Collocations are two or more words that tend to appear frequently together, for example – United States. There are many other words that can come after United, such as the United Kingdom and United Airlines. As with many aspects of natural language processing, context is very important. And for collocations, context is everything. In the case of collocations, the context will be a document in the form of a list of words. Discovering collocations in this list of words means to find common phrases that occur frequently throughout the text. 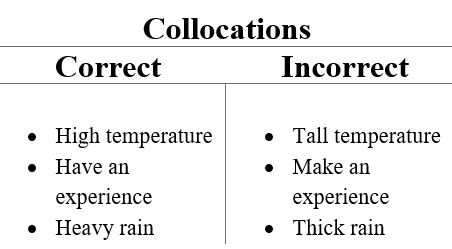 Link to DATA – Monty Python and the Holy Grail script Code #1 : Loading Libraries
Link to DATA – Monty Python and the Holy Grail script Code #1 : Loading Libraries
Python3
from nltk.corpus import webtext
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
|
Code #2 : Let’s find the collocations
Python3
words = [w.lower() for w in webtext.words(
'C:\\Geeksforgeeks\\python_and_grail.txt')]
biagram_collocation = BigramCollocationFinder.from_words(words)
biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
|
Output :
[("'", 's'),
('arthur', ':'),
('#', '1'),
("'", 't'),
('villager', '#'),
('#', '2'),
(']', '['),
('1', ':'),
('oh', ', '),
('black', 'knight'),
('ha', 'ha'),
(':', 'oh'),
("'", 're'),
('galahad', ':'),
('well', ', ')]
As we can see in the code above finding collocations in this way is not very useful. So, the code below is a refined version by adding a word filter to remove punctuation and stopwords. Code #3 :
Python3
from nltk.corpus import stopwords
stopset = set(stopwords.words('english'))
filter_stops = lambda w: len(w) < 3 or w in stopset
biagram_collocation.apply_word_filter(filter_stops)
biagram_collocation.nbest(BigramAssocMeasures.likelihood_ratio, 15)
|
Output :
[('black', 'knight'),
('clop', 'clop'),
('head', 'knight'),
('mumble', 'mumble'),
('squeak', 'squeak'),
('saw', 'saw'),
('holy', 'grail'),
('run', 'away'),
('french', 'guard'),
('cartoon', 'character'),
('iesu', 'domine'),
('pie', 'iesu'),
('round', 'table'),
('sir', 'robin'),
('clap', 'clap')]
How it works in the code?
- BigramCollocationFinder constructs two frequency distributions:
- one for each word
- another for bigrams.
- A frequency distribution is basically an enhanced Python dictionary where the keys are what’s being counted, and the values are the counts.
- Any filtering functions reduces the size by eliminating any words that don’t pass the filter
- Using a filtering function to eliminate all words that are one or two characters, and all English stopwords, results in a much cleaner result.
- After filtering, the collocation finder is ready for finding collocations.
Code #4 : Working on triplets instead of pairs.
Python3
from nltk.collocations import TrigramCollocationFinder
from nltk.metrics import TrigramAssocMeasures
words = [w.lower() for w in webtext.words(
'C:\Geeksforgeeks\\python_and_grail.txt')]
trigram_collocation = TrigramCollocationFinder.from_words(words)
trigram_collocation.apply_word_filter(filter_stops)
trigram_collocation.apply_freq_filter(3)
trigram_collocation.nbest(TrigramAssocMeasures.likelihood_ratio, 15)
|
Output :
[('clop', 'clop', 'clop'),
('mumble', 'mumble', 'mumble'),
('squeak', 'squeak', 'squeak'),
('saw', 'saw', 'saw'),
('pie', 'iesu', 'domine'),
('clap', 'clap', 'clap'),
('dona', 'eis', 'requiem'),
('brave', 'sir', 'robin'),
('heh', 'heh', 'heh'),
('king', 'arthur', 'music'),
('hee', 'hee', 'hee'),
('holy', 'hand', 'grenade'),
('boom', 'boom', 'boom'),
('...', 'dona', 'eis'),
('already', 'got', 'one')]
Share your thoughts in the comments
Please Login to comment...