Translatotron 2 Speech-to-Speech Translation Architecture
Last Updated :
04 Nov, 2023
The speech-to-speech translation system translates the input audio from one language to another. These are abbreviated as S2ST (Speech to Speech Translation) systems or S2S(Speech to Speech) systems in general. The primary objective of this system is to enable communication among people who speak different languages.
Seq2Seq Model
A Seq2Seq model consists of the following three types of systems:
- ASR (Automatic Speech Recognition): This system converts the recorded voice to text in the same audio language. For our example, it will take the audio file as input and try to produce the sentence, ‘ I like watching cricket.’
- MT (machine translation): This will take the converted sentence from step 1 and translate it into the target language. In our case, it will give the output as ‘मुझे क्रिकेट देखना पसंद है’ in Hindi.
- TTS (text-to-speech synthesis): This will take the converted output text from step 2 and convert it back to audio.
The main drawback of such a system was
- High latency: As it involved the passage of data among three subsystems
- Cascading of error: The error introduced in AST caused compounding effects in MT and TTS.
Translatotron 2
In 2019, researchers at Google came up with direct speech-to-speech translation with a sequence-to-sequence model, which was the first end-to-end sequence-to-sequence model for S2ST.
This was followed by a modified architecture in 2022 called Translatotron 2: high-quality direct speech-to-speech translation with voice preservation. In this article, we will understand the Translatotron-2 architecture in detail.
Translatotron 2 Architecture
You can refer to the image for the Translatotron 2 architecture for better understanding.

Translatotron 2 Architecture
The model takes the spectrogram of source audio as input and tries to predict two things:
- The target audio spectrogram
- The target language phoneme will be used as input for the target audio spectrogram as well.
Phonemes are the basic sound units in any given language that have become incorporated into formal language systems. For many of the world’s languages, phonemes consist of various combinations of consonants (C) and vowels (V).
The model is trained on this dual objective. Once we know the target audio spectrogram it is easier to construct the sound wave using reverse Fourier transform.
There are four main components. Let’s discuss in detail each of these components.
Encoder
The encoder uses a conformer as the architecture. The conformer is a combination of transformer and CNN, hence the name ‘conformer’. Conformer was devised to combine the advantages of Transformer and convolution capturing the global contexts and local contexts, respectively.
- Input: The input to the encoder is the Mel-Spectrogram of the source speech. It takes 80 Mel channels. The frame size is of 25 ms and the frame step is 10 ms. The input is of size (batch, time, dim)
- Convolution Subsampling Layer: Audio signal is initially passed through two layers of 2d Convolution with kernel size of 3, stride of 2, and output channel of 512. This effectively downsamples the mel-spectrogram to 1/4 or to a frame step of 40 ms. The output is of size (batch, sub-sampled time, sub-sampled dimension, output channel)
- Linear Layer: The output of the previous step is transformed to (batch, sub-sampled time, sub-sampled dimension*outputchanenel) and then passed through a linear layer to project the dimension to encoder dimension. The output of this layer is (batch, sub-sampled time, encoder_dim). The typical encoder dimension is of 512.
- Conformer Block: A conformer block is composed of four modules stacked together, i.e., a feed-forward module, a self-attention module, a convolution module, and a second feed-forward module in the end.
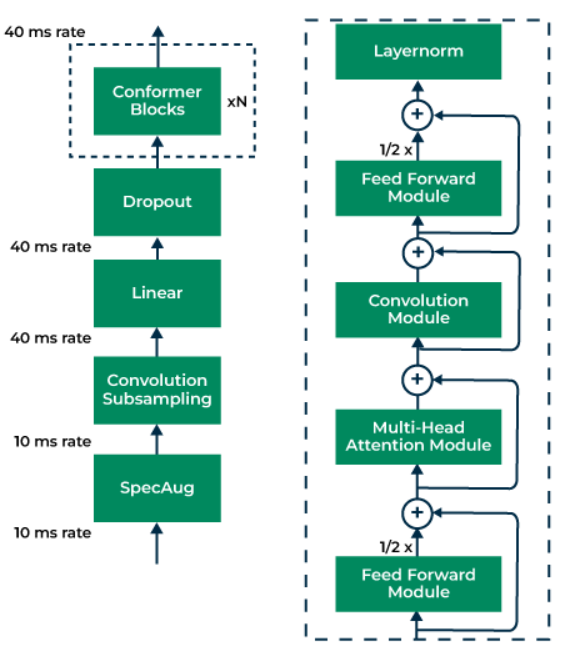
Conformer Encoder Model Architecture
- Feed-Forward Module: A feedforward module is composed of a normalization layer, two linear layers, one activation function(between the two linear layers), and a dropout. The first layer expands the dimension by an expansion factor and the second layer projects the expanded dimension back to the encoder dimension. The output of these blocks is of dimension (batch, sub-sampled time, encoder_dim).
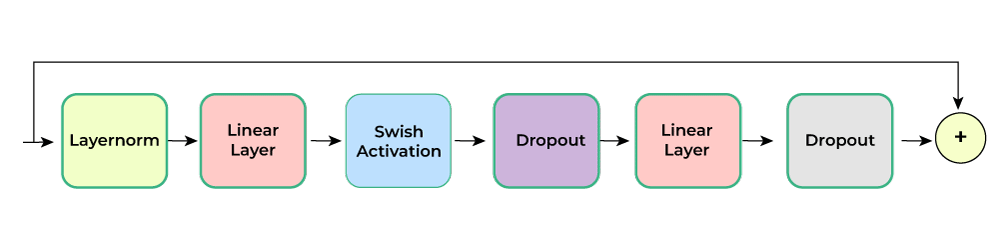
Feed Forward Module
- Convolution Module: It consists of pointwisecon1d convolution which expands the channel by an expansion factor of 2 followed by GLU activation which halves the dimension back. This is followed by a depthwise 1D convolution with kernel size of 32 and a padding to keep dimensions the same followed by swish activation and a pointwise 1D convolution with the same number of channels in input and output. The final dimension of this block is (batch, sub-sampled time, encoder_dim)
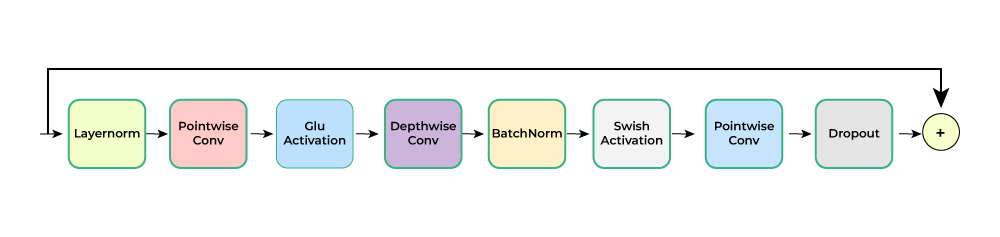
Convolution Module
- Multi-Headed Self-attention (MHSA) : Conformer employs multi-headed self-attention (MHSA) while integrating an important technique from Transformer-XL, the relative sinusoidal positional encoding scheme. The relative positional encoding allows the self-attention module to generalize better on different input lengths and the resulting encoder is more robust to the variance of the utterance length. The number of attention heads is 4 and the number of layers is 17. The encoding dimension is divided among the attention head. Thus the output of the attention layer is (batch, sub-sampled time, encoder_dim)
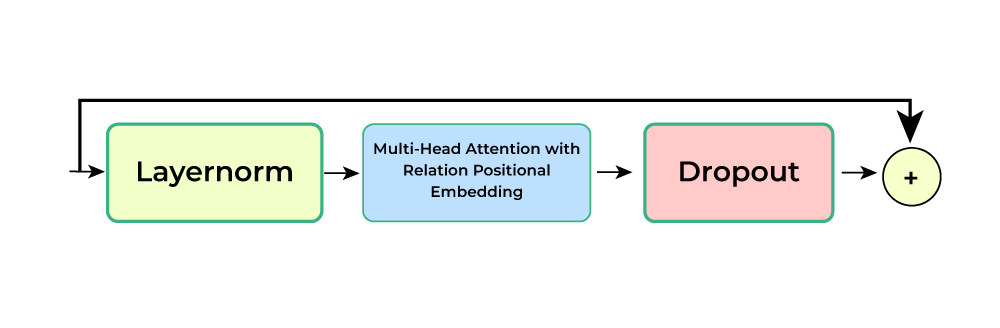
Multi-head Self-attention Module
- FeedForward Module : The same feedforwad module as above is repeated. The output dimesnion is (batch, sub-sampled time, encoder_dim)
Attention Module
The attention module serves as the bridge that connects all elements of the Translatotron architecture, including the encoder, decoder, and synthesizer. This attention mechanism plays a dual role by modeling both linguistic and acoustic alignments between the source and target speeches. It employs a multi-head attention mechanism, with queries originating from the linguistic decoder. Its primary function is to capture the alignment relationship between a sequence of source spectrograms and a shorter sequence of target phonemes.
Furthermore, the attention module provides valuable acoustic information from the source speech to the synthesizer, presenting it in a summarized form at the per-phoneme level. This summarized acoustic information not only proves to be generally adequate for the speech generation process but also simplifies the task of predicting phoneme durations since it aligns with the same granularity.
No of attention head is 8 . The hidden dimension is 512 divided among the attention head. Thus the output dimension of the attention head is the same as that of the input – (batch,sub-sampled time, encoder_dim)
Decoder
The autoregressive decoder is responsible for producing linguistic information in the translation speech. It takes the attention module, and predicts a phoneme sequence corresponding to the translation speech. It uses LSTM stack . The dimension of LSTM is same as encoder_dim. The number of stack is 6 to 4.The output from the LSTM stack is passed through a projection layer to convert it to phoneme embedding dimension which is typically 256
Speech Synthesizer
The synthesizer assumes the role of acoustically generating the translated speech. It accepts two inputs: the intermediate output from the decoder (prior to the final projection and softmax for phoneme prediction) and the contextual output derived from the attention mechanism. These inputs are concatenated, and the synthesizer utilizes this combined information to produce a Mel-Spectrogram that corresponds to the translated speech.

Speech Synthesizer of Translatotron 2
The speech synthesizer in Translatotron 2 is adopted from NAT (Non-Attentive Tacotron). NAT first predicts the duration and range of influence for each token in the input sequence. Using these two values it uses Gaussian upsampling to upsample the input. After that, an LSTM stack is used for generating the target spectrogram. A final residual convolutional block further refines the generated spectrogram
Vocoder
The spectrogram is subsequently input into a Vocoder, an abbreviation for “Voice” and “Encoder.” The Vocoder serves the purpose of both analyzing and synthesizing the human voice signal based on the information contained in the spectrogram. An exemplary instance of a Vocoder is WaveNet, a generative model realized as a deep neural network designed for generating time-domain waveforms. WaveNet excels at producing audio signals that closely resemble human speech.
Voice Preservation
In translatotron 1, Google used a separate speech encoder to generate embeddings of the speaker’s voice which was fed to the speech synthesizer. This helped in preserving the source speaker’s voice in the translated speech. However, it had a major drawback in that it could be misused for generating fake voices by playing with speech encoder embedding.
In order to mitigate this risk Google used a speech encoder only during the training to make the model learn voice preservation by training the model on parallel utterances with the same speakers’ voice on both sides. Since obtaining such a dataset is very difficult it used TTS (Text to Speech model) with a speech encoder to generate training examples.
Conclusion
When Google introduced Translatotorn 1 for end-to-end S2ST, though it performed well it was not able to match the performance of cascade S2ST. With Translatotron 2 it was able to match the performance of cascade S2ST. As per Google, the primary improvement comes from the high-level architecture i.e. the way the attention module connects the Encoder, Decoder, and Speech Synthesizer. The architectural choice of components did help in improving components but one can always experiment with those.
In June 2023 Google released Translatotron 3: Speech-to-Speech Translation with Monolingual Data. The core architecture of Translatotron 3 was the same as that of Translatotron. However, the major highlight of this paper was the ability to apply unsupervised training for speech-to-speech translation. It meant that even if we do not have a corpus of translated data between two languages, but if we have individual datasets for each language we can train Translatotron 3 to learn the mapping between these two languages !! We will explore Translatotron 3 in our future article.
Share your thoughts in the comments
Please Login to comment...