How to Calculate Jaccard Similarity in Python
Last Updated :
11 Aug, 2023
In Data Science, Similarity measurements between the two sets are a crucial task. Jaccard Similarity is one of the widely used techniques for similarity measurements in machine learning, natural language processing and recommendation systems. This article explains what Jaccard similarity is, why it is important, and how to compute it with Python.
What is Jaccard Similarity?
Jaccard Similarity also known as Jaccard index, is a statistic to measure the similarity between two data sets. It is measured as the size of the intersection of two sets divided by the size of their union.
For example: Given two sets A and B, their Jaccard Similarity is provided by,
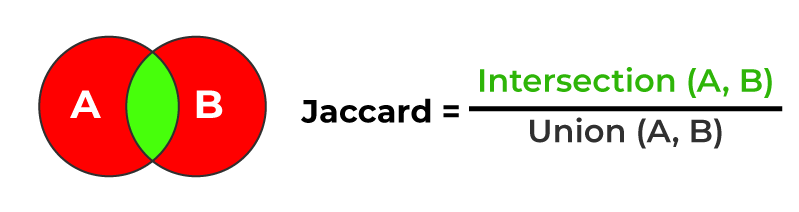
Jaccard Similarity

Where:
 is the cardinality (size) of the intersection of sets A and B.
is the cardinality (size) of the intersection of sets A and B. is the cardinality (size) of the union of sets A and B.
is the cardinality (size) of the union of sets A and B.
Jaccard Similarity is also known as the Jaccard index or Jaccard coefficient, its values lie between 0 and 1. where 0 means no similarity and the values get closer to 1 means increasing similarity 1 means the same datasets.
Computing Jaccard Similarity
EXAMPLE: 1
Python
A = {1,2,3,4,6}
B = {1,2,5,8,9}
C = A.intersection(B)
D = A.union(B)
print('AnB = ', C)
print('AUB = ', D)
print('J(A,B) = ', float(len(C))/float(len(D)))
|
Output:
AnB = {1, 2}
AUB = {1, 2, 3, 4, 5, 6, 8, 9}
J(A,B) = 0.25
EXAMPLE: 2
The Jaccard similarity can be used to compare the similarity of two sets of words, which are frequently represented as sets of unique terms.
Python3
def jaccard_similarity(set1, set2):
intersection = len(set1.intersection(set2))
union = len(set1.union(set2))
return intersection / union
set_a = {"Geeks", "for", "Geeks", "NLP", "DSc"}
set_b = {"Geek", "for", "Geeks", "DSc.", 'ML', "DSA"}
similarity = jaccard_similarity(set_a, set_b)
print("Jaccard Similarity:", similarity)
|
Output:
Jaccard Similarity: 0.25
Significance of Jaccard Similarity
The Jaccard similarity is especially effective when the order of items is irrelevant and only the presence or absence of elements is examined. It is extensively used in:
- Text Analysis: Jaccard similarity can be used in natural language processing to compare texts, text samples, or even individual words.
- Recommendation Systems: Jaccard similarity can help in finding similar items or products based on user behavior.
- Data Deduplication: Jaccard similarity can be used to find duplicate or near-duplicate records in a dataset.
- Social Network Analysis: Jaccard similarity can be used in social networks to detect similarities between user profiles or groups.
- Genomics: Jaccard similarity is employed to compare gene sets in biological studies.
Jaccard Distance
The Jaccard distance is a measure of how different two sets are i.e Unlike the Jaccard coefficient, which determines the similarity of two sets. The Jaccard distance is computed by subtracting the Jaccard coefficient from one, or by dividing the difference in the sizes of the union and the intersection of two sets by the size of the union.
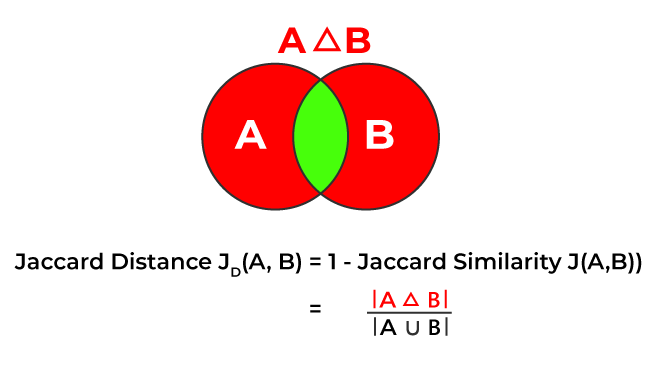
Jaccard Distance

Where:
- is the cardinality (size) of the intersection of sets A and B.
- is the cardinality (size) of the union of sets A and B.
 represents the cardinality (size) of symmetric difference of sets (A) and (B), containing elements that are in either set but not in their intersection.
represents the cardinality (size) of symmetric difference of sets (A) and (B), containing elements that are in either set but not in their intersection.
The Jaccard distance is often used to calculate a nxn matrix For clustering and multidimensional scaling of n sample sets. This distance is a collection metric for all finite sets.
Example 1:
Python3
def jaccard_distance(set1, set2):
Symmetric_difference = set1.symmetric_difference(set2)
union = set1.union(set2)
return len(Symmetric_difference)/len(union)
set_a = {"Geeks", "for", "Geeks", "NLP", "DSc"}
set_b = {"Geek", "for", "Geeks", "DSc.", 'ML', "DSA"}
distance = jaccard_distance(set_a, set_b)
print("Jaccard distance:", distance)
|
Output:
Jaccard distance: 0.75
EXAMPLE 2:
Suppose two persons, A and B, went shopping in a department store, and there are five items. Let A = {1, 1,1, 0,1} and B = {1, 1, 0, 0, 1} sets represent items they picked (1) or not (0). Then ‘Jaccard score’ will represent the similar items they bought, and Jaccard Distance measure of dissimilarity and is calculated as 1 minus the Jaccard similarity score:
Python
import numpy as np
from sklearn.metrics import jaccard_score
y_pred = np.array([1, 1, 1, 0, 1]).reshape(-1, 1)
y_true = np.array([1, 1, 0, 0, 1]).reshape(-1, 1)
jaccard_index = jaccard_score(y_true, y_pred)
jaccard_distance = 1 - jaccard_index
print("Jaccard Index:", jaccard_index)
print("Jaccard Distance:", jaccard_distance)
|
Output:
Jaccard Index: 0.75
Jaccard Distance: 0.25
Conclusion
The Jaccard similarity coefficient is a useful tool to check the similarity of sets, with applications ranging from text analysis to recommendation systems to data deduplication. You may quickly compute Jaccard similarity to improve your data analysis and decision-making processes by learning the formula and employing Python’s capabilities.
Share your thoughts in the comments
Please Login to comment...