Apache Hive – Static Partitioning With Examples
Last Updated :
04 Jul, 2021
Partitioning in Apache Hive is very much needed to improve performance while scanning the Hive tables. It allows a user working on the hive to query a small or desired portion of the Hive tables.
Suppose we have a table student that contains 5000 records, and we want to only process data of students belonging to the ‘A’ section only. However, the student table contains student records belonging to all the sections (A, B, C, D) but with partitioning, we do not need to process all those 5000 records. Here, partitioning helps us in separating data of students according to their sections. By doing so the time to execute the query will be increased, and we do not need to scan all the other unnecessary data available inside the ‘student’ table.
Partitioning in the hive can be static or dynamic. In this article, we will be implementing static partitioning in the hive.
Features of Static Partitioning
- Partitions are manually added so it is also known as manual partition
- Data Loading in static partitioning is faster as compare to dynamic partitioning so static partitioning is preferred when we have massive files to load.
- In static partitioning individual files are loaded as per the partition we want to set.
- where clause is used in order to use limit in static partition
- Altering the partition in the static partition is allowed whereas dynamic partition doesn’t support Alter statement.
To perform the below operation make sure your hive is running. Below are the steps to launch a hive on your local system.
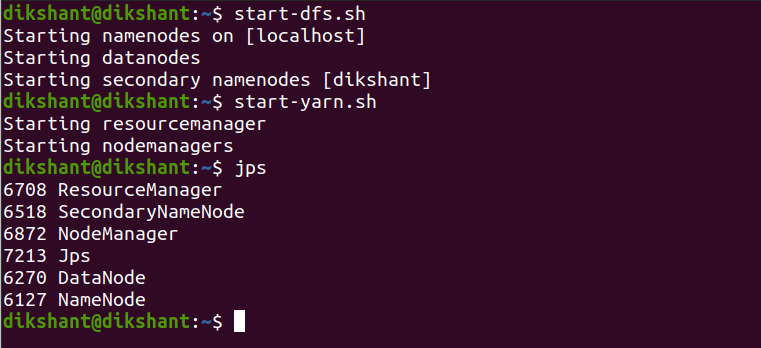
Step 1: Start all your Hadoop Daemon
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons
Step 2: Launch hive from terminal
hive
Now, we are all set to perform the quick demo.
Static Partitioning
In static partitioning, we partition the table based on some attribute. The attributes or columns we use to separate records are not present in the actual data we load to our table but we separate them using the partition statement available in Hive. The partitions are manually partitioned that’s why static partition is also known as manual partition. below is the well-explained example that helps you out to understand it well.
Step 1: Let’s create a table ‘student’ with the following attributes (student_name, father_name, and percentage ) and partition it using ‘section’ in our default database.
Note: Do not provide the partitioned columns name in create table <table-name> statement. Once you mentioned the names in the partitioned by the statement they will automatically partition with their respective attributes in the hive table.
CREATE TABLE student(student_name STRING ,father_name STRING ,percentage FLOAT)
partitioned by (section STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';

Step 2: Describe the table to see information about table attributes and partitioned columns
describe student;
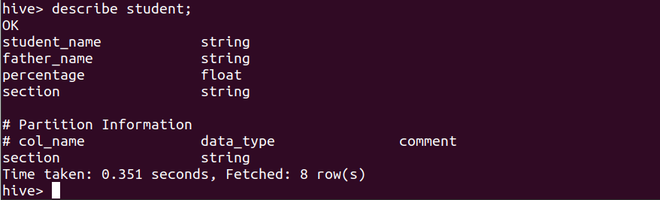
Here we can see that the section column has been marked as the partition attribute and also has been added to the table attribute list.
Step 3: Create 4 different files containing data of students from respective sections (student-A, student-B, student-C, student-D) make sure that section column which is our partition column is never added to the actual table.

Creating student table according to their sections
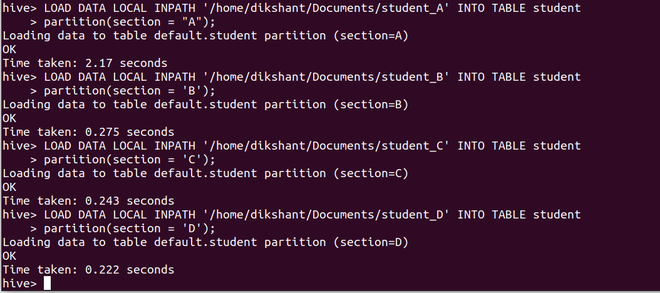
Step 4: Load the data from 4 different files containing data of student section-wise to our student table along with the partitioned attribute value.
a. Loading data from student_A partitioned with section ‘A’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_A' INTO TABLE student
partition(section = "A");
b. Loading data from student_B partitioned with section ‘B’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_B' INTO TABLE student
partition(section = 'B');
c. Loading data from student_C partitioned with section ‘C’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_C' INTO TABLE student
partition(section = 'C');
d. Loading data from student_D partitioned with section ‘D’
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/student_D' INTO TABLE student
partition(section = 'D');
Step 5: Now go to your HDFS(/user/hive/warehouse/) and check the student table to see how the partitions are made.
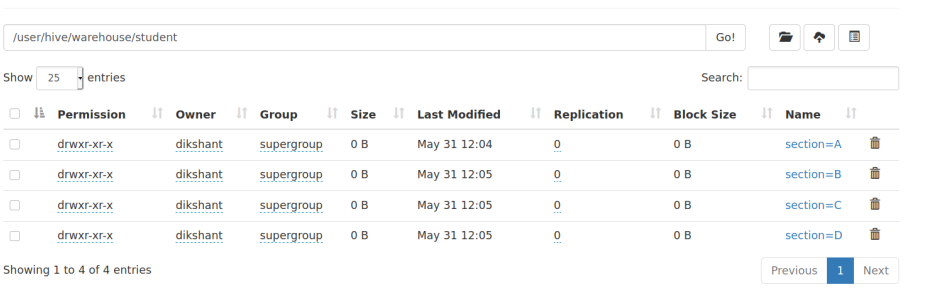
Here we can easily observe that the student table is partitioned and contain data of student in accordance to their section. Now if we want to process data of student belongs to section_A we need not traverse the whole table since it is partitioned. Each partition contains the data of the table as per the mentioned partition.
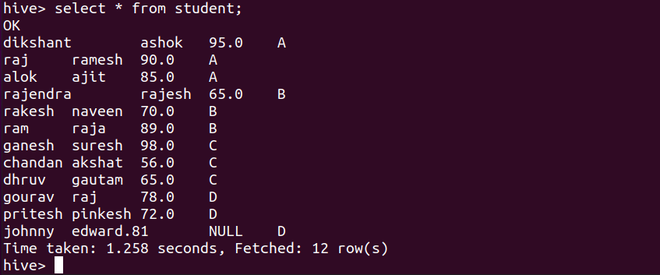
Below select query will select everything from the student table. As we can observe we haven’t added any section column but since it is mentioned manually in a partition so it is added.
select * from student;
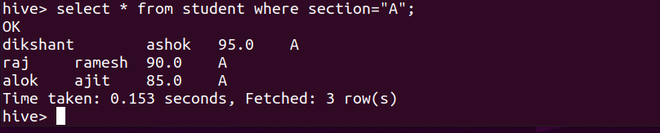
Now if we operate on this student table with where clause as seen below. Hive will never query all those 12 records. It is simply perform processing on the partition made by us in this student table. In our case, it will only query section=A partition.
select * from student where section="A";
This is how we perform static partitioning in the hive.
Share your thoughts in the comments
Please Login to comment...