Have you ever dreamt about becoming a songwriter? If yes, then your dream might come true by the end of this article. We will use Deep Learning to build an LSTM model by preprocessing the data using Natural Language Processing techniques. We will discuss more about them in the upcoming sections. In this article, you will learn about complex NLP techniques and about deep learning. So, Are you ready to build your own lyrics generator? Now, let’s dive into this.
Lyrics are more than just a sequence of words. Lyrics have hidden themes, emotions, and meanings. These hidden connections come from the careful arrangement of phrases in the lyrics. Now, let’s see an example lyric to understand it from an NLP perspective.
Never mind, I’ll find someone like you. I wish nothing but the best for you, too.”Someone Like You” by Adele
The sentiment analyzer interprets the phrase ‘Never mind, I’ll find someone like you’ as a mixture of sadness and determination. Furthermore, the sentiment analysis can also recognize the bittersweet sentence ‘I wish nothing but the best for you, too’ as showing a sense of goodwill towards the ex-partner despite the pain of separation. NLP techniques can interpret the complex emotions embedded within these lyrics.
Understanding the Use of Deep Learning in Lyrics Generation
As you know, data scientists spend more time in data preprocessing than building the model as it is the most crucial step in the whole process. Hence, understanding and preparing a lyric dataset is very important for building an accurate lyric generator.
We will use Natural Language Processing techniques to do this task:
- Tokenization: The first step is to break down lyrics into individual words and tokenize them.
- Word Embeddings: We will then transform the words into numerical vectors, allowing our model to understand relationships between words.
- Text Cleaning: Finally, we will clean the text by removing punctuation, converting all the text to lowercase, and handling misspellings to enhance the quality of the data.
After data preprocessing, we need to build a deep-learning model by following these steps:
- Defining the Model Architecture: First, select a deep learning framework like TensorFlow or PyTorch. We will be using TensorFlow as it is efficient for the task at hand. Then we will design a sequence of layers, usually these layers include the ‘Embedding layer’, ‘LSTM layers’, and ‘Dense Layers’.
- Compiling the Model: The second step is to choose a suitable loss function like ‘categorical cross-entropy’ and an optimizer like ‘Adam’ to update model weights during training. After choosing them we will compile the model.
- Fitting (Training) the model: The final step is to train the model, this involves dividing the preprocessed lyric data into smaller batches, feeding the batches to the model so that it can adjust its weights during several epochs (full passes through the dataset).
Building a Deep Learning Based Lyrics Generator
To build the lyric generator model we need a dataset with lots of lyrics from different artists. We will be using the Song Lyrics Dataset and follow the steps discussed below:
Step 1: Load a CSV file
Now let’s look into one of the artist’s CSV files to better understand our dataset. We are going to use Ariana Grande csv file.
Python3
import pandas as pd
arianagrande = pd.read_csv('ArianaGrande.csv')
arianagrande.head()
Output:
Artist Title Album Date \
0 Ariana Grande thank u, next thank u, next 2018-11-03
1 Ariana Grande 7 rings thank u, next 2019-01-18
2 Ariana Grande God is a woman Sweetener 2018-07-13
3 Ariana Grande Side To Side Dangerous Woman 2016-05-20
4 Ariana Grande no tears left to cry Sweetener 2018-04-20
Lyric Year
0 thought i'd end up with sean but he wasn't a m... 2018.0
1 yeah breakfast at tiffany's and bottles of bub... 2019.0
2 you you love it how i move you you love it how... 2018.0
3 ariana grande nicki minaj i've been here all ... 2016.0
4 right now i'm in a state of mind i wanna be in... 2018.0
As you can see, we have the artist’s name, title, album name, date of release, lyric and year as features. The main feature we need for our deep learning model is the Lyric column. Now let’s see if any lyric is repeated.
Python3
repeated_lyrics = arianagrande['Lyric'].value_counts()
repeated_lyrics = repeated_lyrics[repeated_lyrics > 1]
repeated_lyrics
Output:
Lyric
lyrics for this song have yet to be released please check back once the song has been released 12
lyrics for this song have yet to be released please check back once the song has been released 2
Name: count, dtype: int64
Step 2: Data Preprocessing
As you can see, a few data points are repeated and we need to handle this. Now since we need only the lyric column from all the artist’s CSV files we will write two functions namely ‘process_artist_lyrics‘, ‘combine_artist_lyrics‘ for data preprocessing. The role of each function is:
- combine_artist_lyrics: This function will iteratively load each CSV file from the csv folder of the dataset. Then the function extracts all the datapoints of the Lyric column of every artist’s csv file and concats all to one dataframe. In this way this function creates our new dataset which we will be using for training the model.
- process_artist_lyrics: This function will be used to clean the textual data(lyrics). The first step in cleaning the lyrics is to drop null values if there are any. Then the function will drop duplicate datapoints if there are any. In this way, we will clean the dataset.
Here’s how to do this:
Python3
import os
import pandas as pd
import numpy as np
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense, Dropout, Bidirectional
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
def process_artist_lyrics(artist_csv_path):
# Loading the artist's CSV file
artist_df = pd.read_csv(artist_csv_path)
# Checking for and dropping rows with null values in the 'Lyric' column
artist_df.dropna(subset=['Lyric'], inplace=True)
# Removing duplicate lyrics
artist_df.drop_duplicates(subset=['Lyric'], inplace=True)
# Extracting only the 'Lyric' column
artist_lyrics = artist_df['Lyric']
return artist_lyrics
def combine_artist_lyrics(artist_csv_directory):
csv_files = [file for file in os.listdir(artist_csv_directory) if file.endswith('.csv')]
# Initializing an empty list to store individual artist lyric DataFrames
artist_lyric_dfs = []
# Processing each artist's lyrics
for csv_file in csv_files:
artist_csv_path = os.path.join(artist_csv_directory, csv_file)
artist_lyrics = process_artist_lyrics(artist_csv_path)
artist_lyric_dfs.append(artist_lyrics)
# Concatenating the individual artist lyric DataFrames into one DataFrame
combined_lyrics_df = pd.concat(artist_lyric_dfs, ignore_index=True)
return combined_lyrics_df
artists_csv_directory = 'song-lyrics-dataset/csv/'
data = combine_artist_lyrics(artists_csv_directory)
# Converting the combined lyrics series into a DataFrame with a column name
data = pd.DataFrame(data, columns=['Lyric'])
data.head()
Output:
Lyric
0 come up to meet you tell you i'm sorry you don...
1 chris martin i used to rule the world seas wou...
2 chris martin when you try your best but you do...
3 chris martin look at the stars look how they s...
4 beyoncé and said drink from me drink from me o...
Step 3: Exploratory Data Analysis
Now let’s perform exploratory data analysis. One of the steps in this is to analyze the data by visualizing it. A few things we can do in data visualization for textual data are:
- WordCloud: This is a type of visualization that helps to analyze what words in our lyrics are repeated most by creating a cloud-based structure using words. In this visualization, the bigger the word, the more times it has been repeated.
- Bar Plot: We can plot a bar graph to count how many times a word has been repeated in all lyrics and see such top 20 words.
Python3
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(' '.join(data['Lyric']))
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title('Word Cloud of Song Lyrics')
plt.axis('off')
plt.show()
# Bar plot of most frequent words
from collections import Counter
# Combining all lyrics into a single string
all_lyrics = ' '.join(data['Lyric'])
# Split the string into words
words = all_lyrics.split()
# Counting the frequency of each word
word_counts = Counter(words)
# Getting the top 20 most frequent words
top_20_words = word_counts.most_common(20)
# Extracting words and counts
words, counts = zip(*top_20_words)
plt.figure(figsize=(12, 6))
plt.bar(words, counts, color='skyblue')
plt.title('Top 20 Most Frequent Words in Song Lyrics')
plt.xlabel('Words')
plt.ylabel('Frequency')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.show()
Output:

OUTPUT 1
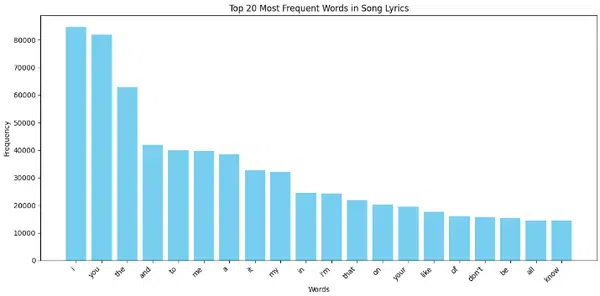
OUTPUT 2
As you can see in the second plot, ‘i’ and ‘you’ were repeated more than 80,000 times. This might make our model more biased to these words.
Step 4: Model Development
Now let’s get into the main part of this article, where we will implement the steps we discussed in the ‘Understanding the use of deep learning in lyrics generation’ section. So let’s start with data preprocessing. Here’s how to do it:
Python3
# Tokenization: Converting words into integers
tokenizer = Tokenizer()
tokenizer.fit_on_texts(data['Lyric'])
total_words = len(tokenizer.word_index) + 1
# Creating input sequences
input_sequences = []
for line in data['Lyric']:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# Padding sequences and creating predictors and label
max_sequence_length = max([len(seq) for seq in input_sequences])
input_sequences = pad_sequences(input_sequences, maxlen=max_sequence_length, padding='pre')
X, y = input_sequences[:, :-1], input_sequences[:, -1]
y = tf.keras.utils.to_categorical(y, num_classes=total_words)
# Printing the shape of padded sequences
print("Shape of padded sequences:", input_sequences.shape)
Output:
Shape of padded sequences: (2204495, 5768)
Now let’s define the architecture for our model. Since we are building a complex RNN model that will be trained on textual data, we have to take care of computation requirements. Firstly we need to install tensorflow-cpu using ‘!pip install tensorflow-cpu’. Secondly, we need 100+GB RAM to train our model, so we need to turn on ‘TPU VM v3-8’ in the Kaggle session options.
Your notebook can take a few minutes to turn on as Kaggle provides TPUs on a first come first serve basis.
Python3
# Defining a generator function for batch processing
def sequence_generator(input_sequences, labels, batch_size):
num_batches = len(input_sequences) // batch_size
while True:
for batch in range(num_batches):
start = batch * batch_size
end = (batch + 1) * batch_size
yield X[start:end, :], y[start:end, :]
# Model definition
model = Sequential()
model.add(Embedding(total_words, 100))
model.add(Bidirectional(LSTM(150, return_sequences=True)))
model.add(Dropout(0.2))
model.add(LSTM(100))
model.add(Dense(total_words // 2, activation='relu'))
model.add(Dense(total_words, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
Output:
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ embedding (Embedding) │ (None, 5768, 100) │ 6,033,200 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ bidirectional (Bidirectional) │ (None, 5768, 300) │ 301,200 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 5768, 300) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ lstm_1 (LSTM) │ (None, 100) │ 160,400 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 30166) │ 3,046,766 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 60332) │ 1,820,035,444 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Now finally let’s train our model using the fit() function.
Python3
# Training the model using fit_generator
batch_size = 32
num_epochs = 1
steps_per_epoch = len(input_sequences) // (batch_size)
model.fit_generator(
sequence_generator(X, y, batch_size),
epochs=num_epochs,
steps_per_epoch=steps_per_epoch,
verbose=1
)
OUTPUT:
48/68890 ━━━━━━━━━━━━━━━━━━━━ 455:14:32 24s/step - accuracy: 0.0093 - loss: 9.5206
Step 5: Generating lyrics on User Input
As you can see in the above output it will take a long time to train the model with just one iteration. Once the model is trained we can use it to generate new lyrics based on the first 2-3 words from input. We will generate the generate_lyrics function which will take seed text and the number of words the model should generate as parameters. The function will return both the seed text and the next predicted words. So in this way, we would have made a deep-learning model that can generate lyrics. Here’s how to do it:
Python3
# Generating lyrics
def generate_lyrics(seed_text, next_words=50):
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_length-1, padding='pre')
predicted = np.argmax(model.predict(token_list, verbose=0), axis=-1)
output_word = ""
for word, index in tokenizer.word_index.items():
if index == predicted:
output_word = word
break
seed_text += " " + output_word
return seed_text
generated_lyrics = generate_lyrics("I love")
print(generated_lyrics)
Output:
I love you baby, oh oh
She said I love you boy
I love you so
She said I love you baby, oh oh
She said I love you more than words can say
She said I love you boy
You got me singing
I love you so
You got me dancing
I love you baby
Conclusion
In this article, firstly we began by understanding the structure of lyrics with respect to NLP. Then we prepared a suitable dataset for our model. Then using Natural language Processing techniques, we cleaned and prepared our textual data. Then we designed our deep learning model’s architecture, which involved Embedding, LSTM, and Dense Layers. Finally, we trained our model with our preprocessed lyric data, allowing it to learn patterns and relationships within the lyrics.
Share your thoughts in the comments
Please Login to comment...