Word Embedding using Word2Vec
Last Updated :
03 Jan, 2024
In this article, we are going to see Pre-trained Word embedding using Word2Vec in NLP models using Python.
What is Word Embedding?
Word Embedding is a language modeling technique for mapping words to vectors of real numbers. It represents words or phrases in vector space with several dimensions. Word embeddings can be generated using various methods like neural networks, co-occurrence matrices, probabilistic models, etc. Word2Vec consists of models for generating word embedding. These models are shallow two-layer neural networks having one input layer, one hidden layer, and one output layer.
What is Word2Vec?
Word2Vec is a widely used method in natural language processing (NLP) that allows words to be represented as vectors in a continuous vector space. Word2Vec is an effort to map words to high-dimensional vectors to capture the semantic relationships between words, developed by researchers at Google. Words with similar meanings should have similar vector representations, according to the main principle of Word2Vec. Word2Vec utilizes two architectures:
- CBOW (Continuous Bag of Words): The CBOW model predicts the current word given context words within a specific window. The input layer contains the context words and the output layer contains the current word. The hidden layer contains the dimensions we want to represent the current word present at the output layer.
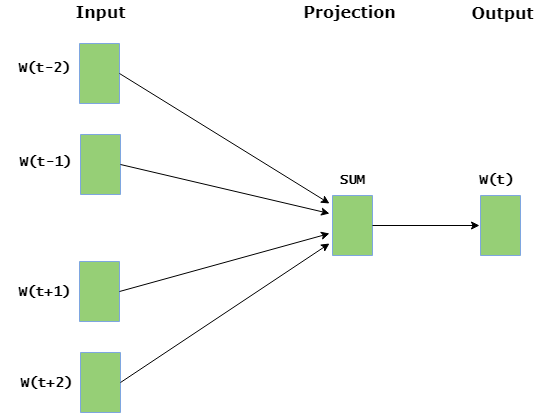
- Skip Gram : Skip gram predicts the surrounding context words within specific window given current word. The input layer contains the current word and the output layer contains the context words. The hidden layer contains the number of dimensions in which we want to represent current word present at the input layer.
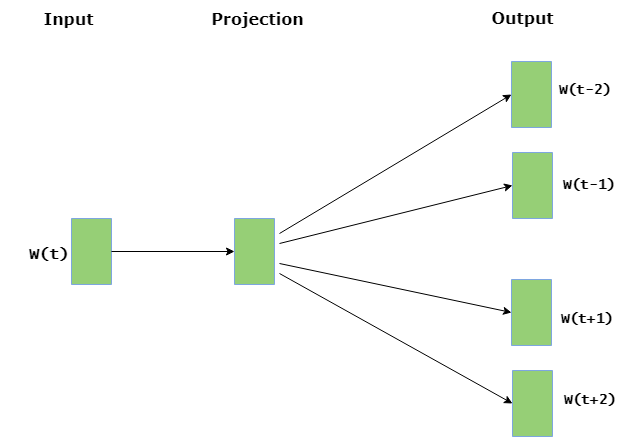
The basic idea of word embedding is words that occur in similar context tend to be closer to each other in vector space. For generating word vectors in Python, modules needed are nltk and gensim. Run these commands in terminal to install nltk and gensim:
pip install nltk
pip install gensim
- NLTK: For handling human language data, NLTK, or Natural Language Toolkit, is a potent Python library. It offers user-friendly interfaces to more than 50 lexical resources and corpora, including WordNet. A collection of text processing libraries for tasks like categorization, tokenization, stemming, tagging, parsing, and semantic reasoning are also included with NLTK.
- GENSIM: Gensim is an open-source Python library that uses topic modelling and document similarity modelling to manage and analyse massive amounts of unstructured text data. It is especially well-known for applying topic and vector space modelling algorithms, such as Word2Vec and Latent Dirichlet Allocation (LDA), which are widely used.
Why we need Word2Vec?
In natural language processing (NLP), Word2Vec is a popular and significant method for representing words as vectors in a continuous vector space. Word2Vec has become popular and is utilized in many different NLP applications for several reasons:
- Semantic Representations: Word2Vec records the connections between words semantically. Words are represented in the vector space so that similar words are near to one another. This enables the model to interpret words according to their context within a particular corpus.
- Distributional Semantics: The foundation of Word2Vec is the distributional hypothesis, which holds that words with similar meanings are more likely to occur in similar contexts. Word2Vec generates vector representations that reflect semantic similarities by learning from the distributional patterns of words in a large corpus.
- Vector Arithmetic: Word2Vec generates vector representations that have intriguing algebraic characteristics. Vector arithmetic, for instance, can be used to record word relationships. One well-known example is that the vector representation of “queen” could resemble the vector representation of “king” less “man” plus “woman.”
- Efficiency: Word2Vec’s high computational efficiency makes training on big datasets possible. Learning high-dimensional vector representations for a large vocabulary requires this efficiency.
- Transfer Learning: A variety of natural language processing tasks can be initiated with pre-trained Word2Vec models. Time and resources can be saved by fine-tuning the embeddings discovered on a sizable dataset for particular uses.
- Applications: Word2Vec embeddings have shown promise in a number of natural language processing (NLP) applications, such as machine translation, text classification, sentiment analysis, and information retrieval. These applications are successful in part because of their capacity to capture semantic relationships.
- Scalability: Word2Vec can handle big corpora with ease and is scalable. Scalability like this is essential for training on large text datasets.
- Open Source Implementations: Word2Vec has open-source versions, including one that is included in the Gensim library. Its widespread adoption and use in both research and industry can be attributed in part to its accessibility.
Word2Vec Code Implementation
Download the text file used for generating word vectors from here . Below is the implementation:
This code illustrates how to train the CBOW and Skip-Gram Word2Vec models on a given text file and shows how to use the trained models to compute the cosine similarity between particular word pairs. The models ability to understand the semantic relationships between words may vary depending on whether CBOW or Skip-Gram is used.
Python
from gensim.models import Word2Vec
import gensim
from nltk.tokenize import sent_tokenize, word_tokenize
import warnings
warnings.filterwarnings(action='ignore')
sample = open("C:\\Users\\Admin\\Desktop\\alice.txt")
s = sample.read()
f = s.replace("\n", " ")
data = []
for i in sent_tokenize(f):
temp = []
for j in word_tokenize(i):
temp.append(j.lower())
data.append(temp)
model1 = gensim.models.Word2Vec(data, min_count=1,
vector_size=100, window=5)
print("Cosine similarity between 'alice' " +
"and 'wonderland' - CBOW : ",
model1.wv.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " +
"and 'machines' - CBOW : ",
model1.wv.similarity('alice', 'machines'))
model2 = gensim.models.Word2Vec(data, min_count=1, vector_size=100,
window=5, sg=1)
print("Cosine similarity between 'alice' " +
"and 'wonderland' - Skip Gram : ",
model2.wv.similarity('alice', 'wonderland'))
print("Cosine similarity between 'alice' " +
"and 'machines' - Skip Gram : ",
model2.wv.similarity('alice', 'machines'))
|
Output :
Cosine similarity between 'alice' and 'wonderland' - CBOW : 0.999249298413
Cosine similarity between 'alice' and 'machines' - CBOW : 0.974911910445
Cosine similarity between 'alice' and 'wonderland' - Skip Gram : 0.885471373104
Cosine similarity between 'alice' and 'machines' - Skip Gram : 0.856892599521
Output indicates the cosine similarities between word vectors ‘alice’, ‘wonderland’ and ‘machines’ for different models. One interesting task might be to change the parameter values of ‘size’ and ‘window’ to observe the variations in the cosine similarities.
Applications of Word Embedding:
- Text classification: Using word embeddings to increase the precision of tasks such as topic categorization and sentiment analysis.
- Named Entity Recognition (NER): Using word embeddings semantic context to improve the identification of entities (such as names and locations).
- Information Retrieval: To provide more precise search results, embeddings are used to index and retrieve documents based on semantic similarity.
- Machine Translation: The process of comprehending and translating the semantic relationships between words in various languages by using word embeddings.
- Question Answering: Increasing response accuracy and understanding of semantic context in Q&A systems.
Frequently Asked Quetions (FAQs)
Q.1 What is Word2Vec and how does it work?
Words can be represented as vectors in a continuous space using the Word2Vec technique. To operate, it must first learn vector representations of semantic relationships based on the distributional hypothesis, which states that words with comparable meanings occur in contexts that are similar across a corpus.
Q. 2 Describe the differences between Word2Vec’s CBOW and Skip-Gram architectures.
Skip-Gram predicts context words from a target word, and CBOW predicts a target word based on its context. While Skip-Gram frequently performs better for infrequent words, CBOW is faster and typically performs better with frequent words.
Q. 3 How are word embeddings trained using Word2Vec?
Using a large corpus, word embeddings are trained by modifying vector representations in response to how well the model predicts target or context words.
Q. 4 What is Cosine Similarity?
The similarity between two vectors in an inner product space is measured by cosine similarity. It finds whether two vectors are roughly pointing in the same direction by measuring the cosine of the angle between them. In text analysis, it is frequently used to gauge document similarity.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...