seq2seq Model in Machine Learning
Last Updated :
03 Jan, 2024
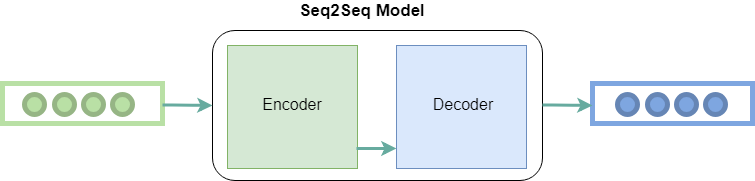
Seq2Seq model or Sequence-to-Sequence model, is a machine learning architecture designed for tasks involving sequential data. It takes an input sequence, processes it, and generates an output sequence. The architecture consists of two fundamental components: an encoder and a decoder. Seq2Seq models have significantly improved the quality of machine translation systems making them an important technology. The article aims to explore the fundamentals of the seq2seq model and its applications along with its advantages and disadvantages.
What is Seq2Seq model?
The seq2Seq model is a kind of machine learning model that takes sequential data as input and generates also sequential data as output. Before the arrival of Seq2Seq models, the machine translation systems relied on statistical methods and phrase-based approaches. The most popular approach was the use of phrase-based statistical machine translation (SMT) systems. That was not able to handle long-distance dependencies and capture global context.
Seq2Seq models addressed the issues by leveraging the power of neural networks, especially recurrent neural networks (RNN). The concept of seq2seq model was introduced in the paper titled “Sequence to Sequence Learning with Neural Networks” by Google. The architecture discussed in this research paper is fundamental framework for natural language processing tasks. The seq2seq models are encoder-decoder models. The encoder processes the input sequence and transforms it into a fixed-size hidden representation. The decoder uses the hidden representation to generate output sequence. The encoder-decoder structure allows them to handle input and output sequences of different lengths, making them capable to handle sequential data. Seq2Seq models are trained using a dataset of input-output pairs, where the input is a sequence of tokens, and the output is also a sequence of tokens. The model is trained to maximize the likelihood of the correct output sequence given the input sequence.
The advancement in neural networks architectures led to the development of more capable seq2seq model named transformers. “Attention is all you need! ” was a research paper that first introduced the transformer model in the era of Deep Learning after which language-related models have taken a huge leap. The main idea behind the transformers model was that of attention layers and different encoder and decoder stacks which were highly efficient to perform language-related tasks.
Seq2Seq models have been widely used in NLP tasks due to their ability to handle variable-length input and output sequences. Additionally, the attention mechanism is often used in Seq2Seq models to improve performance and it allows the decoder to focus on specific parts of the input sequence when generating the output.
What is Encoder and Decoder in Seq2Seq model?
In the seq2seq model, the Encoder and the Decoder architecture plays a vital role in converting input sequences into output sequences. Let’s explore about each block:
Encoder and Decoder Stack in seq2seq model
Encoder Block
The main purpose of the encoder block is to process the input sequence and capture information in a fixed-size context vector.
Architecture:
- The input sequence is put into the encoder.
- The encoder processes each element of the input sequence using neural networks (or transformer architecture).
- Throughout this process, the encoder keeps an internal state, and the ultimate hidden state functions as the context vector that encapsulates a compressed representation of the entire input sequence. This context vector captures the semantic meaning and important information of the input sequence.
The final hidden state of the encoder is then passed as the context vector to the decoder.
Decoder Block
The decoder block is similar to encoder block. The decoder processes the context vector from encoder to generate output sequence incrementally.
Architecture:
- In the training phase, the decoder receives both the context vector and the desired target output sequence (ground truth).
- During inference, the decoder relies on its own previously generated outputs as inputs for subsequent steps.
The decoder uses the context vector to comprehend the input sequence and create the corresponding output sequence. It engages in autoregressive generation, producing individual elements sequentially. At each time step, the decoder uses the current hidden state, the context vector, and the previous output token to generate a probability distribution over the possible next tokens. The token with the highest probability is then chosen as the output, and the process continues until the end of the output sequence is reached.
RNN based Seq2Seq Model
The decoder and encoder architecture utilizes RNNs to generate desired outputs. Let’s look at the simplest seq2seq model.
For a given sequence of inputs  , a RNN generates a sequence of outputs
, a RNN generates a sequence of outputs  through iterative computation based on the following equation:
through iterative computation based on the following equation:


Here,
 represents hidden state at time step t
represents hidden state at time step t  represents input at time step t
represents input at time step t  represents the weight matrix for the input
represents the weight matrix for the input represents hidden state from the previous time step (t-1)
represents hidden state from the previous time step (t-1)  represents the sigmoid activation function.
represents the sigmoid activation function.  represents output at time step t
represents output at time step t  represents the wight matrix for the output
represents the wight matrix for the output- T is the length of the sequence.
Recurrent Neural Networks can easily map sequences to sequences when the alignment between the inputs and the outputs are known in advance. Although the vanilla version of RNN is rarely used, its more advanced version i.e. LSTM or GRU is used. This is because RNN suffers from the problem of vanishing gradient. LSTM develops the context of the word by taking 2 inputs at each point in time. One from the user and the other from its previous output, hence the name recurrent (output goes as input).
Advantages of seq2seq Models
- Flexibility: Seq2Seq models can handle a wide range of tasks such as machine translation, text summarization, and image captioning, as well as variable-length input and output sequences.
- Handling Sequential Data: Seq2Seq models are well-suited for tasks that involve sequential data such as natural language, speech, and time series data.
- Handling Context: The encoder-decoder architecture of Seq2Seq models allows the model to capture the context of the input sequence and use it to generate the output sequence.
- Attention Mechanism: Using attention mechanisms allows the model to focus on specific parts of the input sequence when generating the output, which can improve performance for long input sequences.
Disadvantages of seq2seq Models
- Computationally Expensive: Seq2Seq models require significant computational resources to train and can be difficult to optimize.
- Limited Interpretability: The internal workings of Seq2Seq models can be difficult to interpret, which can make it challenging to understand why the model is making certain decisions.
- Overfitting: Seq2Seq models can overfit the training data if they are not properly regularized, which can lead to poor performance on new data.
- Handling Rare Words: Seq2Seq models can have difficulty handling rare words that are not present in the training data.
- Handling Long input Sequences: Seq2Seq models can have difficulty handling input sequences that are very long, as the context vector may not be able to capture all the information in the input sequence.
Applications of Seq2Seq model
Throughout the article, we have discovered the machine translation is the real-world application of seq2seq model. Let’s explore more applications:
- Text Summarization: The seq2seq model effectively understands the input text which makes it suitable for news and document summarization.
- Speech Recognition: Seq2Seq model, especially those with attention mechanisms, excel in processing audio waveform for ASR. They are able to capture spoken language patterns effectively.
- Image Captioning: The seq2seq model integrate image features from CNNs with textual generation capabilities for image captioning. They are capable to describe images in a human readable format.
Also Check:
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...