Time series forecasting plays a major role in data analysis, with applications ranging from anticipating stock market trends to forecasting weather patterns. In this article, we’ll dive into the field of time series forecasting using PyTorch and LSTM (Long Short-Term Memory) neural networks. We’ll uncover the critical preprocessing procedures that underpin the accuracy of our forecasts along the way.
Time Series Forecasting
Time series data is essentially a set of observations taken at regular periods of time. Time series forecasting attempts to estimate future values based on patterns and trends detected in historical data.
Moving averages and traditional approaches like ARIMA have trouble capturing long-term dependencies in the data. LSTM is a type of recurrent neural network, that excels at capturing dependencies through time and able to intricate patterns.
In this article, we will use Pytorch to forecast Time Series data.
Implementation of Time Series Forecasting:
Prerequisite
Dataset:
Here, we have used Yahoo Finance to get the share market dataset.
To install the Yahoo Finance, we can use the following command
!pip install yfinance
Step 1: Import the necessary libraries
Python3
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import seaborn as sns
from sklearn.preprocessing import MinMaxScaler
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
|
Step2: Loading the Dataset
In this step, we are using ‘yfinance’ library to download historical stock market data for Apple Inc. (AAPL) from Yahoo Finance.
Python3
import yfinance as yf
from datetime import date, timedelta, datetime
end_date = date.today().strftime("%Y-%m-%d")
start_date = '1990-01-01'
df = yf.download('AAPL', start=start_date, end=end_date)
|
Output:
[*********************100%%**********************] 1 of 1 completed
Step 3: Data Preprocessing
Plot the time series trend using Matplotlib
Python3
def data_plot(df):
df_plot = df.copy()
ncols = 2
nrows = int(round(df_plot.shape[1] / ncols, 0))
fig, ax = plt.subplots(nrows=nrows, ncols=ncols,
sharex=True, figsize=(14, 7))
for i, ax in enumerate(fig.axes):
sns.lineplot(data=df_plot.iloc[:, i], ax=ax)
ax.tick_params(axis="x", rotation=30, labelsize=10, length=0)
ax.xaxis.set_major_locator(mdates.AutoDateLocator())
fig.tight_layout()
plt.show()
data_plot(df)
|
Output :
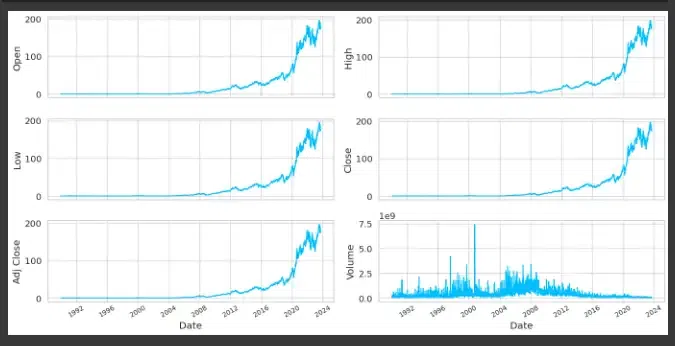
Line plots showing the features of Apple Inc. stock through time
Splitting the dataset into test and train
We follow the common practice of splitting the data into training and testing set. We calculate the length of the training datasets and print their respective shapes to confirm the split. Generally, the split is 80:20 for training and test set.
Python3
training_data_len = math.ceil(len(df) * .8)
training_data_len
train_data = df[:training_data_len].iloc[:,:1]
test_data = df[training_data_len:].iloc[:,:1]
print(train_data.shape, test_data.shape)
|
Output:
(6794, 1) (1698, 1)
Preparing Training and Testing Dataset
Here, we are choosing the feature (‘Open’ prices), reshaping it into the necessary 2D format, and validating the resulting shape to make sure it matches the anticipated format for model input, this method prepares the training data for use in a neural network.
Training Data
Python3
# Selecting Open Price values
dataset_train = train_data.Open.values
# Reshaping 1D to 2D array
dataset_train = np.reshape(dataset_train, (-1,1))
dataset_train.shape
|
Output:
(6794, 1)
Testing Data
Python3
dataset_test = test_data.Open.values
dataset_test = np.reshape(dataset_test, (-1,1))
dataset_test.shape
|
Output:
(1698, 1)
We carefully prepared the training and testing datasets to guarantee that our model could produce accurate predictions. We made the issue one that was suited for supervised learning by creating sequences with the proper lengths and their related labels.
Normalization
We have applied Min-Max scaling which is a standard preprocessing step in machine learning and time series analysis, to the dataset_test data. It adjusts the values to be between [0, 1], allowing neural networks and other models to converge more quickly and function better. The normalized values are contained in the scaled_test array as a consequence, ready to be used in modeling or analysis.
Python3
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(0,1))
scaled_train = scaler.fit_transform(dataset_train)
print(scaled_train[:5])
scaled_test = scaler.fit_transform(dataset_test)
print(*scaled_test[:5])
|
Output:
[0.] [0.00162789] [0.00062727] [0.00203112] [0.00212074]
Transforming the data into Sequence
In this step, it is necessary to separate the time-series data into X_train and y_train from the training set and X_test and y_test from the testing set. Time series data are transformed into a supervised learning problem that may be used to develop the model. While iterating through the time series data, the loop generates input/output sequences of length 50 for training data and sequences of length 30 for the test data. We can predict future values using this technique while taking into account the data’s temporal dependence on earlier observations.
We prepare the training and testing data for a neural network by generating sequences of a given length and their related labels. It then converts these sequences to NumPy arrays and PyTorch tensors.
Training Data
Python3
sequence_length = 50
X_train, y_train = [], []
for i in range(len(scaled_train) - sequence_length):
X_train.append(scaled_train[i:i+sequence_length])
y_train.append(scaled_train[i+1:i+sequence_length+1])
X_train, y_train = np.array(X_train), np.array(y_train)
X_train = torch.tensor(X_train, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32)
X_train.shape,y_train.shape
|
Output:
(torch.Size([6744, 50, 1]), torch.Size([6744, 50, 1]))
Testing Data
Python3
sequence_length = 30
X_test, y_test = [], []
for i in range(len(scaled_test) - sequence_length):
X_test.append(scaled_test[i:i+sequence_length])
y_test.append(scaled_test[i+1:i+sequence_length+1])
X_test, y_test = np.array(X_test), np.array(y_test)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_test = torch.tensor(y_test, dtype=torch.float32)
X_test.shape, y_test.shape
|
Output:
(torch.Size([1668, 30, 1]), torch.Size([1668, 30, 1]))
To make the sequences compatible with our deep learning model, the data was subsequently transformed into NumPy arrays and PyTorch tensors.
Step 4: Define LSTM class model
Now, we defined a PyTorch network using LSTM architecture. The class consist of LSTM layer and linear layer. In LSTMModel class, we initialized parameters-
- input_size : number of features in the input data at each time step
- hidden_size : hidden units in LSTM layer
- num_layers : number of LSTM layers
- batch_first= True: input data will have the batch size as the first dimension
The function super(LSTMModel, self).__init__() initializes the parent class for building the neural network.
The forward method defines the forward pass of the model, where the input x is processed through the layers of the model to produce an output.
Python3
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers):
super(LSTMModel, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
out = self.linear(out)
return out
|
Check Hardware Availability
For the PyTorch code, we need to check the hardware resources.
Python3
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
|
Output:
cuda
Defining the model
Now, we define the model, loss function and optimizer for the forecasting. We have adjusted the hyperparameters of the model and set the loss fuction to mean squared error. To optimize the parameters during the training, we have considered Adam optimizer.
Python3
input_size = 1
num_layers = 2
hidden_size = 64
output_size = 1
model = LSTMModel(input_size, hidden_size, num_layers).to(device)
loss_fn = torch.nn.MSELoss(reduction='mean')
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
print(model)
|
Output:
LSTMModel(
(lstm): LSTM(1, 32, num_layers=2, batch_first=True)
(linear): Linear(in_features=32, out_features=1, bias=True)
)
Step 5: Creating Data Loader for batch training
Data loader play an essential role during the training and evaluation phase. So, we have prepared the data for batch training and testing by creating data loader objects.
Python3
batch_size = 16
train_dataset = torch.utils.data.TensorDataset(X_train, y_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataset = torch.utils.data.TensorDataset(X_test, y_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
|
Step 6: Model Training & Evaluations
Now, we built a training loop for 50 epochs. In the provided code snippet, the model processes mini batches of training data and compute loss and update the parameters.
Python3
num_epochs = 50
train_hist =[]
test_hist =[]
for epoch in range(num_epochs):
total_loss = 0.0
model.train()
for batch_X, batch_y in train_loader:
batch_X, batch_y = batch_X.to(device), batch_y.to(device)
predictions = model(batch_X)
loss = loss_fn(predictions, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
average_loss = total_loss / len(train_loader)
train_hist.append(average_loss)
model.eval()
with torch.no_grad():
total_test_loss = 0.0
for batch_X_test, batch_y_test in test_loader:
batch_X_test, batch_y_test = batch_X_test.to(device), batch_y_test.to(device)
predictions_test = model(batch_X_test)
test_loss = loss_fn(predictions_test, batch_y_test)
total_test_loss += test_loss.item()
average_test_loss = total_test_loss / len(test_loader)
test_hist.append(average_test_loss)
if (epoch+1)%10==0:
print(f'Epoch [{epoch+1}/{num_epochs}] - Training Loss: {average_loss:.4f}, Test Loss: {average_test_loss:.4f}')
|
Output:
Epoch [10/50] - Training Loss: 0.0000, Test Loss: 0.0002
Epoch [20/50] - Training Loss: 0.0000, Test Loss: 0.0002
Epoch [30/50] - Training Loss: 0.0000, Test Loss: 0.0002
Epoch [40/50] - Training Loss: 0.0000, Test Loss: 0.0002
Epoch [50/50] - Training Loss: 0.0000, Test Loss: 0.0002
Plotting the Learning Curve
We have plotted the learning curve to track the progress and give us an idea, how much time time and training is required by the model to understand the patterns.
Python3
x = np.linspace(1,num_epochs,num_epochs)
plt.plot(x,train_hist,scalex=True, label="Training loss")
plt.plot(x, test_hist, label="Test loss")
plt.legend()
plt.show()
|
Output:
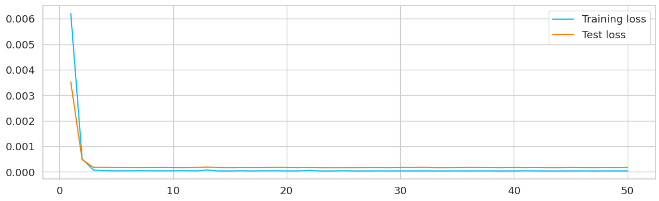
Learning Curve for Training Loss and Test Loss
Step 7: Forecasting
After training the neural network on the provided data, now comes the forecasting for next month. The model predicts the future opening price and store the future values along with their corresponding dates. Using for loop, we are going to perform a rolling forecasting, the steps are as follows –
- We have set the future time steps to 30 and converted the test sequence to numpy array and remove singleton dimensions using sequence_to_plot.
- Then, we have converted historical_data to a Pytorch tensor. The shape of the tensor is (1, sequence_length, 1), where sequence_length is the length of the historical data sequence.
- the model further predicts the next value based on the ‘historical_data_tensor’.
- The prediction is then converted to a numpy array and the first element is extracted.
Once the loop ends, we get the forecasted values, which are stored in list, and future dates are generated to create index for these values.
Python3
num_forecast_steps = 30
sequence_to_plot = X_test.squeeze().cpu().numpy()
historical_data = sequence_to_plot[-1]
print(historical_data.shape)
forecasted_values = []
with torch.no_grad():
for _ in range(num_forecast_steps*2):
historical_data_tensor = torch.as_tensor(historical_data).view(1, -1, 1).float().to(device)
predicted_value = model(historical_data_tensor).cpu().numpy()[0, 0]
forecasted_values.append(predicted_value[0])
historical_data = np.roll(historical_data, shift=-1)
historical_data[-1] = predicted_value
last_date = test_data.index[-1]
future_dates = pd.date_range(start=last_date + pd.DateOffset(1), periods=30)
combined_index = test_data.index.append(future_dates)
|
Last Step: Plotting the Prediction Graph
Once, we have forecasted the future prices, we can visualize the same using line plots. We have plotted the graph for a specific time range. The blue line is the indicator of the test data. Then we plot the last 30-time steps of the test data index using the green colored line plot.
The forecasted values are plotted using red colored line plot that uses a combined index that includes both the historic data and future dates.
Python3
plt.rcParams['figure.figsize'] = [14, 4]
plt.plot(test_data.index[-100:-30], test_data.Open[-100:-30], label = "test_data", color = "b")
original_cases = scaler.inverse_transform(np.expand_dims(sequence_to_plot[-1], axis=0)).flatten()
plt.plot(test_data.index[-30:], original_cases, label='actual values', color='green')
forecasted_cases = scaler.inverse_transform(np.expand_dims(forecasted_values, axis=0)).flatten()
plt.plot(combined_index[-60:], forecasted_cases, label='forecasted values', color='red')
plt.xlabel('Time Step')
plt.ylabel('Value')
plt.legend()
plt.title('Time Series Forecasting')
plt.grid(True)
|
Output:
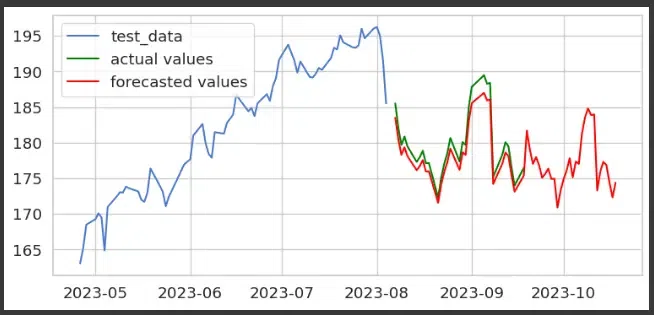
Prediction of next month Opening Price for Apple Inc. Stock
By plotting the test data, actual values and model’s forecasting data. We got a clear idea of how well the forecasted values are aligning with the actual time series.
The intriguing field of time series forecasting using PyTorch and LSTM neural networks has been thoroughly examined in this paper. In order to collect historical stock market data using Yahoo Finance module, we imported the yfinance library and started the preprocessing step. Then we applied crucial actions like data loading, train-test splitting, and data scaling to make sure our model could accurately learn from the data and make predictions.
For more accurate forecasts, additional adjustments, hyperparameter tuning, and optimization are frequently needed. To improve predicting capabilities, ensemble methods and other cutting-edge methodologies can be investigated.
We have barely begun to explore the enormous field of time series forecasting in this essay. There is a ton more to learn, from managing multi-variate time series to resolving practical problems in novel ways. With this knowledge in hand, you’re prepared to use PyTorch and LSTM neural networks to go out on your own time series forecasting adventures.
Enjoy your forecasting!
Share your thoughts in the comments
Please Login to comment...