Machine Translation with Transformer in Python
Last Updated :
14 Dec, 2023
Machine translation converts a sequence of text from one language to another. Popular online translation services like Google Translate, Microsoft Translator, and others use machine translation techniques to provide users with quick and accessible translations between a wide range of languages. Transformer models are the most recent and widely adopted approach to machine translation. They are based on Seq2Seq architecture and capture context to learn the mappings between source and target languages. In this article, we will be using a model for hugging faces and fine-tuning it to convert our text from English to Hindi.
What is a Transformer?
The transformer architecture can process all the parts of input in parallel through its self-attention mechanism without the need to sequentially process them. The transformer architecture has two parts: an encoder and a decoder. If we want to build an application to convert a sentence from one language to another (English to Hindi), we need to use both the encoder and decoder blocks. This was the original problem (known as a sequence-to-sequence translation) for which the transformer architecture was developed.
However, depending on the type of task, we can either use the encoder block only or the decoder block only of the transformer architecture. The core of the encoder and decoder blocks is multi-head attention. The only difference is the use of masking in the decoder block. These layers tell the model to pay specific attention to certain elements in the input sequence and ignore others when computing the feature representations.
Helsinki-NLP is a Natural Language Processing (NLP) model that can translate different types of content. The University of Helsinki has been actively involved in various NLP projects and research endeavours. One notable project is the Helsinki-NLP GitHub repository, where the University of Helsinki’s NLP researchers and developers contribute to open-source projects related to natural language processing. This repository includes implementations, models, and tools for a variety of NLP tasks. We will use the helsinkis English to Hindi model and fine-tune it on our dataset.
Machine Translation using Transformers
1. Libraries installation
Install the below libraries if not available in your environment. These are required to run the subsequent code.
- torch is an open-source ml framework that provides flexible an efficient platform for building and training deep neural networks.
- dataset is required for loading the data on which we will finetune or model.
- transformers is required to load the pretrained model from hugging face.
- transformers[batch] contains libraries required that is required while fine tuning like accelerate.
- evaluate and sacrebleu is used for evaluation of our model.
- sentencepiece is used by the tokenizer.
!pip install datasets
!pip install transformers
!pip install sentencepiece
!pip install transformers[torch]`
!pip install sacrebleu
!pip install evaluate
!pip install sacrebleu
!pip install accelerate -U
!pip install gradio
!pip install kaleido cohere openai tiktoken typing-extensions==4.5.0
2. Dataset loading
Let us load the dataset using the dataset library.
Dataset Used
We will use cfilt/iitb-english-hindi dataset available on hugging face
The IIT Bombay English-Hindi corpus comprises parallel texts for English-Hindi and monolingual Hindi texts sourced from various existing platforms and corpora established at the Center for Indian Language Technology, IIT Bombay, over time. It is a resource for training and evaluating English-Hindi machine translation models. Researchers and developers can use the datasets to improve the accuracy and performance of machine translation systems for these languages.
To get more specific details about the “cfilt/iitb-english-hindi” dataset, including its size, source, and any specific characteristics, check the official documentation or publications from CFILT or IITB.
- The datasets library is part of the Hugging Face ecosystem and provides a convenient way to work with various datasets commonly used in natural language processing (NLP).
- The load_dataset function is designed to download and load datasets from the Hugging Face datasets hub. In this case, it’s loading the dataset associated with the identifier “cfilt/iitb-english-hindi.”
- The loaded dataset object is a dictionary-like object with keys containing different splits of the dataset ( “train,” “validation,” “test”).
Python3
from datasets import load_dataset
dataset = load_dataset("cfilt/iitb-english-hindi")
|
3. Model and Tokenizer loading
- We import two classes, AutoTokenizer and AutoModelForSeq2SeqLM, from the transformer library. These classes are part of the Hugging Face library, which provides a collection of pre-trained models and tools for working with them.
- Initialize a tokenizer for the pre-trained model specified by the identifier “Helsinki-NLP/opus-mt-en-hi.” A tokenizer is a crucial component in natural language processing that converts text into a format suitable for further processing, such as tokenizing words and converting them into numerical representations.
- Initialize a sequence-to-sequence (seq2seq) language model for the same pre-trained model (“Helsinki-NLP/opus-mt-en-hi”). A sequence-to-sequence model is a type of model commonly used for tasks like machine translation, summarization, and text generation. The AutoModelForSeq2SeqLM class is designed to handle seq2seq models, and from_pretrained loads a pre-trained model using the specified identifier.
Python3
max_length = 256
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-hi")
model = AutoModelForSeq2SeqLM.from_pretrained("Helsinki-NLP/opus-mt-en-hi")
|
Let us see the output of model on one of the validation datasets. The input sequence is: ‘Rajesh Gavre, the President of the MNPA teachers association, honoured the school by presenting the award’ .
Python3
article = dataset['validation'][2]['translation']['en']
inputs = tokenizer(article, return_tensors="pt")
translated_tokens = model.generate(
**inputs, max_length=256
)
tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
|
Output:
'एमएनएपी शिक्षकों के राष्ट्रपति, राजस्वीवर ने इस पुरस्कार को पेश करके स्कूल की प्रतिष्ठा की'
Let’s check the expected output using the following code.
Python3
dataset['validation'][2]['translation']['hi']
|
Output:
'मनपा शिक्षक संघ के अध्यक्ष राजेश गवरे ने स्कूल को भेंट देकर सराहना की।'
Let us fine tune the model.
4. Tokenize the dataset
- The preprocess_function is a function designed for preprocessing examples from a translation dataset.
- Input Extraction: We extract the English sentences from the “en” field of each example in the “translation” field of the input examples dictionary. Similarly, we extract the Hindi sentences from the “hi” field of each example in the “translation” field.
- Tokenization: The max_length parameter specifies the maximum length of the tokenized sequences, and truncation=True indicates that the sequences should be truncated if they exceed the maximum length. We tokenized the inputs and targets using the tokenizer defined above
- Label Preparation: We assigns the tokenized Hindi sentences’ input IDs to the “labels” key in the model_inputs dictionary. This step is crucial for training sequence-to-sequence models, as it provides the model with the correct target sequences during training.
- The function returns the preprocessed inputs in a format suitable for training a sequence-to-sequence model. The model_inputs dictionary likely contains tokenized representations of the English sentences and the corresponding tokenized labels (Hindi sentences) with special attention to the “labels” key for training.
Python3
def preprocess_function(examples):
inputs = [ex["en"] for ex in examples["translation"]]
targets = [ex["hi"] for ex in examples["translation"]]
model_inputs = tokenizer(inputs, max_length=max_length, truncation=True)
labels = tokenizer(targets,max_length=max_length, truncation=True)
model_inputs["labels"] = labels["input_ids"]
return model_inputs
|
We map each of the examples of our dataset using the map function.
Python3
tokenized_datasets_validation = dataset['validation'].map(
preprocess_function,
batched= True,
remove_columns=dataset["validation"].column_names,
batch_size = 2
)
tokenized_datasets_test = dataset['test'].map(
preprocess_function,
batched= True,
remove_columns=dataset["test"].column_names,
batch_size = 2)
|
5. Define the datacollator
- The purpose of DataCollatorForSeq2Seq is to take batches of examples, tokenize them using the provided tokenizer, and format them in a way suitable for training seq2seq models.
- By using the data collator, you can ensure that the input sequences and target sequences are appropriately padded and formatted before being fed into the model during training. It handles tasks such as padding sequences to the maximum length in a batch, creating attention masks, and organizing the data into the required format for seq2seq training.
- DataCollatorForSeq2Seq is a class designed to collate and process batches of data for sequence-to-sequence (seq2seq) tasks.
Python3
from transformers import DataCollatorForSeq2Seq
data_collator = DataCollatorForSeq2Seq(tokenizer, model=model)
|
6. Model training parameters
Since our model is already trianed for english to hindi translation we will freeze some layers. The model has 6 layers of encoder and decoder block. We will freeze the first four layers of encoder and decoder and train only the last two layers
Python3
for parameter in model.parameters():
parameter.requires_grad = True
num_layers_to_freeze = 10
for layer_index, layer in enumerate(model.model.encoder.layers):
print
if layer_index < len(model.model.encoder.layers) - num_layers_to_freeze:
for parameter in layer.parameters():
parameter.requires_grad = False
num_layers_to_freeze = 10
for layer_index, layer in enumerate(model.model.decoder.layers):
print
if layer_index < len(model.model.encoder.layers) - num_layers_to_freeze:
for parameter in layer.parameters():
parameter.requires_grad = False
|
7. Model evaluation
- We load the SacreBLEU metric using the load function from the evaluate module. SacreBLEU is a metric commonly used for evaluating the quality of machine-translated text. It computes a BLEU (Bilingual Evaluation Understudy) score
- The function, compute_metrics, takes the evaluation predictions (eval_preds) as input, which typically consist of model predictions (preds) and corresponding ground truth labels (labels). It performs the following steps:
- If the model returns more than the prediction logits (for example, if it returns additional information), it extracts the actual predictions.
- It uses the tokenizer to decode the predicted and ground truth sequences, skipping special tokens.
- It replaces -100s in the labels with the tokenizer’s pad token ID, as -100 is often used as a masking value in certain contexts (e.g., during training).
- It performs some simple post-processing on the decoded sequences, such as stripping leading and trailing whitespace.
- It computes the SacreBLEU score using the compute method of the loaded metric object, comparing the decoded predictions against the decoded labels.
- The function returns a dictionary containing the computed BLEU score under the key “bleu.”
Python3
import evaluate
metric = evaluate.load("sacrebleu")
import numpy as np
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
decoded_preds = [pred.strip() for pred in decoded_preds]
decoded_labels = [[label.strip()] for label in decoded_labels]
result = metric.compute(predictions=decoded_preds, references=decoded_labels)
return {"bleu": result["score"]}
|
8. Model training
- We import the Seq2SeqTrainingArguments class from the transformers library. This class is used to store and configure various training arguments specific to sequence-to-sequence tasks.
- output_dir: The directory where the fine-tuned model will be saved.
- gradient_checkpointing: Whether to use gradient checkpointing to reduce memory usage during training.
- per_device_train_batch_size: The batch size per GPU for training.
- learning_rate: The learning rate for the optimizer.
- warmup_steps: The number of warm-up steps for the learning rate scheduler.
- max_steps: The maximum number of training steps.
- fp16: Whether to use mixed-precision training (float16).
- optim: The optimizer to use (in this case, ‘adafactor’).
- evaluation_strategy: The strategy for evaluation during training.
- per_device_eval_batch_size: The batch size per GPU for evaluation.
- eval_steps: The number of steps between evaluations.
- load_best_model_at_end: Whether to load the best model at the end of training.
- metric_for_best_model: The metric used to determine the best model.
- predict_with_generate: Whether to perform generation during evaluation.
- push_to_hub: Whether to push the fine-tuned model to the Hugging Face Model Hub.
- We set up the training configuration using the Seq2SeqTrainer from the Hugging Face transformers library to train a sequence-to-sequence model.
Python3
from transformers import Seq2SeqTrainingArguments
model.to(device)
training_args = Seq2SeqTrainingArguments(
f"finetuned-nlp-en-hi",
gradient_checkpointing=True,
per_device_train_batch_size=32,
learning_rate=1e-5,
warmup_steps=2,
max_steps=2000,
fp16=True,
optim='adafactor',
per_device_eval_batch_size=16,
metric_for_best_model="eval_bleu",
predict_with_generate=True,
push_to_hub=False,
)
|
We initiate training using below code
Python3
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
model,
training_args,
train_dataset=tokenized_datasets_test,
eval_dataset=tokenized_datasets_validation,
data_collator=data_collator,
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
|
Output:
Step Training Loss
500 2.920800
1000 2.555000
1500 2.437100
2000 2.389700
Let us build a gradio app for our model and see how it works.
- import gradio as gr: Imports the Gradio library and assigns it the alias gr.
- translate(text): Defines a translation function that takes a text input and returns the translated results.
- inputs=gr.Textbox(lines=2, placeholder=’Text to translate’): Specifies the input component as a two-line textbox with a placeholder text.
- outputs=’text’: Specifies the output component as a text display.
- interface = gr.Interface(…): Creates a Gradio interface using the defined translation function and components.
- interface.launch(): Launches the Gradio interface, allowing users to input text and receive translation results interactively.
This will launch an interface which can be used for demo purpose.
Python3
import gradio as gr
def translate(text):
inputs = tokenizer(text, return_tensors="pt").to(device)
translated_tokens = model.generate(**inputs, max_length=256)
results = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
return results
interface = gr.Interface(fn=translate,inputs=gr.Textbox(lines=2, placeholder='Text to translate'),
outputs='text')
interface.launch()
|
Output:
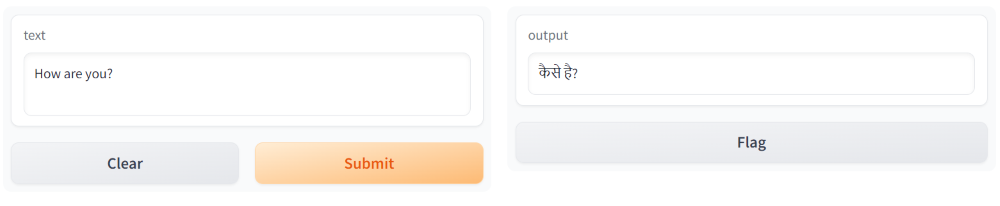
Gradio Interface
Conclusion
In this article we saw how we can load a pretrained model from hugging face and fine tune it our specific dataset for machine translation. Readers are encouraged to apply above steps for their specific dataset and can play with the hyperparameters. In order to get a reasonable output, it is recommended to use a large dataset and train for significant amount of epoch. For this access to GPU would be required.
Share your thoughts in the comments
Please Login to comment...