Data Science includes a large amount of data that performs computations and deploys models. With the deployment of the models and the development of the software the performance and the maintenance of the consistent environment may vary. So, for this Docker, an open-source platform is being introduced. It provides containers that are an excellent solution for these challenges. Docker in data science helps a person to deploy the models according to the need. It is a platform that helps build, run, and ship applications if your application is working smoothly on your machine then it should also be working properly on other machines also. This can be done with the help of Docker.

Docker for Data Science
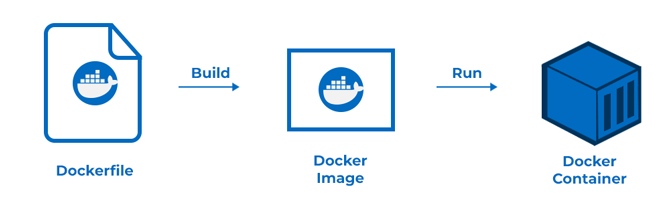
What are Docker, Containers, and Images?
Docker: Docker in data science is a part of the main work that count time in accordance os the need of data scientists. Docker employs the concept of reusable content in accordance with the framework that is worth it.
Containers: Containers are lightweight and isolated, and provide a consistent environment for running applications. They can be easily started, stopped, and managed using Docker commands, enabling seamless collaboration and deployment in data science projects. In simple terms, a container is a lightweight and isolated environment that encapsulates an application and all its dependencies.
Images: Images are files that are in a read-only format that contains all the necessary instructions for creating the container. These are used to create and start new containers at run time. Docker helps developers to package their application together with the dependencies into a container, that can on any machine that has Docker installed in it.
Containers Vs Virtual Machines
|
Resource Utilization
|
Lightweight and efficient, sharing the host OS kernel
|
Heavier, each VM runs a separate OS
|
|
Isolation
|
Process-level isolation
|
Full OS-level isolation
|
|
Startup Time
|
Seconds
|
Minutes
|
|
Portability
|
Highly portable across environments
|
Less portable due to OS dependencies
|
|
Performance
|
Near-native performance
|
Slightly lower due to virtualization overhead
|
|
Scalability
|
Easy to scale horizontally by adding more containers
|
Scaling requires additional VMs
|
|
Management
|
Easier to manage and deploy using container orchestration tools
|
More complex management due to VM infrastructure
|
Why Docker for Data Scientists?
Docker offers various benefits for data scientists such as :
- Reproducibility: Dockers allows to pack the entire data science includes libraries, frameworks, and even specific versions of various software into a container. This ensures that code must run consistently across various environments and helps it to share easily with anyone.
- Portability: After creating a container that encapsulate theentire data science workflow it can be easily shared to and deployed on various machines. with the help of the portability you can eliminate the need to manually set up and configure the environment.
- Isolations: Between the data science science applications and the hosts systems dockers heps to provide alevel of isolation. This isolation helps in large areas of datasets. This means that without worrying about the conflicts this is useful with large working datasets.
- Scalability: With the help of Dockers containers one can easily scaled up and down, It allows to run data science applications ona single machine or able to distribute the load across the machines.
Setting Up your Data Science Docker Container
Step 1: First you need to install docker in your system, Visist to the official website (https://www.docker.com/) and download the versions that fufil the requirement of your system.
Step 2: Create a Dockerfile Create a new file in your project directory called “Dockerfile”. The Dockerfile is a text file that contains instructions to build your Docker image.
Here’s a basic example: In this example we are using official Python 3.9 image as the base. We set the working directory, copy the requirements.txt file, install dependencies, copy the rest of the project files, and set the command to run your_script.py when the container starts. Adjust this file according to your specific needs.
# Use a base image with the desired operating system and dependencies
FROM python:3.9
# Set the working directory in the container
WORKDIR /app
# Copy the requirements.txt file and install dependencies
COPY requirements.txt .
RUN pip install -r requirements.txt
# Copy the rest of your project files to the container
COPY .
# Set the command to run when the container starts
CMD ["python", "your_script.py"]
Step 3: Create requirements.txt Create a requirements.txt file in your project directory that lists all the Python packages your project depends on. For example:List all the packages and their versions that you need for your data science project.
numpy==1.19.5
pandas==1.3.0
scikit-learn==0.24.2
Step 4: Build the Docker image Open a terminal or command prompt, navigate to your project directory, and run the following command to build your Docker image:
Python3
docker build -t my_data_science_image
|
This command tells Docker to build an image using the Dockerfile in the current directory and tag it as “my_data_science_image” (you can choose your own name).
Step 5: Run the Docker container Once the image is built, you can run a container based on that image. Use the following command: To know more docker commands refer to the Docker – Instruction Commands.
Python3
docker run -it my_data_science_image
|
This command starts a new container based on the “my_data_science_image” image and opens an interactive terminal session inside the container.
Step 6: Execute your data science code Once inside the container, you can execute your data science code as you would on your local machine. For example, if your Dockerfile’s CMD instruction runs “your_script.py”, you can execute it by simply running:
That’s it! You now have a Docker container set up for your data science project. You can distribute this container to others or deploy it on different machines, ensuring a consistent and reproducible environment for your data science work.
Note: Remember to update your Dockerfile and requirements.txt as your project evolves and new dependencies are added.
Dockerizing a Simple Python Application for Data Science
Step 1: Create the Data Science Application First, create a simple Python script or Jupyter notebook that includes your data science code. For example, let’s create a script called “data_analysis.py” that performs some basic data analysis:
Python3
import pandas as pd
data = pd.read_csv('data.csv')
|
Save this script in a directory called “myapp”. and create one more file called myapp in the myapp directory.
Step 2: Create a Dockerfile Next, create a Dockerfile in the same directory as your application. The Dockerfile is used to build a Docker image. Here’s an example:
Python3
FROM python:3.9-slim
WORKDIR /app
COPY myapp .
RUN apt-get update && \
apt-get install -y --no-install-recommends \
build-essential \
libgomp1 \
&& \
rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip install -r requirements.txt
CMD ["python", "data_analysis.py"]
|
In this example, we’re using the official Python 3.9 slim image as the base. We set the working directory to “/app” in the container, copy the application files from the host to the container, install additional dependencies required for data science (e.g., build-essential, libgomp1), install Python packages specified in the requirements.txt file, and set the command to run “data_analysis.py” when the container starts.
Step 3: Create a requirements.txt file in your project directory that lists all the Python packages your data science project depends on. Include any packages required for data analysis, machine learning, visualization, etc. For example:
numpy==1.19.5
pandas==1.3.0
scikit-learn==0.24.2
matplotlib==3.4.3
List all the packages and their versions that you need for your data science project.
Step 4: Build the Docker Image Open a terminal or command prompt, navigate to the directory containing the Dockerfile and application files, and run the following command to build the Docker image:
This command tells Docker to build an image using the Dockerfile in the current directory and tag it as “myapp” (you can choose your own name).
Step 5: Run the Docker Container Once the image is built, you can run a container based on that image. Use the following command:
This command starts a new container based on the “myapp” image and runs the “data_analysis.py” script inside the container. It will perform the data analysis and any other tasks specified in your script. That’s it! You have successfully Dockerized your simple Python data science application. You can distribute this Docker image to others or deploy it on different machines, ensuring consistent execution of your data science project in any environment.
Note: Remember to update your Dockerfile and requirements.txt as your project evolves and new dependencies are added.
Output:
.png)
Docker file is deployed
Docker Image Vs Docker Container
Docker is a popular containerization platform, utilizes Docker images to create and run containers. Docker images are read-only templates that contain everything needed to run an application, including the code, runtime, system tools, libraries, and dependencies. These images can be easily shared and deployed across different environments, making application deployment and management more efficient. Although Docker container provides a consistent and reproducible enviornment for applications.
Practical Implementation of Dockers
Docker has revolutionized the way data science projects are managed and deployed. By leveraging the power of containers, data scientists can achieve consistent environments, efficient resource utilization, and reproducibility. Docker images provide a standardized and portable way of packaging applications, while containers offer a lightweight and isolated runtime environment. Embracing Docker in data science workflows can enhance productivity, collaboration, and the overall quality of data-driven projects.
Conclusion
In Conclusion, Docker’s containerization technology is now empowering Data Scientiests and helping them to achieve consistency, probability, and reproducibility in their various projects. It deploys process, enables efficient resources utilize and enhance collaboration.
FAQs On Docker For Data Science
1. Is Docker useful for Python?
Yes, Docker is very useful for Python. Docker allows you to containerize your Python applications, which means that you can package all of the dependencies your application needs into a single image. This makes it easy to deploy and run your Python applications on any machine, regardless of the underlying operating system or configuration.
2. Does Docker need coding?
Docker does not require coding in the sense that you do not need to be a programmer to use it. However, it is helpful to have a basic understanding of coding concepts such as variables, functions, and loops. This will help you to understand how to use Dockerfiles and other Docker commands.
Share your thoughts in the comments
Please Login to comment...