Data Cube or OLAP approach in Data Mining
Last Updated :
01 Feb, 2023
What is OLAP?
OLAP stands for Online Analytical Processing, which is a technology that enables multi-dimensional analysis of business data. It provides interactive access to large amounts of data and supports complex calculations and data aggregation. OLAP is used to support business intelligence and decision-making processes.
Grouping of data in a multidimensional matrix is called data cubes. In Dataware housing, we generally deal with various multidimensional data models as the data will be represented by multiple dimensions and multiple attributes. This multidimensional data is represented in the data cube as the cube represents a high-dimensional space. The Data cube pictorially shows how different attributes of data are arranged in the data model. Below is the diagram of a general data cube.
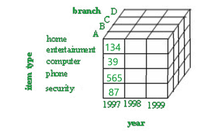
The example above is a 3D cube having attributes like branch(A,B,C,D),item type(home,entertainment,computer,phone,security), year(1997,1998,1999) .
Data cube classification:
The data cube can be classified into two categories:
- Multidimensional data cube: It basically helps in storing large amounts of data by making use of a multi-dimensional array. It increases its efficiency by keeping an index of each dimension. Thus, dimensional is able to retrieve data fast.
- Relational data cube: It basically helps in storing large amounts of data by making use of relational tables. Each relational table displays the dimensions of the data cube. It is slower compared to a Multidimensional Data Cube.
Data cube operations:
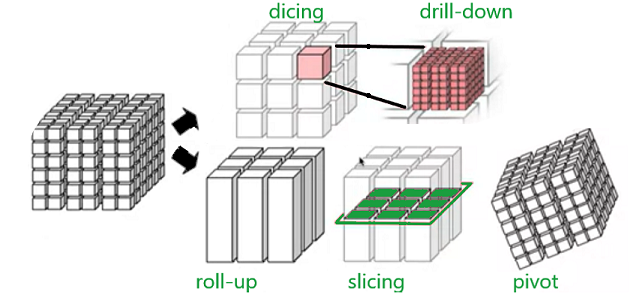
Data cube operations are used to manipulate data to meet the needs of users. These operations help to select particular data for the analysis purpose. There are mainly 5 operations listed below-
- Roll-up: operation and aggregate certain similar data attributes having the same dimension together. For example, if the data cube displays the daily income of a customer, we can use a roll-up operation to find the monthly income of his salary.
- Drill-down: this operation is the reverse of the roll-up operation. It allows us to take particular information and then subdivide it further for coarser granularity analysis. It zooms into more detail. For example- if India is an attribute of a country column and we wish to see villages in India, then the drill-down operation splits India into states, districts, towns, cities, villages and then displays the required information.
- Slicing: this operation filters the unnecessary portions. Suppose in a particular dimension, the user doesn’t need everything for analysis, rather a particular attribute. For example, country=”jamaica”, this will display only about jamaica and only display other countries present on the country list.
- Dicing: this operation does a multidimensional cutting, that not only cuts only one dimension but also can go to another dimension and cut a certain range of it. As a result, it looks more like a subcube out of the whole cube(as depicted in the figure). For example- the user wants to see the annual salary of Jharkhand state employees.
- Pivot: this operation is very important from a viewing point of view. It basically transforms the data cube in terms of view. It doesn’t change the data present in the data cube. For example, if the user is comparing year versus branch, using the pivot operation, the user can change the viewpoint and now compare branch versus item type.
Advantages of data cubes:
- Multi-dimensional analysis: Data cubes enable multi-dimensional analysis of business data, allowing users to view data from different perspectives and levels of detail.
- Interactivity: Data cubes provide interactive access to large amounts of data, allowing users to easily navigate and manipulate the data to support their analysis.
- Speed and efficiency: Data cubes are optimized for OLAP analysis, enabling fast and efficient querying and aggregation of data.
- Data aggregation: Data cubes support complex calculations and data aggregation, enabling users to quickly and easily summarize large amounts of data.
- Improved decision-making: Data cubes provide a clear and comprehensive view of business data, enabling improved decision-making and business intelligence.
- Accessibility: Data cubes can be accessed from a variety of devices and platforms, making it easy for users to access and analyze business data from anywhere.
- Helps in giving a summarised view of data.
- Data cubes store large data in a simple way.
- Data cube operation provides quick and better analysis,
- Improve performance of data.
Disadvantages of data cube:
- Complexity: OLAP systems can be complex to set up and maintain, requiring specialized technical expertise.
- Data size limitations: OLAP systems can struggle with very large data sets and may require extensive data aggregation or summarization.
- Performance issues: OLAP systems can be slow when dealing with large amounts of data, especially when running complex queries or calculations.
- Data integrity: Inconsistent data definitions and data quality issues can affect the accuracy of OLAP analysis.
- Cost: OLAP technology can be expensive, especially for enterprise-level solutions, due to the need for specialized hardware and software.
- Inflexibility: OLAP systems may not easily accommodate changing business needs and may require significant effort to modify or extend.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...