Convolutional Block for Image Recognition
Last Updated :
03 Feb, 2023
INTRODUCTION:
The basic neural network design i.e. an input layer, few dense layers, and an output layer does not work well for the image recognition system because objects can appear in lots of different places in an image. So the solution is to add one or more convolutional layers.
A convolutional block is a building block used in a convolutional neural network (CNN) for image recognition. It is made up of one or more convolutional layers, which are used to extract features from the input image. The convolutional layers are typically followed by one or more pooling layers, which are used to reduce the spatial dimensions of the feature maps while retaining the most important information.
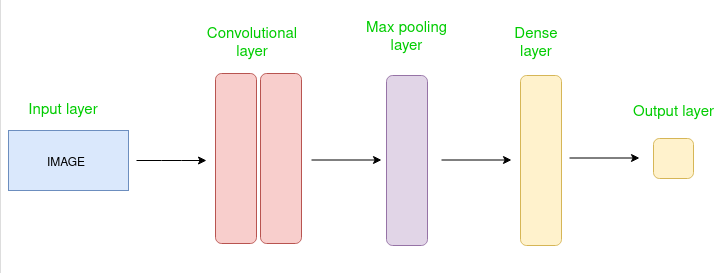
The basic structure of a convolutional block is as follows:
The input image is passed through one or more convolutional layers, where filters are applied to the image to extract features such as edges, textures, and shapes.
The output of the convolutional layers is then passed through one or more pooling layers, which are used to down-sample the feature maps. This reduces the spatial dimensions of the feature maps, making the network more computationally efficient and reducing the risk of overfitting.
The output of the pooling layers is then passed through one or more fully connected layers, which are used to make a prediction or classify the image.
Convolutional blocks are used in the initial stages of a CNN, where the primary goal is to extract features from the input image. They are typically repeated multiple times in the network, with each block extracting more complex features from the output of the previous block. This hierarchical structure allows the network to learn increasingly complex features, leading to improved image recognition performance.

Basic Neural Network
The convolutional layer aids in the detection of patterns in our image, regardless of where they occur. These layers are quite precise when it comes to locating patterns. For relatively simple images, one or two convolutional layers and a thick layer may be enough, but for complicated images, we’ll need a few extra modifications and methods to make our model more efficient.

CNN (Convolutional Neural Network)
We don’t normally need to know where in an image a pattern was detected down to the individual pixel because the convolutional layers look for patterns in our image and record whether or not they find such patterns in each section of our image. It is sufficient to have a rough idea of where it was discovered. We can use a technique called max pooling to tackle this problem.
Convolutional Neural Network with Max pooling layer
The data is reduced and just the important bits are passed on by the Max-pooling layer. It aids in reducing the amount of data to be sent to the next layer. For example, if the convolutional filter produces a grid, the max-pooling layer will identify the grid’s greatest integer. Finally, it will construct a new array that will only save the integers it has chosen. We’re still recording roughly where each pattern was located in our image but with 1/4 of the data. We’ll wind up with a virtually identical result, but it’ll be a lot less work.
Another problem with neural networks is that it tries to memorize the input data instead of learning the procedure and working. There’s a simple method to avoid this: we can force the neural network to learn as much as it can solely by memorizing the training data. The aim is to sandwich the dropout layer between other layers, which will randomly discard some of the input that passes through it by severing some of the neural network’s connections. The neural network is compelled to put up more effort to learn. Because it cannot rely on a single signal flowing through the neural network at all times, it must learn many methods to represent the same thoughts.
Dropout is a confusing concept in which we discard data to obtain a more accurate end result, but it works extremely well in practice.

Dropout layer
These 3 layers together form the Convolutional block. We can add more than one convolutional block accordingly for complex scenarios.

Convolutional Block
ADVANTAGES AND DISADVANTAGES:
Advantages of convolutional blocks in image recognition:
- They are designed to extract features from the input image, which makes them particularly well-suited for image recognition tasks.
- They are able to learn hierarchical features, which allows them to improve recognition performance.
- Pooling layers used in a convolutional block reduce the spatial dimensions of the feature maps, making the network more computationally efficient and reducing the risk of overfitting.
- They can be used to learn both local and global features, which helps to improve recognition performance.
- They are widely used in image recognition tasks, and have been shown to achieve state-of-the-art performance in many tasks.
Disadvantages of convolutional blocks in image recognition:
- They can be computationally intensive, especially when working with large images or many layers.
- They may not be appropriate for all types of image recognition tasks, such as tasks that require the recognition of small objects or fine details.
- They can be sensitive to the choice of hyperparameters, such as the number of filters and the size of the pooling window.
- They may not be as interpretable as other types of models, making it difficult to understand how the model is making its predictions.
- They are not the best solution for all image recognition tasks, other architectures such as capsule networks, transformer networks, and attention-based networks are known to perform well in some tasks.
Share your thoughts in the comments
Please Login to comment...