Text Mining in Data Mining
Last Updated :
31 Jan, 2024
In this article, we will learn about the main process or we should say the basic building block of any NLP-related tasks starting from this stage of basically Text Mining.
What is Text Mining?
Text mining is a component of data mining that deals specifically with unstructured text data. It involves the use of natural language processing (NLP) techniques to extract useful information and insights from large amounts of unstructured text data. Text mining can be used as a preprocessing step for data mining or as a standalone process for specific tasks.
Text Mining in Data Mining?
Text mining in data mining is mostly used for, the unstructured text data that can be transformed into structured data that can be used for data mining tasks such as classification, clustering, and association rule mining. This allows organizations to gain insights from a wide range of data sources, such as customer feedback, social media posts, and news articles.
Text Mining vs. Text Analytics
Text mining and text analytics are related but distinct processes for extracting insights from textual data. Text mining involves the application of natural language processing and machine learning techniques to discover patterns, trends, and knowledge from large volumes of unstructured text.
However, Text Analytics focuses on extracting meaningful information, sentiments, and context from text, often using statistical and linguistic methods. While text mining emphasizes uncovering hidden patterns, text analytics emphasizes deriving actionable insights for decision-making. Both play crucial roles in transforming unstructured text into valuable knowledge, with text mining exploring patterns and text analytics providing interpretative context.
Why is Text Mining Important?
Text mining is widely used in various fields, such as natural language processing, information retrieval, and social media analysis. It has become an essential tool for organizations to extract insights from unstructured text data and make data-driven decisions.
“Extraction of interesting information or patterns from data in large databases is known as data mining.”
Text mining is a process of extracting useful information and nontrivial patterns from a large volume of text databases. There exist various strategies and devices to mine the text and find important data for the prediction and decision-making process. The selection of the right and accurate text mining procedure helps to enhance the speed and the time complexity also. This article briefly discusses and analyzes text mining and its applications in diverse fields.
As we discussed above, the size of information is expanding at exponential rates. Today all institutes, companies, different organizations, and business ventures are stored their information electronically. A huge collection of data is available on the internet and stored in digital libraries, database repositories, and other textual data like websites, blogs, social media networks, and e-mails. It is a difficult task to determine appropriate patterns and trends to extract knowledge from this large volume of data. Text mining is a part of Data mining to extract valuable text information from a text database repository. Text mining is a multi-disciplinary field based on data recovery, Data mining, AI,statistics, Machine learning, and computational linguistics.
Text Mining Process
Conventional Process of Text Mining
- Gathering unstructured information from various sources accessible in various document organizations, for example, plain text, web pages, PDF records, etc.
- Pre-processing and data cleansing tasks are performed to distinguish and eliminate inconsistency in the data. The data cleansing process makes sure to capture the genuine text, and it is performed to eliminate stop words stemming (the process of identifying the root of a certain word and indexing the data.
- Processing and controlling tasks are applied to review and further clean the data set.
- Pattern analysis is implemented in Management Information System.
- Information processed in the above steps is utilized to extract important and applicable data for a powerful and convenient decision-making process and trend analysis.
Common Methods for Analyzing Text Mining
- Text Summarization: To extract its partial content and reflect its whole content automatically.
- Text Categorization: To assign a category to the text among categories predefined by users.
- Text Clustering: To segment texts into several clusters, depending on the substantial relevance.
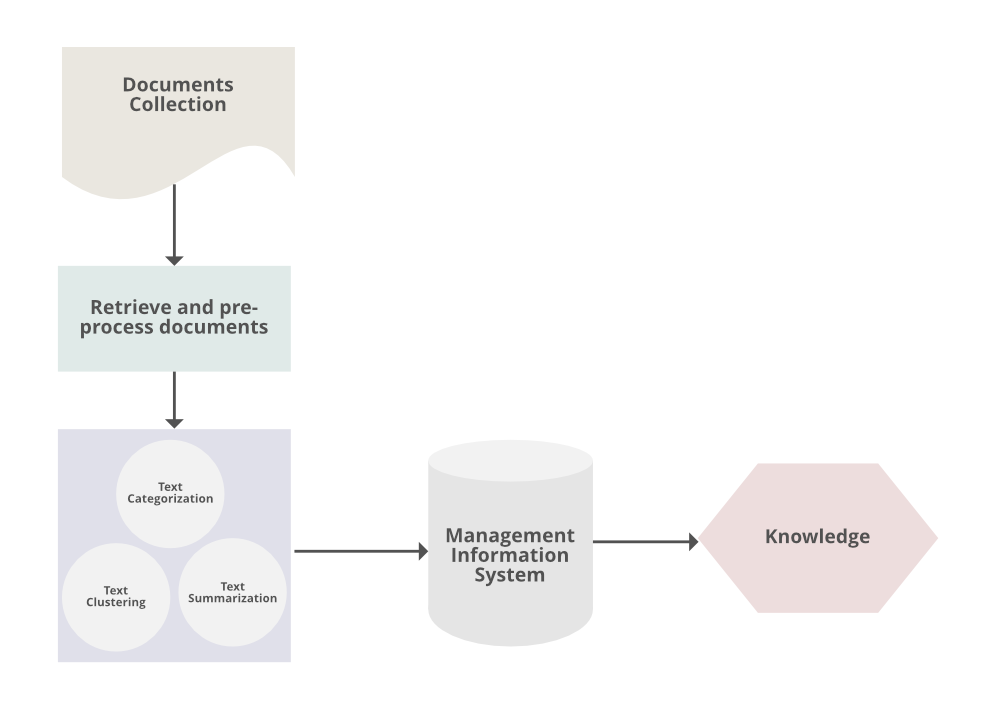
Procedures for Analyzing Text Mining
Text Mining Techniques
Information Retrieval
In the process of Information retrieval, we try to process the available documents and the text data into a structured form so, that we can apply different pattern recognition and analytical processes. It is a process of extracting relevant and associated patterns according to a given set of words or text documents.
For this, we have processes like Tokenization of the document or the stemming process in which we try to extract the base word or let’s say the root word present there.
Information Extraction
It is a process of extracting meaningful words from documents.
- Feature Extraction – In this process, we try to develop some new features from existing ones. This objective can be achieved by parsing an existing feature or combining two or more features based on some mathematical operation.
- Feature Selection – In this process, we try to reduce the dimensionality of the dataset which is generally a common issue while dealing with the text data by selecting a subset of features from the whole dataset.
Natural Language Processing
Natural Language Processing includes tasks that are accomplished by using Machine Learning and Deep Learning methodologies. It concerns the automatic processing and analysis of unstructured text information.
- Named Entity Recognition (NER): Identifying and classifying named entities such as people, organizations, and locations in text data.
- Sentiment Analysis: Identifying and extracting the sentiment (e.g. positive, negative, neutral) of text data.
- Text Summarization: Creating a condensed version of a text document that captures the main points.
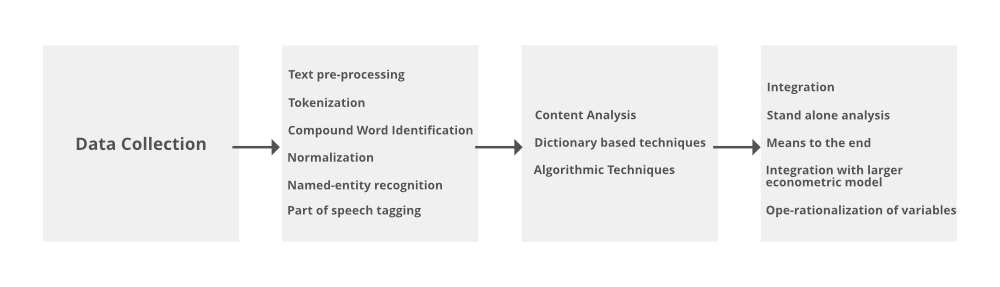
Overview of Text Mining Techniques
| Text Preprocessing phase |
Tokenization |
How can transform a text into words or text format? |
Transferring strings into a single textual token. |
White space separation. |
| Compound word identification |
How can I identify words that have a joint meaning? |
Identifying words with a joint meaning that gets lost word |
n-grams |
| Normalization and noise reduction |
How can I cope with too many variables in my Document‐Term‐Matrix? |
Reducing the dimensionality of Document‐Term‐Matrix |
Stemming, Lemmatization, Deletion of stop words. infrequent term. |
| Linguistic analysis |
How can I identify words with a special meaning or grammatical function? |
Tagging of words |
Named‐entity recognition, Part‐of‐speech tagging |
| Content Analysis |
Dictionary‐based |
How can I identify how latent sociological or psychological traits and states are reflected in natural language? |
Measuring contextual, psychological, linguistic, or semantic concepts and constructs |
Pre‐defined dictionaries and Customized dictionaries |
| Algorithmic techniques |
How can I assign texts to predefined classes? |
Classifying textual entities into predefined categories |
Supervised learning techniques such as binary or multi‐class classifiers |
| Algorithmic techniques |
How can I group similar documents? |
Clustering of textual entities into formerly undefined and unknown |
Unsupervised learning techniques such as LDA, k‐means, or non‐negative |
Text Mining Applications
- Digital Library: Various text mining strategies and tools are being used to get the pattern and trends from journal and proceedings which is stored in text database repositories. These resources of information help in the field of research area. Libraries are a good resource for text data in digital form. It gives a novel technique for getting useful data in such a way that makes it conceivable to access millions of records online.
A green-stone international digital library that supports numerous languages and multilingual interfaces gives a springy method for extracting reports that handle various formats, i.e. Microsoft Word, PDF, postscript, HTML, scripting languages, and email. It additionally supports the extraction of audiovisual and image formats along with text documents. Text Mining processes perform different activities like document collection, determination, enhancement, removing data, and handling substances, and Producing summarization.
- Academic and Research Field: In the education field, different text-mining tools and strategies are utilized to examine the instructive patterns in a specific region/research field. The main purpose of text mining utilization in the research field is help to discover and arrange research papers and relevant material from various fields on one platform.
For this, we use k-Means clustering and different strategies help to distinguish the properties of significant data. Also, student performance in various subjects can be accessed, and how various qualities impact the selection of subjects evaluated by this mining.
- Life Science: Life science and healthcare industries are producing an enormous volume of textual and mathematical data regarding patient records, sicknesses, medicines, symptoms, and treatments of diseases, etc. It is a major issue to filter data and relevant text to make decisions from a biological data repository. The clinical records contain variable data which is unpredictable, and lengthy. Text mining can help to manage such kinds of data. Text mining is used in biomarkers disclosure, the pharmacy industry, clinical trade analysis examination, clinical study, and patent competitive intelligence also.
- Social-Media: Text mining is accessible for dissecting and analyzing web-based media applications to monitor and investigate online content like the plain text from internet news, web journals, emails, blogs, etc. Text mining devices help to distinguish and investigate the number of posts, likes, and followers on the web-based media network. This kind of analysis shows individuals’ responses to various posts, and news and how it spread around. It shows the behavior of people who belong to a specific age group and variations in views about the same post.
- Business Intelligence: Text mining plays an important role in business intelligence that help different organization and enterprises to analyze their customers and competitors to make better decisions. It gives an accurate understanding of business and gives data on how to improve consumer satisfaction and gain competitive benefits. The text mining devices like IBM text analytics.
This mining can be used in the telecom sector, commerce, and customer chain management system.
Advantages of Text Mining
- Large Amounts of Data: Text mining allows organizations to extract insights from large amounts of unstructured text data.
- Variety of Applications: Text mining has a wide range of applications, including sentiment analysis, named entity recognition, and topic modeling.
- Improved Decision Making
- Cost-effective: Text mining can be a cost-effective way, as it eliminates the need for manual data entry.
Disadvantages of Text Mining
- Complexity: Text mining can be a complex process requiring advanced skills in natural language processing and machine learning.
- Quality of Data: The quality of text data can vary, affecting the accuracy of the insights extracted from text mining.
- High Computational Cost: Text mining requires high computational resources, and it may be difficult for smaller organizations to afford the technology.
- Limited to Text Data: Text mining is limited to extracting insights from unstructured text data and cannot be used with other data types.
- Noise in text mining results: Text mining of documents may result in mistakes. It’s possible to find false links or to miss others. In most situations, if the noise (error rate) is sufficiently low, the benefits of automation exceed the chance of a larger mistake than that produced by a human reader.
- Lack of transparency: Text mining is frequently viewed as a mysterious process where large corpora of text documents are input and new information is produced. Text mining is in fact opaque when researchers lack the technical know-how or expertise to comprehend how it operates, or when they lack access to corpora or text mining tools.
Conclusion
Text mining extracts valuable insights from unstructured text, aiding decision-making across diverse fields. Despite challenges, its applications in academia, healthcare, business, and more demonstrate its significance in converting textual data into actionable knowledge.
Text Mining- FAQs
What is text mining with example?
Text mining is extracting insights from text. Example: analyzing customer reviews to identify sentiments and preferences.
What is NLP and text mining?
NLP is Natural Language Processing, and text mining is using NLP techniques to analyze unstructured text data for insights.
Who uses text mining?
Industries such as healthcare, business, academia, and social media utilize text mining for data-driven decision-making.
What is text mining in Python?
Text mining in Python involves using libraries like NLTK or spaCy for natural language processing tasks.
Why is text mining used?
Text mining is used to extract insights from unstructured text data, aiding decision-making and providing valuable knowledge across various domains.
Share your thoughts in the comments
Please Login to comment...