What’s Data Science Pipeline?
Last Updated :
21 Feb, 2023
Data Science is an interdisciplinary field that focuses on extracting knowledge from data sets that are typically huge in amount. The field encompasses analysis, preparing data for analysis, and presenting findings to inform high-level decisions in an organization. As such, it incorporates skills from computer science, mathematics, statistics, information visualization, graphic, and business.
In simple words, a pipeline in data science is “a set of actions which changes the raw (and confusing) data from various sources (surveys, feedbacks, list of purchases, votes, etc.), to an understandable format so that we can store it and use it for analysis.”
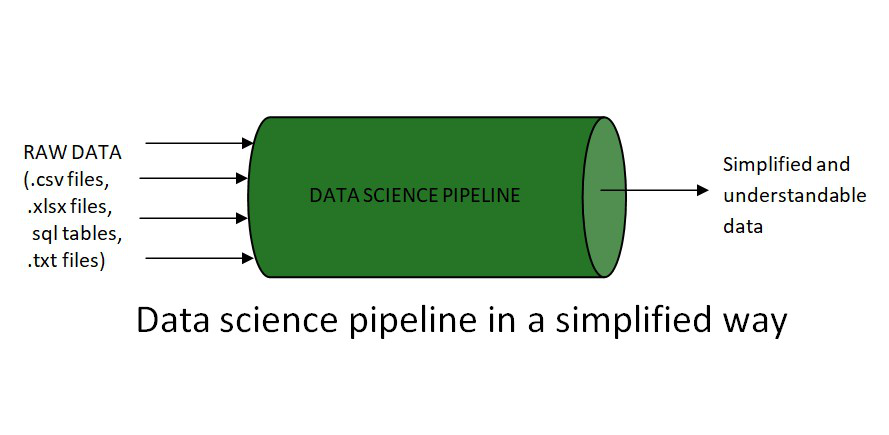
But besides storage and analysis, it is important to formulate the questions that we will solve using our data. And these questions would yield the hidden information which will give us the power to predict results, just like a wizard. For instance:
- What type of sales will reduce risks?
- Which product will sell more during a crisis?
- Which practice can bring more business?
After getting hold of our questions, now we are ready to see what lies inside the data science pipeline. When the raw data enters a pipeline, it’s unsure of how much potential it holds within. It is we data scientists, waiting eagerly inside the pipeline, who bring out its worth by cleaning it, exploring it, and finally utilizing it in the best way possible. So, to understand its journey let’s jump into the pipeline.
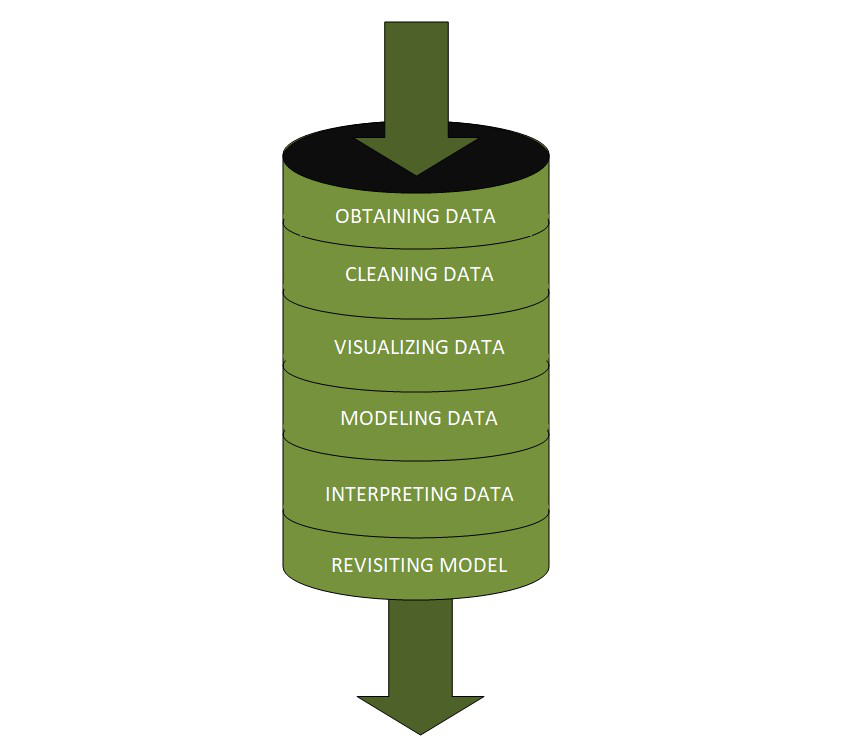
The raw data undergoes different stages within a pipeline which are:
1) Fetching/Obtaining the Data
This stage involves the identification of data from the internet or internal/external databases and extracts into useful formats. Prerequisite skills:
- Distributed Storage: Hadoop, Apache Spark/Flink.
- Database Management: MySQL, PostgreSQL, MongoDB.
- Querying Relational Databases.
- Retrieving Unstructured Data: text, videos, audio files, documents.
2) Scrubbing/Cleaning the Data
This is the most time-consuming stage and requires more effort. It is further divided into two stages:
- Examining Data:
- identifying errors
- identifying missing values
- identifying corrupt records
- Cleaning of data:
- replace or fill missing values/errors
Prerequisite skills:
- Coding language: Python, R.
- Data Modifying Tools: Python libs, Numpy, Pandas, R.
- Distributed Processing: Hadoop, Map Reduce/Spark.
3) Exploratory Data Analysis
When data reaches this stage of the pipeline, it is free from errors and missing values, and hence is suitable for finding patterns using visualizations and charts.
Prerequisite skills:
- Python: NumPy, Matplotlib, Pandas, SciPy.
- R: GGplot2, Dplyr.
- Statistics: Random sampling, Inferential.
- Data Visualization: Tableau.
4) Modeling the Data
This is that stage of the data science pipeline where machine learning comes to play. With the help of machine learning, we create data models. Data models are nothing but general rules in a statistical sense, which is used as a predictive tool to enhance our business decision-making.
Prerequisite skills:
- Machine Learning: Supervised/Unsupervised algorithms.
- Evaluation methods.
- Machine Learning Libraries: Python (Sci-kit Learn, NumPy).
- Linear algebra and Multivariate Calculus.
5) Interpreting the Data
Similar to paraphrasing your data science model. Always remember, if you can’t explain it to a six-year-old, you don’t understand it yourself. So, communication becomes the key!! This is the most crucial stage of the pipeline, wherewith the use of psychological techniques, correct business domain knowledge, and your immense storytelling abilities, you can explain your model to the non-technical audience.
Prerequisite skills:
- Business domain knowledge.
- Data visualization tools: Tableau, D3.js, Matplotlib, ggplot2, Seaborn.
- Communication: Presenting/speaking and reporting/writing.
6) Revision
As the nature of the business changes, there is the introduction of new features that may degrade your existing models. Therefore, periodic reviews and updates are very important from both business’s and data scientist’s point of view.
Conclusion
Data science is not about great machine learning algorithms, but about the solutions which you provide with the use of those algorithms. It is also very important to make sure that your pipeline remains solid from start till end, and you identify accurate business problems to be able to bring forth precise solutions.
Share your thoughts in the comments
Please Login to comment...