Word Movers Distance (WMD) in NLP
Last Updated :
06 Mar, 2024
Text similarity is a very widely used technique for optimized searching, text mining, etc. Have you ever thought about how the search results come in order when we search on Google? The query we write on the search bar is matched with the names of the websites and then the most similar content is shown above.
As a human, it is very easy for us to identify which text is similar and which is not but how will it be possible for machines? There are many methods that one can use to let machines identify how the texts are similar. Some of them are cosine similarity, Count vectorizer, TF-IDF, etc.
Today, we will learn about one more technique, i.e. Word Mover’s Distance, to know how much two sentences are similar or different to each other.
Word Mover’s Distance
Word Mover’s distance is a tool that we can use to calculate the distance between two sentences. It uses pre-trained word embeddings. Word embeddings are simply words that are encoded into numbers. Similar words tend to have vectors that are closer to each other in vector space. We can use several methods to generate word embeddings like word2vec. We use word embeddings for calculating the distance. Before moving forward let’s take a look at Earth Mover’s Distance.
Earth Mover’s Distance
Word mover’s distance is based on the Earth Mover’s Distance. Our goal is to calculate the distance that a word embedding needs to travel to reach the word embedding of the other word embedding. Now, when we talk about sentences, we need to calculate the distance of each word in one sentence to every other word in another sentence.
If the distance travel is minimum this means that words are closer and hence they are similar, and if this travel distance is high then we can conclude that the sentences are not similar.
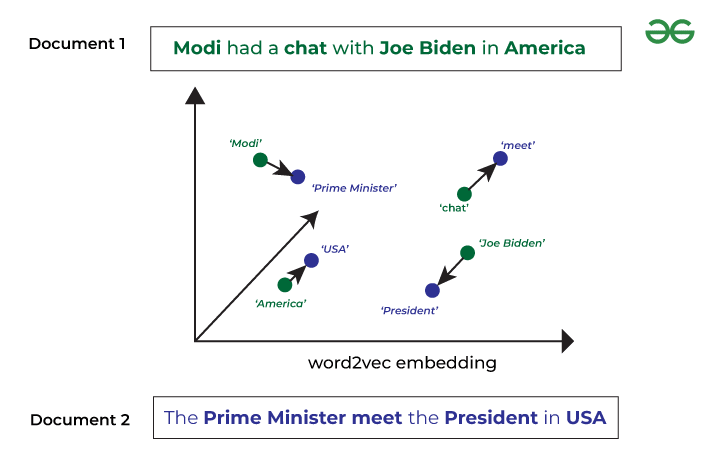
Word Mover’s Distance
For implementation, we can use the Gensim. In this article, we will use pre-trained embeddings. So let’s take a look at how to implement word mover’s distance for text similarity.
Importing NLTK and Cleaning the Text
1. Importing Libraries: In this first step, we will import the nltk library and from it, we will import stopwords and lemmatizer.
Python
from nltk.corpus import stopwords
from nltk import download
import nltk
nltk.download('all')
from nltk.stem import WordNetLemmatizer
|
2. Text Cleaning: Now, let’s write a function to clean the text, i.e. remove the stop words and lemmatize the words in the sentences.
Python3
download('stopwords')
stopwords = stopwords.words('english')
lemmatizer = WordNetLemmatizer()
def preprocess(sentences):
new_sentences = []
for sent in sentences:
sent = [lemmatizer.lemmatize(w) for w in sent.lower().split() if w not in stopwords]
new_sentences.append(sent)
return new_sentences
|
Downloading the pre-trained word embeddings
Now, let’s download the pre-trained word embeddings using the Gensim library. Gensim provides an excellent library to implement word mover’s distance techniques on word embeddings.
Python
import gensim.downloader as api
model = api.load('word2vec-google-news-300')
|
Calculating Text Similarity
Let’s preprocess the sentences, i.e. clean the text using the function written above.
Python
sentences = ["Rainbow has seven colors",
"There is a rainbow outside"]
sentences = preprocess(sentences)
print(sentences)
|
Output:
[['rainbow', 'seven', 'color'], ['rainbow', 'outside']]
Now that we have preprocessed the textual data, let’s calculate the distance between the sentences.
Python
distance = model.wmdistance(sentences[0], sentences[1])
print('distance = %.4f' % distance)
|
Output:
distance = 0.8465
Now, let’s do the same process but with sentences that are not at all related to each other.
Python
sentences = ["Rainbow has seven colors",
"An apple a day keeps the doctor away"]
sentences = preprocess(sentences)
distance = model.wmdistance(sentences[0], sentences[1])
print('distance = %.4f' % distance)
|
Output:
distance = 1.3022
Hence, we can conclude from the distance which is very large as compared to the previous distance calculated. Thus, these sentences are not similar.
Let’s take one more example, to see how much the distance is when the sentences are almost similar.
Python
sentences = ["This box contains seven colors",
"This box contains six colors"]
sentences = preprocess(sentences)
distance = model.wmdistance(sentences[0], sentences[1])
print('distance = %.4f' % distance)
|
distance = 0.1029
Here, we saw that the distance is very less and hence the sentences are similar with some modifications.
Conclusion
In this article, we learned about Word Mover’s Distance. We used it to calculate the distance between two sentences to conclude whether the sentences are similar or dissimilar. We used the Gensim library and used pre-trained word embeddings for calculating the distances.
Share your thoughts in the comments
Please Login to comment...