Classification vs Regression in Machine Learning
Last Updated :
06 Nov, 2023
Classification and Regression are two major prediction problems that are usually dealt with in Data Mining and Machine Learning. We are going to deal with both Classification and Regression and we will also see differences between them in this article.
Classification Algorithms
Classification is the process of finding or discovering a model or function that helps in separating the data into multiple categorical classes i.e. discrete values. In classification, data is categorized under different labels according to some parameters given in the input and then the labels are predicted for the data.
- In a classification task, we are supposed to predict discrete target variables(class labels) using independent features.
- In the classification task, we are supposed to find a decision boundary that can separate the different classes in the target variable.
The derived mapping function could be demonstrated in the form of “IF-THEN” rules. The classification process deals with problems where the data can be divided into binary or multiple discrete labels. Let’s take an example, suppose we want to predict the possibility of the winning of a match by Team A on the basis of some parameters recorded earlier. Then there would be two labels Yes and No.
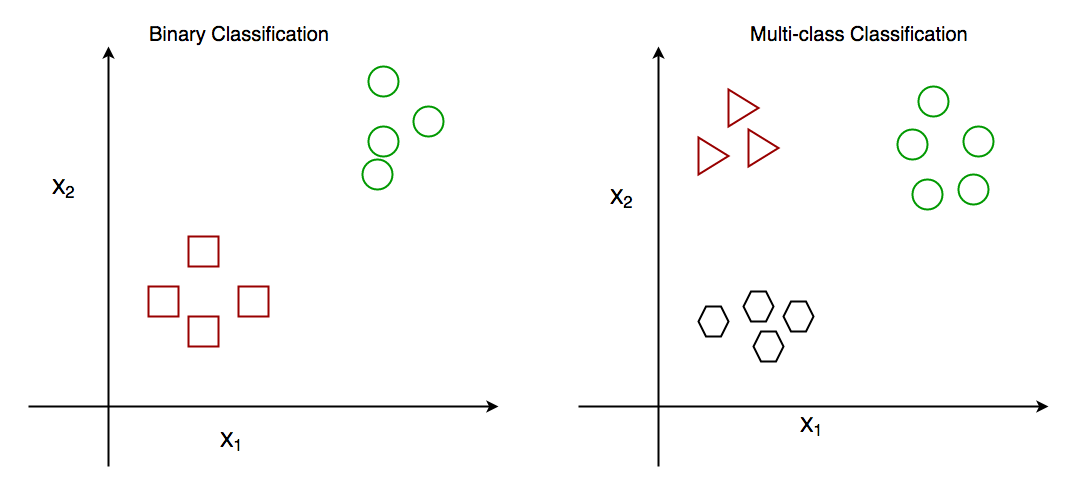
Binary Classification and Multiclass Classification
Types of Classification Algorithms
There are different types of State of the art classification algorithms that have been developed over time to give the best results for classification tasks by employing techniques like bagging and boosting.
Regression Algorithms
Regression is the process of finding a model or function for distinguishing the data into continuous real values instead of using classes or discrete values. It can also identify the distribution movement depending on the historical data. Because a regression predictive model predicts a quantity, therefore, the skill of the model must be reported as an error in those predictions.
- In a regression task, we are supposed to predict a continuous target variable using independent features.
- In the regression tasks, we are faced with generally two types of problems linear and non-linear regression.
Let’s take a similar example in regression also, where we are finding the possibility of rain in some particular regions with the help of some parameters recorded earlier. Then there is a probability associated with the rain.
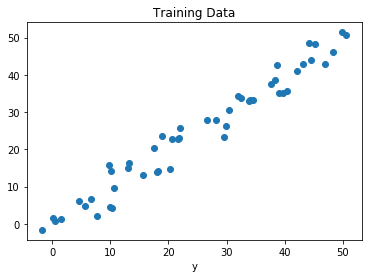
Regression of Day vs Rainfall (in mm)
Types of Regression Algorithms
There are different types of State of the art regression algorithms that have been developed over time to give the best results for regression tasks by employing techniques like bagging and boosting.
Comparison between Classification and Regression
| In this problem statement, the target variables are discrete. |
In this problem statement, the target variables are continuous. |
| Problems like Spam Email Classification, Disease prediction like problems are solved using Classification Algorithms. |
Problems like House Price Prediction, Rainfall Prediction like problems are solved using regression Algorithms. |
| In this algorithm, we try to find the best possible decision boundary which can separate the two classes with the maximum possible separation. |
In this algorithm, we try to find the best-fit line which can represent the overall trend in the data. |
| Evaluation metrics like Precision, Recall, and F1-Score are used here to evaluate the performance of the classification algorithms. |
Evaluation metrics like Mean Squared Error, R2-Score, and MAPE are used here to evaluate the performance of the regression algorithms. |
| Here we face the problems like binary Classification or Multi-Class Classification problems. |
Here we face the problems like Linear Regression models as well as non-linear models. |
| Input Data are Independent variables and categorical dependent variable. |
Input Data are Independent variables and continuous dependent variable. |
|
The classification algorithm’s task mapping the input value of x with the discrete output variable of y.
|
The regression algorithm’s task is mapping input value (x) with continuous output variable (y).
|
| Output is Categorical labels. |
Output is Continuous numerical values. |
| Objective is to Predict categorical/class labels. |
Objective is to Predicting continuous numerical values. |
| Example use cases are Spam detection, image recognition, sentiment analysis |
Example use cases are Stock price prediction, house price prediction, demand forecasting. |
|
Examples of classification algorithms are:
Logistic Regression, Decision Trees, Random Forest, Support Vector Machines (SVM), K-Nearest Neighbors (K-NN), Naive Bayes, Neural Networks, K-Means Clustering, Multi-layer Perceptron (MLP), etc.
|
Examples of regression algorithms are:
Linear Regression, Polynomial Regression, Ridge Regression, Lasso Regression, Support Vector Regression (SVR), Decision Trees for Regression, Random Forest Regression, K-Nearest Neighbors (K-NN) Regression, Neural Networks for Regression, etc.
|
When to Use Regression/Classification?
Classification trees are employed when there’s a need to categorize the dataset into distinct classes associated with the response variable. Often, these classes are binary, such as “Yes” or “No,” and they are mutually exclusive. While there are instances where there may be more than two classes, a modified version of the classification tree algorithm is used in those scenarios.
On the other hand, regression trees are utilized when dealing with continuous response variables. For instance, if the response variable represents continuous values like the price of an object or the temperature for the day, a regression tree is the appropriate choice.
There are situations where a blend of regression and classification approaches is necessary. For instance, ordinal regression comes into play when dealing with ranked or ordered categories, while multi-label classification is suitable for cases where data points can be associated with multiple classes at the same time.
Share your thoughts in the comments
Please Login to comment...