.append(cleaned_reviews(text))
vector = vectorize_text(Reviews)
return vector
rev = df.review.iloc[:5].values
vect = Data_pipeline(rev)
print(vect)
|
Output:
[[1 0 0 ... 0 0 0]
[0 1 0 ... 1 1 0]
[0 0 1 ... 0 0 0]
[0 0 0 ... 0 0 0]
[0 0 0 ... 0 0 1]]
Conclusion
Data pipelining plays a crucial role in effective processing of text data within the field of Natural Language Processing (NLP). The complexity and variety of tasks in NLP, such as text classification, sentiment analysis, and named entity recognition facilitate a well structured pipeline.
Share your thoughts in the comments
Please Login to comment...