Hadoop – Daemons and Their Features
Last Updated :
15 Mar, 2024
Daemons mean Process. Hadoop Daemons are a set of processes that run on Hadoop. Hadoop is a framework written in Java, so all these processes are Java Processes.
Apache Hadoop 2 consists of the following Daemons:
- NameNode
- DataNode
- Secondary Name Node
- Resource Manager
- Node Manager
Namenode, Secondary NameNode, and Resource Manager work on a Master System while the Node Manager and DataNode work on the Slave machine.
1. NameNode
NameNode works on the Master System. The primary purpose of Namenode is to manage all the MetaData. Metadata is the list of files stored in HDFS(Hadoop Distributed File System). As we know the data is stored in the form of blocks in a Hadoop cluster. So the DataNode on which or the location at which that block of the file is stored is mentioned in MetaData. All information regarding the logs of the transactions happening in a Hadoop cluster (when or who read/wrote the data) will be stored in MetaData. MetaData is stored in the memory.
Features:
- It never stores the data that is present in the file.
- As Namenode works on the Master System, the Master system should have good processing power and more RAM than Slaves.
- It stores the information of DataNode such as their Block id’s and Number of Blocks
How to start Name Node?
hadoop-daemon.sh start namenode
How to stop Name Node?
hadoop-daemon.sh stop namenode

2. DataNode
DataNode works on the Slave system. The NameNode always instructs DataNode for storing the Data. DataNode is a program that runs on the slave system that serves the read/write request from the client. As the data is stored in this DataNode, they should possess high memory to store more Data.
How to start Data Node?
hadoop-daemon.sh start datanode
How to stop Data Node?
hadoop-daemon.sh stop datanode

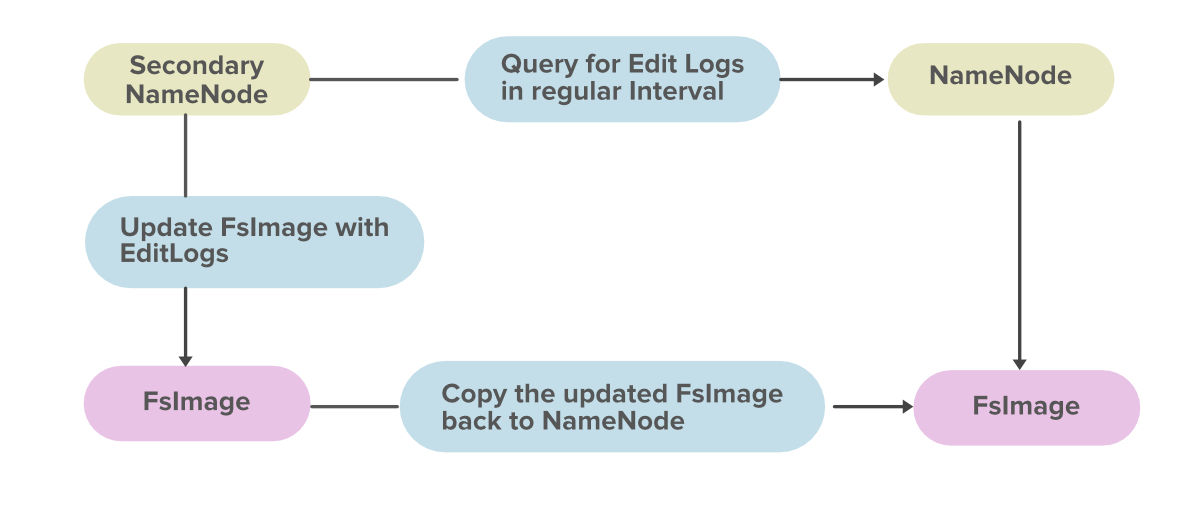
3. Secondary NameNode
Secondary NameNode is used for taking the hourly backup of the data. In case the Hadoop cluster fails, or crashes, the secondary Namenode will take the hourly backup or checkpoints of that data and store this data into a file name fsimage. This file then gets transferred to a new system. A new MetaData is assigned to that new system and a new Master is created with this MetaData, and the cluster is made to run again correctly.
This is the benefit of Secondary Name Node. Now in Hadoop2, we have High-Availability and Federation features that minimize the importance of this Secondary Name Node in Hadoop2.
Major Function Of Secondary NameNode:
- It groups the Edit logs and Fsimage from NameNode together.
- It continuously reads the MetaData from the RAM of NameNode and writes into the Hard Disk.
As secondary NameNode keeps track of checkpoints in a Hadoop Distributed File System, it is also known as the checkpoint Node.
| The Hadoop Daemon’s |
Port |
| Name Node |
50070 |
| Data Node |
50075 |
| Secondary Name Node |
50090 |
These ports can be configured manually in hdfs-site.xml and mapred-site.xml files.
4. Resource Manager
Resource Manager is also known as the Global Master Daemon that works on the Master System. The Resource Manager Manages the resources for the applications that are running in a Hadoop Cluster. The Resource Manager Mainly consists of 2 things.
A. ApplicationsManager
B. Scheduler
An Application Manager is responsible for accepting the request for a client and also makes a memory resource on the Slaves in a Hadoop cluster to host the Application Master. The scheduler is utilized for providing resources for applications in a Hadoop cluster and for monitoring this application.
How to start ResourceManager?
yarn-daemon.sh start resourcemanager
How to stop ResourceManager?
stop:yarn-daemon.sh stop resourcemanager

5. Node Manager
The Node Manager works on the Slaves System that manages the memory resource within the Node and Memory Disk. Each Slave Node in a Hadoop cluster has a single NodeManager Daemon running in it. It also sends this monitoring information to the Resource Manager.
How to start Node Manager?
yarn-daemon.sh start nodemanager
How to stop Node Manager?
yarn-daemon.sh stop nodemanager

In a Hadoop cluster, Resource Manager and Node Manager can be tracked with the specific URLs, of type http://:port_number
| The Hadoop Daemon’s |
Port |
| ResourceManager |
8088 |
| NodeManager |
8042 |
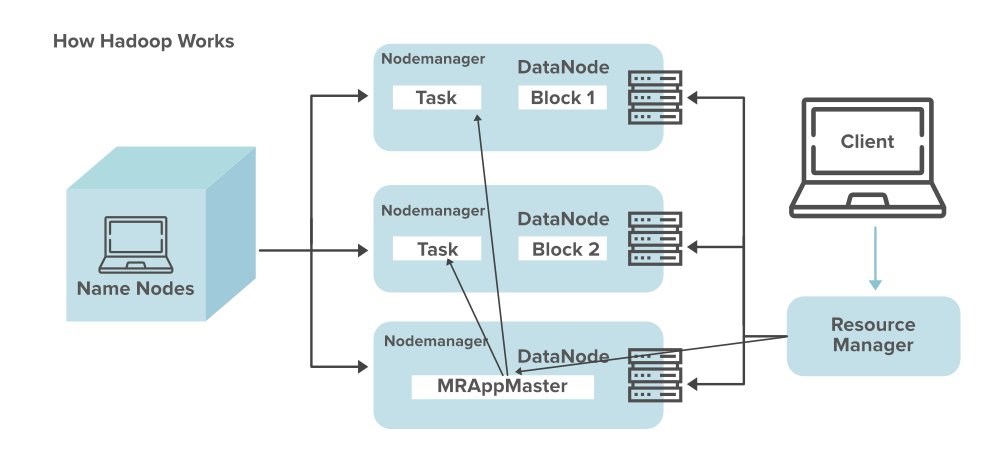
The below diagram shows how Hadoop works.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...