Scalability and Decision Tree Induction in Data Mining
Last Updated :
28 Jan, 2023
Pre-requisites: Data Mining
Scalability in data mining refers to the ability of a data mining algorithm to handle large amounts of data efficiently and effectively. This means that the algorithm should be able to process the data in a timely manner, without sacrificing the quality of the results. In other words, a scalable data mining algorithm should be able to handle an increasing amount of data without requiring a significant increase in computational resources. This is important because the amount of data available for analysis is growing rapidly, and the ability to process that data quickly and accurately is essential for making informed decisions.
There are several different types of scalability that are important in the context of data mining.
Vertical Scalability
- Vertical scalability is also known as scale-up refers to the ability of a system or algorithm to handle an increase in workload by adding more computational resources, such as faster processors or more memory. This is in contrast to horizontal scalability, which involves adding more machines to a distributed computing system to handle an increase in workload.
- Vertical scalability can be an effective way to improve the performance of a system or algorithm, particularly for applications that are limited by the computational resources available to them. By adding more resources, a system can often handle more data or perform more complex calculations, which can improve the speed and accuracy of the results. However, there are limitations to vertical scalability, and at some point, adding more resources may not result in a significant improvement in performance.
Horizontal Scalability
- Horizontal scalability, also known as scale-out, refers to the ability of a system or algorithm to handle an increase in workload by adding more machines to a distributed computing system. This is in contrast to vertical scalability, which involves adding more computational resources, such as faster processors or more memory, to a single machine.
- Horizontal scalability can be an effective way to improve the performance of a system or algorithm, particularly for applications that require a lot of computational power. By adding more machines to the system, the workload can be distributed across multiple machines, which can improve the speed and accuracy of the results. However, there are limitations to horizontal scalability, and at some point, adding more machines may not result in a significant improvement in performance. Additionally, horizontal scalability can be more complex to implement and manage than vertical scalability.
Decision Tree Induction in Data Mining
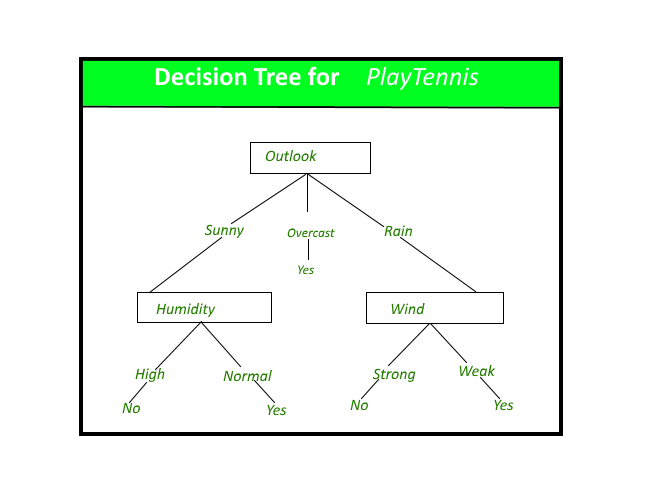
- Decision tree induction is a common technique in data mining that is used to generate a predictive model from a dataset. This technique involves constructing a tree-like structure, where each internal node represents a test on an attribute, each branch represents the outcome of the test, and each leaf node represents a prediction. The goal of decision tree induction is to build a model that can accurately predict the outcome of a given event, based on the values of the attributes in the dataset.
- To build a decision tree, the algorithm first selects the attribute that best splits the data into distinct classes. This is typically done using a measure of impurity, such as entropy or the Gini index, which measures the degree of disorder in the data. The algorithm then repeats this process for each branch of the tree, splitting the data into smaller and smaller subsets until all of the data is classified.
- Decision tree induction is a popular technique in data mining because it is easy to understand and interpret, and it can handle both numerical and categorical data. Additionally, decision trees can handle large amounts of data, and they can be updated with new data as it becomes available. However, decision trees can be prone to overfitting, where the model becomes too complex and does not generalize well to new data. As a result, data scientists often use techniques such as pruning to simplify the tree and improve its performance.
Advantages of Decision Tree Induction
- Easy to understand and interpret: Decision trees are a visual and intuitive model that can be easily understood by both experts and non-experts.
- Handle both numerical and categorical data: Decision trees can handle a mix of numerical and categorical data, which makes them suitable for many different types of datasets.
- Can handle large amounts of data: Decision trees can handle large amounts of data and can be updated with new data as it becomes available.
- Can be used for both classification and regression tasks: Decision trees can be used for both classification, where the goal is to predict a discrete outcome, and regression, where the goal is to predict a continuous outcome.
Disadvantages of Decision Tree Induction
- Prone to overfitting: Decision trees can become too complex and may not generalize well to new data. This can lead to poor performance on unseen data.
- Sensitive to small changes in the data: Decision trees can be sensitive to small changes in the data, and a small change in the data can result in a significantly different tree.
- Biased towards attributes with many levels: Decision trees can be biased towards attributes with many levels, and may not perform well on attributes with a small number of levels.
Overall, decision tree induction is a powerful technique in data mining, but it has its limitations and may not be the best choice for every problem. Data scientists should carefully consider the advantages and disadvantages of decision tree induction when selecting a predictive modeling technique for a particular task
Share your thoughts in the comments
Please Login to comment...