Hive – Load Data Into Table
Last Updated :
24 Nov, 2020
Hive tables provide us the schema to store data in various formats (like CSV). Hive provides multiple ways to add data to the tables. We can use DML(Data Manipulation Language) queries in Hive to import or add data to the table. One can also directly put the table into the hive with HDFS commands. In case we have data in Relational Databases like MySQL, ORACLE, IBM DB2, etc. then we can use Sqoop to efficiently transfer PetaBytes of data between Hadoop and Hive. In this particular tutorial, we will be using Hive DML queries to Load or INSERT data to the Hive table.
To perform the below operation make sure your hive is running. Below are the steps to launch a hive on your local system.
Step 1: Start all your Hadoop Daemon
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons
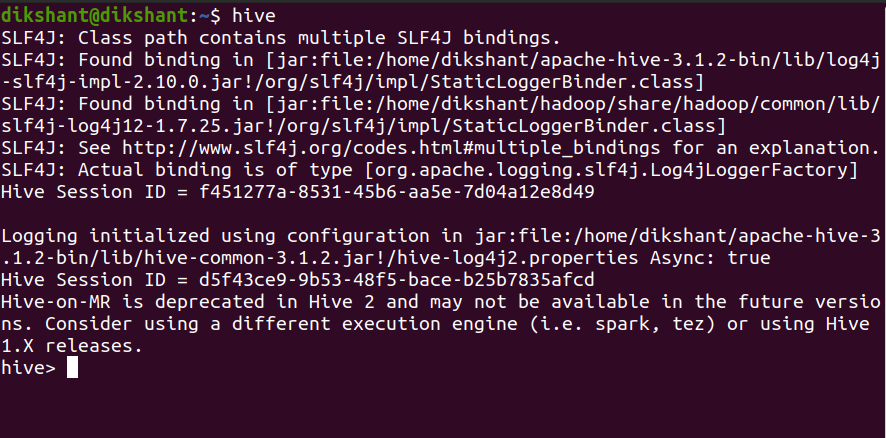
Step 2: Launch hive from terminal
hive
In hive with DML statements, we can add data to the Hive table in 2 different ways.
- Using INSERT Command
- Load Data Statement
1. Using INSERT Command
Syntax:
INSERT INTO TABLE <table_name> VALUES (<add values as per column entity>);
Example:
To insert data into the table let’s create a table with the name student (By default hive uses its default database to store hive tables).
Command:
CREATE TABLE IF NOT EXISTS student(
Student_Name STRING,
Student_Rollno INT,
Student_Marks FLOAT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
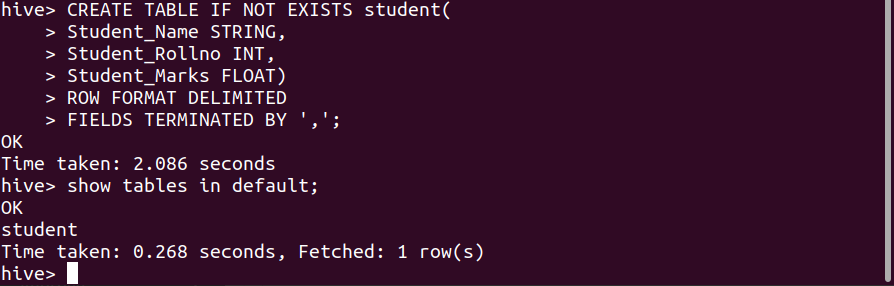
We have successfully created the student table in the Hive default database with the attribute Student_Name, Student_Rollno, and Student_Marks respectively.
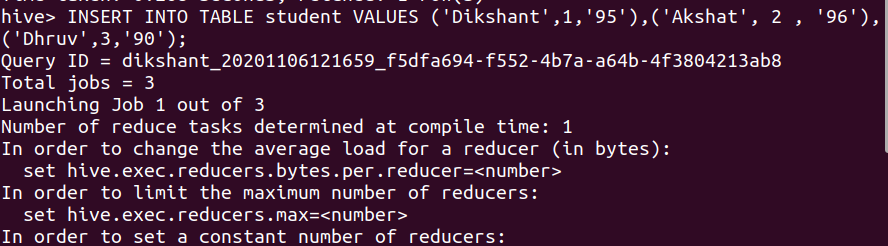
Now, let’s insert data into this table with an INSERT query.
INSERT Query:
INSERT INTO TABLE student VALUES ('Dikshant',1,'95'),('Akshat', 2 , '96'),('Dhruv',3,'90');
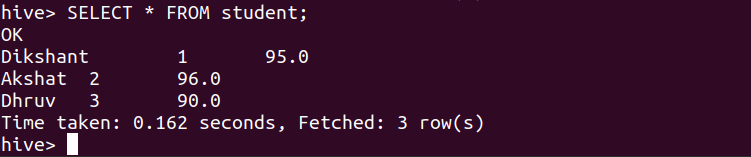
We can check the data of the student table with the help of the below command.
SELECT * FROM student;
2. Load Data Statement
Hive provides us the functionality to load pre-created table entities either from our local file system or from HDFS. The LOAD DATA statement is used to load data into the hive table.
Syntax:
LOAD DATA [LOCAL] INPATH '<The table data location>' [OVERWRITE] INTO TABLE <table_name>;
Note:
- The LOCAL Switch specifies that the data we are loading is available in our Local File System. If the LOCAL switch is not used, the hive will consider the location as an HDFS path location.
- The OVERWRITE switch allows us to overwrite the table data.
Let’s make a CSV(Comma Separated Values) file with the name data.csv since we have provided ‘,’ as a field terminator while creating a table in the hive. We are creating this file in our local file system at ‘/home/dikshant/Documents’ for demonstration purposes.
Command:
cd /home/dikshant/Documents // To change the directory
touch data.csv // use to create data.csv file
nano data.csv // nano is a linux command line editor to edit files
cat data.csv // cat is used to see content of file
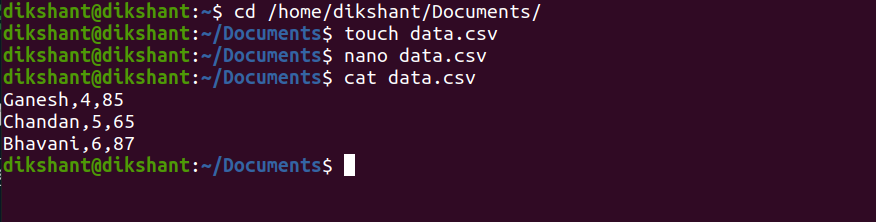
LOAD DATA to the student hive table with the help of the below command.
LOAD DATA LOCAL INPATH '/home/dikshant/Documents/data.csv' INTO TABLE student;

Let’s see the student table content to observe the effect with the help of the below command.
SELECT * FROM student;
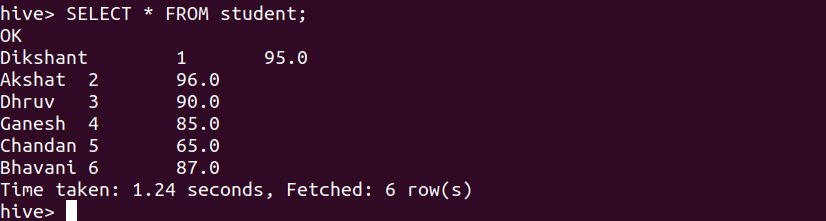
We can observe that we have successfully added the data to the student table.
Share your thoughts in the comments
Please Login to comment...